By Group "Sarcastic Arbitrage "
Codes and Blogs By [Yang Zhifu], [Qian Borui], [Tian Gesi], [Gao Jie], and [Li Yalun]. This is our First Blog post outlining our project proposal and initial data collection progress.
1. Abstract
Silver is a precious metal valued for its exceptional electrical conductivity and is widely used in jewelry, coins, electronics, and photography. In recent months, the silver price has fluctuated dramatically, which has caused us to be curious about the relationship between public sentiment and silver price changes.
Our project aims to predict daily movements of silver prices by applying natural language processing (NLP) for sentiment analysis. Specifically, we plan to analyze posts and comments related to silver prices on social media (Reddit) over the past three months.
Below is a Sequence Diagram of our proposed workflow:
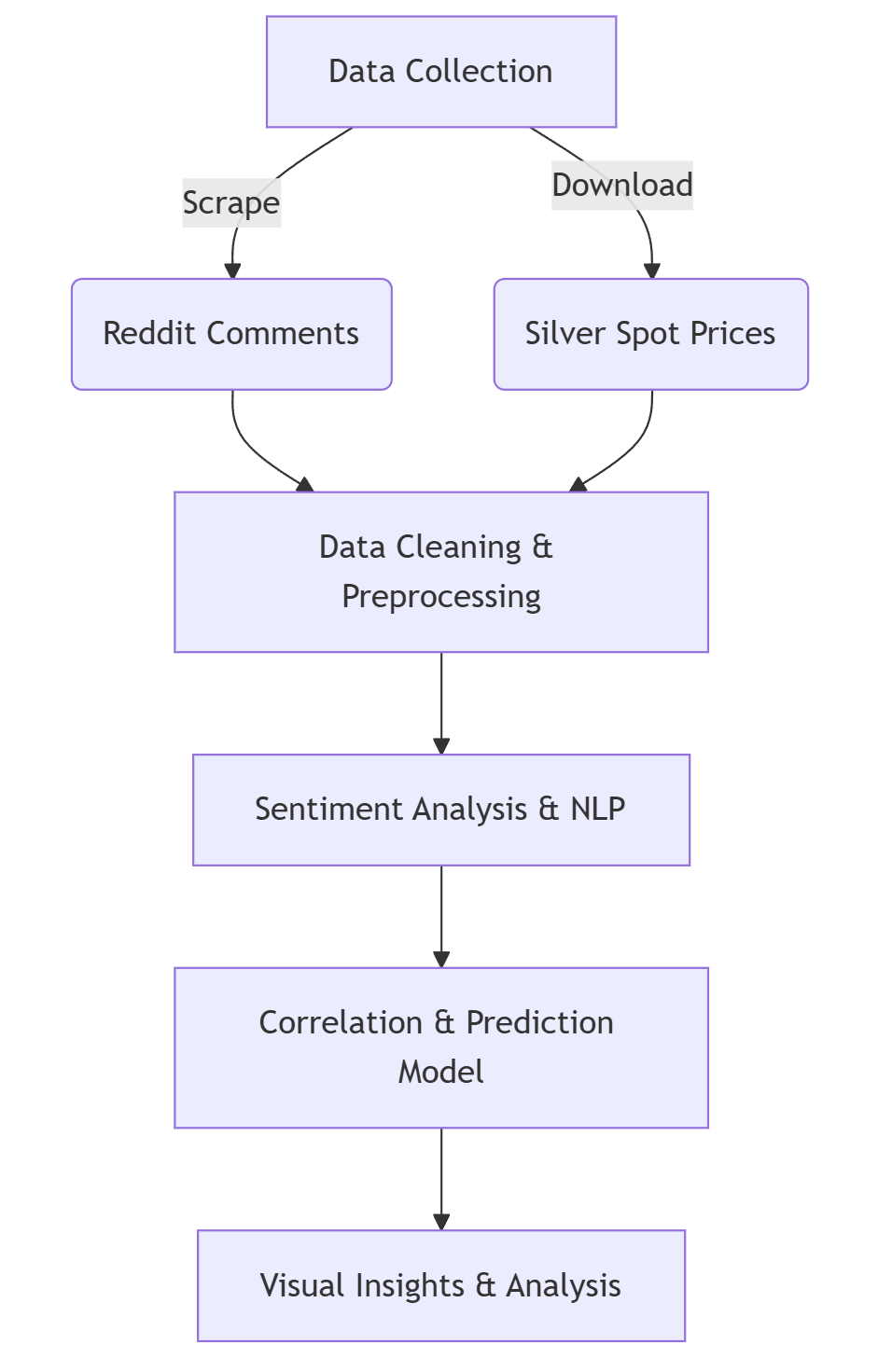
2. Data Collection from Reddit under New Policy
Objective:
To gather high-quality, relevant discussions regarding silver prices from the Reddit community, specifically targeting subreddits like r/PreciousMetals and r/Wallstreetsilver.
The Challenge: At the beginning, we tried the previous method introduced on the lecture note, using PRAW to get Reddit data. However, we found that there was a policy change and individual users are no longer able to apply the previous API method for getting text data.
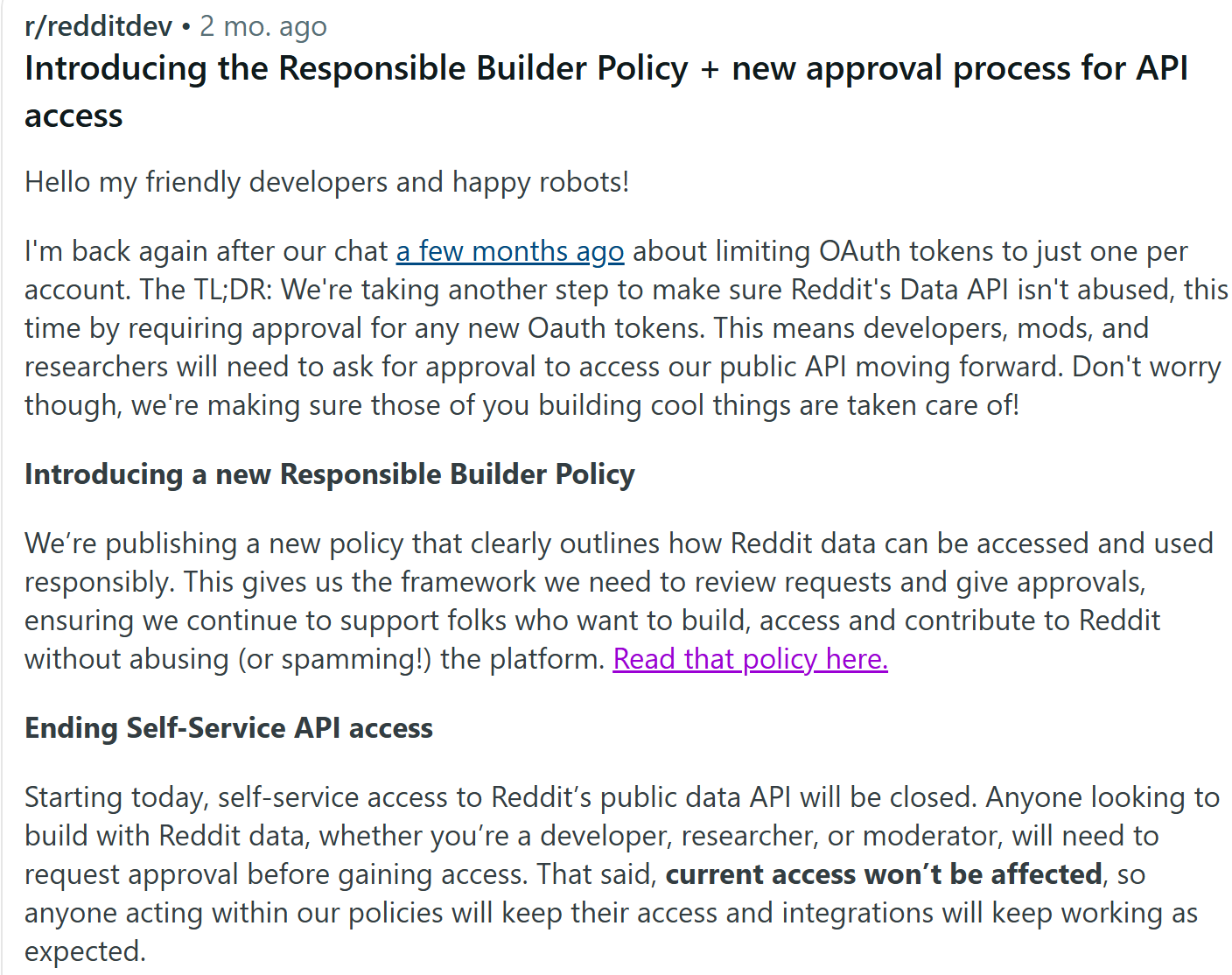
Our Solution: To solve this problem, we developed a hybrid approach using RSS Feeds combined with JSON endpoints. This allows us to bypass some heavy API restrictions while ensuring we capture the most relevant posts. Here is our step-by-step methodology with corresponding code snippets:
-
RSS Feed Search:
Instead of iterating through all posts, we use Reddit's RSS search feature with a specific query structure (title:silver price) to target posts where the discussion is explicitly about the price.# Constructing the RSS URL for specific search query TARGET_SUBREDDITS = "PreciousMetals+Wallstreetsilver" SEARCH_KEYWORD = "title:silver price" # Strict title search rss_url = ( f"https://www.reddit.com/r/{TARGET_SUBREDDITS}/search.rss" f"?q={SEARCH_KEYWORD}&sort=relevance&t=all&limit={LIMIT_POSTS}" ) -
Relevance Filtering:
We implemented a strict filter to ensure the post title contains core keywords (e.g., "silver forecast", "ounce", "silver $"), filtering out noise at the source.def is_post_title_related(title): # Core keywords required in the title core_words = ["silver price", "silver $", "ounce", "silver forecast"] title_lower = title.lower() return any(word in title_lower for word in core_words) -
JSON Extraction:
For each valid post found via RSS, we access its.jsonendpoint to retrieve comments recursively. This method provides structured data without needing complex HTML parsing.# Accessing the JSON endpoint of a specific post post_api_url = post_link.rstrip("/") + ".json" resp = requests.get(post_api_url, headers=HEADERS) post_json = resp.json() # Extracting the comment tree comment_children = post_json[1]["data"]["children"] -
Comment Filtering:
We filter comments based on Time (last 90 days), Quality (minimum upvotes), and Content (investment-related keywords).# 1. Time and Quality Filter (inside the collection loop) if comment_utc < THREE_MONTHS_AGO: continue if comment_score < MIN_UPVOTES: continue # 2. Content Relevance Filter price_related_words = ["price", "ounce", "dollar", "invest", "forecast", "trend"] # Keeping only comments containing relevant keywords filtered_df = comments_df[comments_df["comment_content"].apply( lambda x: any(word in x.lower() for word in price_related_words) )]
Preliminary Results: Our collected data looks as follows. We have successfully filtered out generic noise, ensuring that most of the text data are strictly about the silver price.

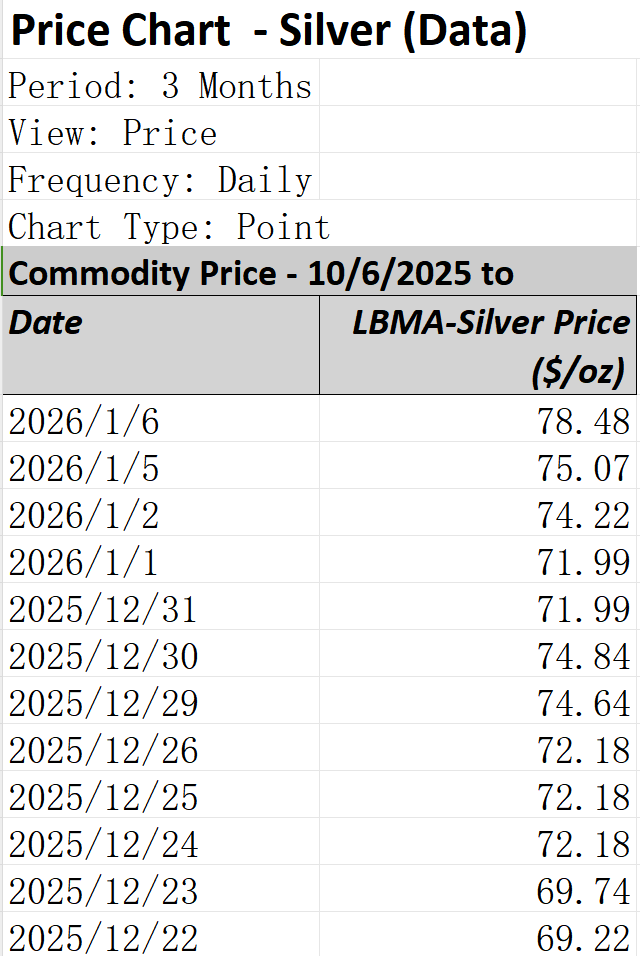
3. Silver Price Data Collection
We used Capital IQ for collecting silver prices between the past three months. The reason why we chose this period was because the silver price surged rapidly during the time and attracted more speculators to join the market.
As a common belief, the market would be much more irrational i.e. emotional when the price changes rapidly. Therefore, we believe the Reddit users’ sentiment information would be more telling under this type of situation. Moreover, we found that there are significantly more posts about the silver prices during such periods than stable price periods, which provides enough data for collection.
We collected the silver data as followed:
4. Core Project Goals
Our project is structured into four distinct layers to ensure a comprehensive analysis:
- Data Layer: Construct a high-quality dataset, including about 500 Reddit comments related to "silver price" (covering core subreddits like
r/WallStreetSilver), along with synchronized structured data such as spot silver prices. - Technical Layer: Implement the full workflow of data crawling, text preprocessing, and NLP analysis (sentiment mining + topic modeling) using Python. Master core technologies including PRAW/Requests crawler, NLTK/VADER text processing, adapting to the uniqueness of social media text.
- Analysis Layer: Quantify the correlation between Reddit community sentiment and silver price fluctuations (returns, volatility), identify core topics influencing silver prices (e.g., inflation hedging, industrial demand, policy changes), and verify the predictive value of textual signals for market movements.
- Deliverable Layer: Produce project deliverables meeting course requirements, including a project report, two presentation slides, two technical blogs, and fully reproducible code, providing data support and reference for short-term silver investment decisions.
5. Project Importance
We believe this project holds significant value in three key areas:
- Academic Value: Responding to the course’s core requirement of "interdisciplinary application of NLP and finance," this project validates the incremental value of unstructured textual data in commodity price prediction. It complements the limitations of traditional quantitative models in capturing market sentiment(which only care about news), aligning with the application scenarios of "social media sentiment analysis in financial markets" outlined in Chapter 4.
- Practical Value: As an asset with both commodity and financial attributes, silver prices are highly sensitive to market sentiment. Reddit, as a globally influential investment community, hosts authentic opinions from both retail and professional investors. The analysis results can directly provide short-term risk early warnings and decision support for investors and analysts.
- Technical Value: Covering the full workflow of "data crawling → preprocessing → text analysis → empirical validation," this project strengthens the comprehensive application of Python programming, NLP technologies, and financial data analysis, meeting the course’s requirement for group projects to "balance technical depth and practical implementation."
6. Ongoing Works
In the next stage, we are going to clean our text data, and prepare for applying sentiment analysis toolpackages. We will focus on: 1. Removing stopwords and irrelevant symbols from the Reddit comments. 2. Aligning the timestamps of the comments with the trading hours of the silver market. 3. Testing initial sentiment scoring using VADER to see if any immediate patterns emerge.