By Group "Sarcastic Arbitrage"
Codes and Blogs By [Yang Zhifu], [Qian Borui], [Tian Gesi], [Gao Jie], and [Li Yalun]. This is our Second Blog post detailing our NLP methodology, data cleaning process, and initial statistical results.
1. Introduction
Our team, Sarcastic Arbitrage, focuses on exploring the relationship between sentiment within the Reddit community and silver price movements.
In our first blog post, we used a "RSS subscription + precision filtering" method to get relevant posts and comments from prominent subreddits including r/PreciousMetals and r/Wallstreetsilver. This was in reaction to Reddit's 2025 policy change, which closed self-service API access. We also got three months' worth of silver pricing data from Capital IQ, which we used as a starting point for further study.
In this blog, we go into more detail about the next steps in the process: 1. Data Cleaning: Getting rid of special characters, standardizing formats, and removing stop words. 2. NLP Tool Comparison: We looked at three natural language processing (NLP) sentiment analysis tools (NLTK/VADER, FinBERT, and LLM like Qwen-Max) and compared them based on their core types, workflows, strengths, and weaknesses. 3. Statistical Results: We show results that come from comparing emotion scores with the logarithmic returns of silver prices.
2. Data Cleaning
To clean and gather the data, we imported Python libraries like pandas and nltk. Since our team is focusing on the sentiment of comments on social media (Reddit), the comments we scraped are usually quite different from financial news or reports, requiring deep cleaning.
2.1. General Cleaning (Used for FinBERT & LLM)
For deep learning models like FinBERT and LLMs, we need to remove noise (like HTML tags and markdown) while preserving sentence structure and emojis, which often carry sentiment.
import re
import html
def clean_reddit_text(text):
"""
Deep cleaning of Reddit comment text for FinBERT/LLM
"""
if not isinstance(text, str):
return ""
# 1. HTML entity decoding
text = html.unescape(text)
# 2. Remove URLs and Reddit-specific markers
text = re.sub(r'http\S+|www\.\S+', '', text)
text = re.sub(r'/u/\w+|/r/\w+', '', text)
# 3. Remove markdown formatting symbols (keep necessary punctuation)
text = re.sub(r'\*\*|\*|~~|`', '', text)
# 4. Normalize whitespace
text = re.sub(r'\s+', ' ', text).strip()
return text
2.2. Stop Words Removal (Specific to NLTK)
For the bag-of-words approach used in NLTK (and for generating WordClouds), we perform an extra step: removing "stop words" (common words like "the", "is", "at") that do not carry sentiment value.
import nltk
from nltk.corpus import stopwords
# Download stop words list
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
# Remove stop words from text
# 'text' is the column containing the lowercase comment
comment_data['text_clean'] = (comment_data['text']
.apply(lambda x: ' '.join([word for word in x.split() if word not in stop_words])))
3. Methodology: Why These 3 NLP Tools?
As introduced, we adopted NLTK, FinBERT, and LLM for our sentiment analysis. We didn’t pick these tools at random—they represent the three core paradigms of NLP sentiment analysis: rule-based, domain-specialized, and general-purpose LLMs.
Together, they cover our full workflow: from fast bulk screening to precise financial analysis and deep contextual interpretation. This layered approach ensures we never compromise on speed, accuracy, or nuance.
3.1. NLTK (VADER): The Speed Demon for Bulk Screening
VADER is a battle-tested rule-based lexicon tool built specifically for social media text. For our first step—sifting through tens of thousands of Reddit comments to separate signal from noise—it’s unbeatable. It acts as the “workhorse” that lets us quickly filter out low-value, neutral comments.
Key Strengths: * Blazing fast throughput: Processes 10,000+ comments in seconds—critical for handling Reddit’s high-volume discussions. * Zero cost & zero setup: No training data or specialized hardware required; it works out of the box with a pre-built sentiment lexicon. * Intuitive output: Generates a compound score (-1 = extremely negative, 1 = extremely positive) plus clear positive/negative/neutral labels.
Implementation Snippet: Below is the core logic for initializing VADER and scoring a comment. It calculates a "compound" score which normalizes the sum of lexical ratings.
from nltk.sentiment.vader import SentimentIntensityAnalyzer
# Initialize the VADER sentiment analyzer
sid = SentimentIntensityAnalyzer()
# Example comment
comment = "Silver to the moon! 🚀 Great time to buy."
# Obtain sentiment scores
scores = sid.polarity_scores(comment)
# Output: {'neg': 0.0, 'neu': 0.58, 'pos': 0.42, 'compound': 0.6588}
print(f"Sentiment Score: {scores['compound']}")
Critical Limitations: * Financial jargon blind: Relies on a general social media lexicon, so it can’t recognize terms like “SLV,” “ETF,” or “ounce.” * Fails at sarcasm & complex logic: Completely misses Reddit-style irony (e.g., “Great, silver crashed again!”).
Best For: Rapid initial screening of large datasets to filter out neutral comments.
3.2. FinBERT: The Financial Expert for Precision Analysis
Reddit’s silver discussions are packed with financial jargon like “SLV,” “ETF,” and “Fed rate hike.” Generic models flounder here, but FinBERT is a pre-trained BERT model fine-tuned on financial corpora (earnings calls, analyst reports). It “speaks the language” of traders.
Key Strengths: * Unmatched financial accuracy: Outperforms generic models on terms like “bearish,” “rally,” and “stacking.” * Interpretable outputs: Provides probabilities for positive/negative/neutral labels, showing model confidence. * Efficient batch processing: Handles hundreds of comments at once, balancing speed and precision.
Implementation Snippet:
We utilize the Hugging Face transformers pipeline to load the ProsusAI/finbert model. The following code demonstrates how we initialize the model and process a batch of text to get probability distributions.
from transformers import pipeline
# Initialize FinBERT model pipeline
classifier = pipeline(
"sentiment-analysis",
model="ProsusAI/finbert",
top_k=None # Return probabilities for all classes (positive, negative, neutral)
)
# Example batch of comments
batch = [
"Silver is going to crash, I'm losing money.",
"Long term fundamentals look strong for precious metals."
]
# Run inference
results = classifier(batch, truncation=True, max_length=512)
# Process results to get the dominant label and score
for res in results:
scores_dict = {item['label']: item['score'] for item in res}
print(f"Scores: {scores_dict}")
Critical Limitations: * Narrow domain focus: Struggles with non-financial slang or casual Reddit banter. * No context for irony: Still can’t parse sarcasm or counterfactual statements.
Best For: Precision-focused analysis of professional financial discussions.
3.3. LLM (e.g., Qwen-Max): The Context Detective for Nuanced Insights
Reddit’s silver threads are full of slang (“apes,” “stacking”), sarcasm, and implicit market expectations. LLMs excel at understanding human-like language—they’re the only option for digging into unspoken sentiment.
Key Strengths: * Slang & sarcasm decoder: Recognizes Reddit-specific lingo and ironic tone. * Structured, explainable outputs: With prompt engineering, we get structured JSON with sentiment labels and judgment rationales. * Universal adaptability: Handles almost any natural language edge case.
Prompt Engineering Strategy:
To ensure the LLM acts as a professional analyst rather than a generic chatbot, we employed a Structured Prompting strategy. We deliberately wrote the system prompt in Markdown format.
Why Markdown?
LLMs are heavily trained on code documentation and technical papers. Markdown syntax (like headers ## and bullet points -) provides a clear logical hierarchy that the model understands natively. It helps the model distinguish between high-level instructions (Task) and specific constraints (Rules), reducing hallucination.
Prompt Structure: Our prompt follows a strict "Funnel Structure": 1. Role Definition: Establishes the persona (Financial Market Analyst). 2. Task Description: Defines the core objective clearly. 3. Detailed Rules: Provides granular scoring criteria (-1.0 to +1.0) and probability requirements. 4. Domain Adaptation: Explicitly maps Reddit slang (e.g., "diamond hands") to sentiment to bridge the cultural gap. 5. Output Constraints: Enforces a strict JSON format for programmatic parsing.
Below is the actual System Prompt we designed:
You are a professional financial market sentiment analyst specializing in analyzing discussions about precious metals (gold and silver) on social media platforms like Reddit.
## Task
Analyze the sentiment of user comments to determine their attitude toward precious metal price trends.
## Scoring Rules
### 1. Sentiment Classification (sentiment_label)
- **positive**: Bullish/Optimistic
- **negative**: Bearish/Pessimistic
- **neutral**: Neutral/Factual
### 2. Sentiment Intensity (sentiment_score)
Range: -1.0 to +1.0
- **+0.7 ~ +1.0**: Extremely bullish (e.g., "all in silver! 🚀🚀🚀")
- **-1.0 ~ -0.7**: Extremely bearish (e.g., "Run! It's going to crash!")
... (intermediate ranges omitted for brevity)
## Special Processing Rules
1. **Emojis**: 🚀💎🙌 = extremely bullish; 📉😭💔 = extremely bearish
2. **Reddit Slang**:
- "to the moon" / "stonks" → positive
- "diamond hands" → positive (holding firm)
- "paper hands" → negative (selling easily)
- "bag holder" → negative (stuck with losses)
## Output Format (Strict JSON)
{
"sentiment_label": "positive/negative/neutral",
"sentiment_score": 0.65,
"positive_prob": 0.75,
"negative_prob": 0.05,
"neutral_prob": 0.20,
"keywords": ["bullish", "buy", "moon", "🚀"],
"reason": "Brief explanation..."
}
Technical Optimization (Caching & Concurrency): Calling LLM APIs for thousands of comments is slow and expensive. To mitigate this, we implemented two key optimizations in our Python client:
- Context Caching: Our System Prompt is long and complex. By enabling caching on the system message, the API (Qwen-Max) processes the prompt once and reuses the "kv-cache" for subsequent requests. This significantly reduces token consumption and latency.
- Concurrency: We use a
ThreadPoolExecutorto send parallel requests, maximizing throughput without hitting API rate limits.
Below is the implementation code using the dashscope SDK:
import json
import dashscope
from http import HTTPStatus
from concurrent.futures import ThreadPoolExecutor, as_completed
# Configure API Key
dashscope.api_key = "YOUR_DASHSCOPE_API_KEY"
class SentimentAnalysisClient:
def __init__(self, system_prompt):
self.system_prompt = system_prompt
def analyze_single_comment(self, comment_text):
"""
Calls Qwen-Max with Context Caching enabled.
"""
messages = [
{
'role': 'system',
'content': self.system_prompt,
# Enable caching for the heavy system prompt
# Note: Check specific provider docs for exact cache syntax
'cache_control': {'type': 'ephemeral'}
},
{'role': 'user', 'content': comment_text}
]
try:
response = dashscope.Generation.call(
model='qwen-max',
messages=messages,
result_format='message',
temperature=0.2
)
if response.status_code == HTTPStatus.OK:
content_str = response.output.choices[0].message.content
# Clean code blocks if present
if "```json" in content_str:
content_str = content_str.replace("```json", "").replace("```", "")
return json.loads(content_str.strip())
else:
print(f"API Error: {response.code} - {response.message}")
return None
except Exception as e:
print(f"Parsing Error: {e}")
return None
def run_batch(self, comments_list, max_workers=5):
"""
Processes comments in parallel.
"""
results = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_comment = {
executor.submit(self.analyze_single_comment, c): c
for c in comments_list
}
for future in as_completed(future_to_comment):
data = future.result()
if data:
results.append(data)
return results
Critical Limitations: * High cost & slow speed: Even with caching, inference takes seconds per comment compared to milliseconds for VADER. * Prompt-dependent: Output quality hinges on well-designed prompts; a vague prompt leads to vague analysis. * API rate limits: We must respect the provider's QPS (Queries Per Second) limits to avoid blocking.
Best For: Where you need more than a score—you need an explanation of why the model assigned that sentiment.
4. Data Analysis and Preliminary Results
So far, we have assigned a sentiment score to each comment we got from Reddit. In one day, there can be more than one comment about silver price, while on some other days, there are simply one comment or no comment on this topic. On the other hand, we have the daily silver price data (ideally, a much better academic study can collect minute-level price data and line up the data along each minute). Therefore, we should pack-up the sentiment scores within one day into a single number.
Two straightforward methods were applied, one is taking average and another is simply sum-up — this gives the idea of Average daily sentiment and Cumulative daily sentiment score.
The plotted results of NLTK, BERT, and LLM in average (left) and cumulative (right) daily scores are as followed:
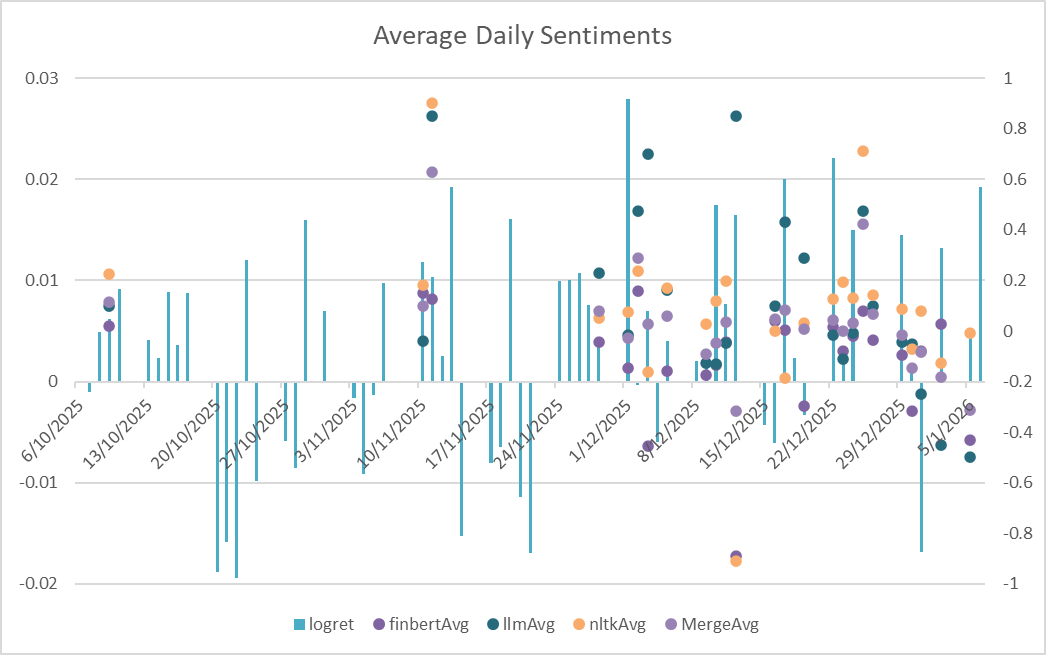
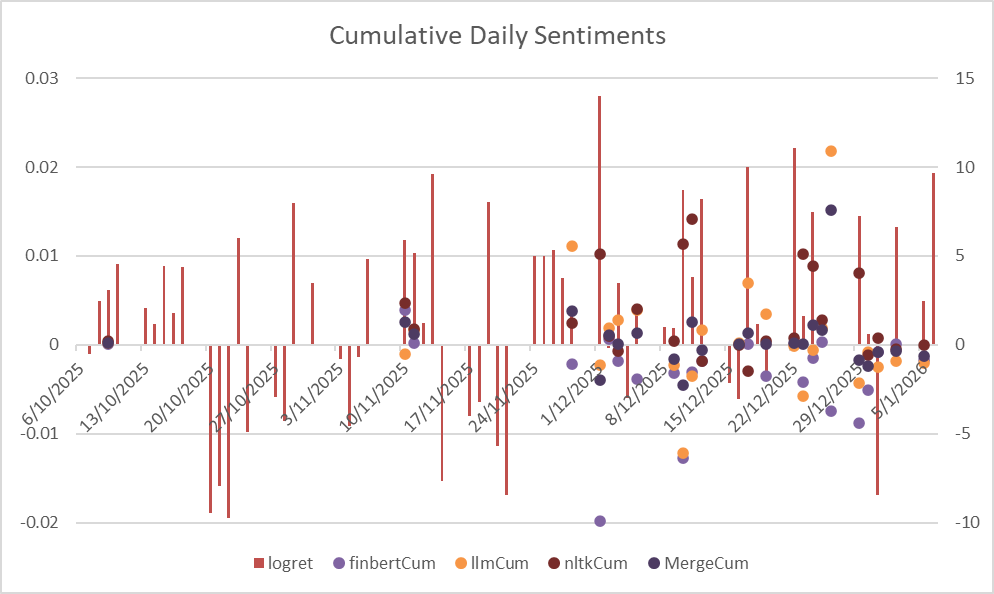
From the two plots, we could visibly observe that Average Daily Sentiments works better than the Cumulative ones. Though not always leading the price surge, it generally fluctuates the same as the log return.
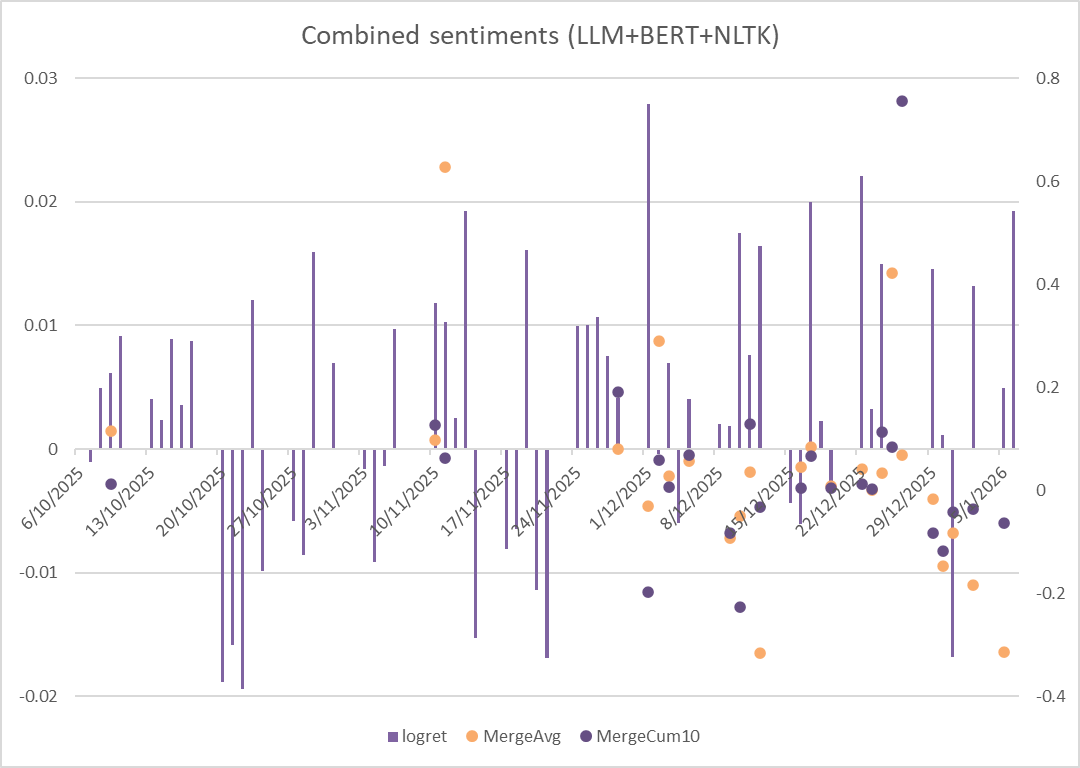
The MergeAvg and MergeCum refers to the arithmetic average of BERT, LLM and NLTK scores, which creates a combined score by three different NLP tools. The below plot shows clearly the performance of the merged sentiment scores — seems worse than the pure LLM.
Below is the combination between Merged and pure LLM Daily average scores:
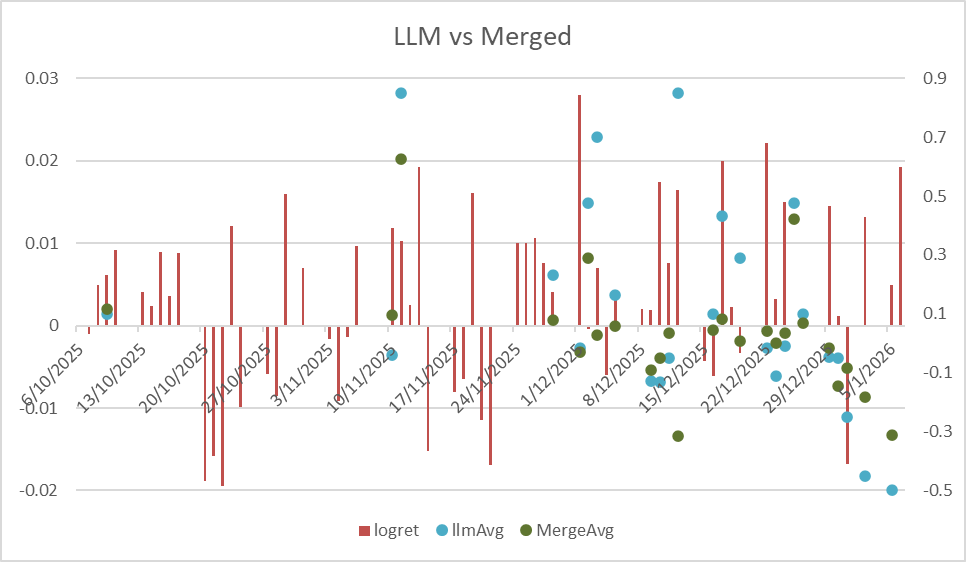
We can see, especially before January 2026, LLM scores successfully performed, sometimes (For example, between Nov 10 and Nov 17) can predict the price surge. On the other hand, at the beginning of January 2026, the price dived deeply and bounced back soon — however, the Reddit users’ emotions kept being negative and failed to predict the bounce.
5. Conclusion and Future Work
Our project has advanced research into the correlation between sentiment on Reddit and silver prices. Whilst the current association remains preliminary, our team has gained valuable technical, methodological, and practical experience throughout the research process – from data collection and cleansing to NLP sentiment analysis and statistical validation.
Concurrently, we have formulated future research directions and optimisation plans:
- Hybrid NLP Models: Advance the hybrid application of NLP models to combine the speed of VADER with the nuance of LLMs.
- Macroeconomic Data: Incorporate data such as inflation rates, interest rate changes, and industrial demand indicators into the research framework.
- Market Extension: Extend the current analytical framework to other precious metals (e.g., gold, platinum) and commodity markets (e.g., crude oil, copper).
This work contributes both to academic understanding of commodity markets and provides practical reference for investors.