Introduction
Core Objective: To extract the dovish (easing) / hawkish (tightening) policy tendencies from the FOMC meeting minutes through text analysis, construct a correlation model between such tendencies and the U.S. 10-year Treasury yield, verify the linkage between policy signals and market indicators, and provide support for the interpretation of monetary policy transmission effects and investment decision-making.
1. Data Acquisition
1.1 Acquisition of Federal Reserve Meeting Minutes
The main steps and core functions are as follows:
- Crawl the URLs of FOMC meeting minutes within the specified date range (20200129-20251210) from the Federal Reserve official website and generate a
URL.csvfile. - Read the links from
URL.csv, access the webpages, crawl and extract text using BeautifulSoup, then clean the text with regular expressions (remove quotation marks and redundant formats). - Save the cleaned text as TXT files named by date.
1.2 Acquisition of Macroeconomic Data
- Download the 10-year U.S. Treasury bond yield from Yahoo Finance (yhfinance).
2. API Call
After extracting the text, we perform sentiment analysis on it. Long-text processing is one of the core advantages of Large Language Models (LLMs). However, each meeting minutes document contains a large volume of text (ranging from 50,000 to 80,000 characters), and the free quota provided by APIs of mainstream AI platforms is usually less than 2,000,000 characters, which can be exhausted quickly. In addition, the API call cost for services like ChatGPT is relatively high. Eventually, we selected a free-tier LLM API that offered sufficient quota for our analysis needs, and we adopted it for text analysis.
Before using such an API, users must first obtain access credentials by registering on the chosen LLM provider's platform, creating a dedicated application, and obtaining an API key. The API key must be predefined before running the code, as indicated in the commented code below.
The specific calling code is as follows:
# encoding:UTF-8
import json
import requests
# Replace with your API key.
api_key = ""
url = "YOUR_LLM_API_ENDPOINT"
# Call the model and output the result
def get_answer(message):
# Initialize request body
headers = {'Authorization':api_key,'content-type': "application/json"}
body = {"model": "MODEL_NAME","user": "user_id","messages": message,"stream": True}
full_response = "" # Store the returned result
isFirstContent = True # First frame flag
response = requests.post(url=url,json= body,headers= headers,stream= True)
for chunks in response.iter_lines():
if (chunks and '[DONE]' not in str(chunks)):
data_org = chunks[6:]
chunk = json.loads(data_org)
text = chunk['choices'][0]['delta']
if ('content' in text and '' != text['content']):
content = text["content"]
if (True == isFirstContent):
isFirstContent = False
print(content, end="")
full_response += content
return full_response
# Manage conversation history and organize it into a list in order
def getText(text,role, content):
jsoncon = {}
jsoncon["role"] = role
jsoncon["content"] = content
text.append(jsoncon)
return text
# Get the total length of content from all roles in the conversation
def getlength(text):
length = 0
for content in text:
temp = content["content"]
leng = len(temp)
length += leng
return length
# Check if the length exceeds the limit (current limit: 8K tokens)
def checklen(text):
while (getlength(text) > 11000):
del text[0]
return text
# Main program entry
if __name__ =='__main__':
chatHistory = [] # Conversation history storage list
while (1): # Loop for conversation turns
Input = input("\n" + "Me:")
question = checklen(getText(chatHistory,"user", Input))
print("LLM:", end="")
getText(chatHistory,"assistant", get_answer(question))
This API has a limitation where the maximum input character count is only 8,000. To deal with this, we will subsequently split the FOMC meeting minutes into several sections and analyze each section separately.
3. Hawkish/Dovish Sentiment Analysis
3.1 Subject Content Extraction (Semantic Matching Optimization)
Implement semantic fuzzy matching using regular expressions to solve the problem of chapter title variations and accurately extract the content of target chapters. Here is an example:
"Developments in Financial Markets and Open Market Operations":
r"(developments in financial markets and|financial developments and) open market operations"
Then, we extract subject content using the following code:
import re
def extract_section_from_text(full_text, target_sections_map):
section_content = {}
text_lower = full_text.lower()
positions = []
# 1. Locate all target section titles in the full text
for title, pattern in target_sections_map.items():
match = re.search(pattern, text_lower)
if match:
positions.append({
"title": title,
"start": match.start(),
"end": match.end()
})
# 2. Sort sections by their order of appearance in the document
positions.sort(key=lambda x: x["start"])
# 3. Extract section content from the end of the current title
# to the beginning of the next title
for i, pos in enumerate(positions):
start = pos["end"]
end = positions[i + 1]["start"] if i + 1 < len(positions) else len(full_text)
section_content[pos["title"]] = full_text[start:end].strip()
return section_content
3.2 Sentiment Scoring (Dovish/Hawkish)
A complete batch sentiment analysis workflow targets different sections of the FOMC meeting minutes by calling an API to score each paragraph for dovish and hawkish sentiment intensity and returns the results in a structured format. The scores range from 0 to 1, where hawkish indicates hawkish strength (0 = no hawkishness, 1 = very hawkish) and dovish indicates dovish strength (0 = no dovishness, 1 = very dovish).
def call_llm_api(text):
# Construct a constrained prompt to force JSON-only output
prompt = f"""
Analyze the monetary policy stance of the following FOMC minutes paragraph.
1. Return only a JSON with two fields, no extra text:
- hawkish: hawkish strength from 0 to 1 (0 = no hawkishness, 1 = very hawkish)
- dovish: dovish strength from 0 to 1 (0 = no dovishness, 1 = very dovish)
2. Hawkish means supporting tightening policies
3. Dovish means supporting easing policies
Text:
{text[:5000]} # truncate long text to avoid API limits
"""
# Prepare the API request headers and body, disable streaming for easier parsing
headers = {"Authorization": API_KEY, "Content-Type": "application/json"}
body = {"model": API_MODEL, "messages": [{"role": "user", "content": prompt}], "stream": False}
# Call the API and handle the response
try:
r = requests.post(API_URL, json=body, headers=headers, timeout=API_TIMEOUT)
r.raise_for_status() # Fail fast on HTTP errors
content = r.json()["choices"][0]["message"]["content"]
match = re.search(r"\{.*\}", content, re.DOTALL) # Extract JSON only
sentiment = json.loads(match.group())
hawkish = max(0.0, min(1.0, float(sentiment["hawkish"]))) # Clip to [0,1]
dovish = max(0.0, min(1.0, float(sentiment["dovish"])))
return {"hawkish": hawkish, "dovish": dovish}
except Exception as e:
print(f"API error: {e}")
return {"hawkish": 0.0, "dovish": 0.0}
def analyze_paragraphs_with_api(df):
# Convert wide format to long format for per-paragraph processing
long_df = df.melt(id_vars=["date"], value_vars=TARGET_SECTIONS, var_name="section", value_name="content")
# Remove empty paragraphs
long_df = long_df[long_df["content"].str.strip() != ""].reset_index(drop=True)
sentiments = []
for idx, row in long_df.iterrows():
# Call API for each paragraph
sentiments.append(call_llm_api(row["content"]))
time.sleep(API_DELAY)
# Merge API results back into the DataFrame
sentiment_df = pd.DataFrame(sentiments)
long_df["hawkish"] = sentiment_df["hawkish"]
long_df["dovish"] = sentiment_df["dovish"]
# Pivot back to wide format for easier analysis
wide_df = long_df.pivot_table(index="date", columns="section", values=["content", "hawkish", "dovish"], aggfunc="first")
wide_df.columns = [f"{sec}_{val}" for val, sec in wide_df.columns]
wide_df = wide_df.reset_index()
return long_df, wide_df
3.3 Visualization of stacked diagrams
We normalize hawkish and dovish scores so their sum equals 1 for each topic, ensuring comparability across topics. For each meeting, we generate horizontal stacked bar charts showing hawkish intensity in red and dovish intensity in blue for multiple predefined topics to analyze their impact on the 10-year Treasury yield.
for topic in topics:
d_col = f"{topic}_dovish"
h_col = f"{topic}_hawkish"
if d_col in df.columns and h_col in df.columns:
denom = df[d_col] + df[h_col]
# Normalize by dividing each score by their sum when sum is not zero
df.loc[denom != 0, d_col] = df.loc[denom != 0, d_col] / denom[denom != 0]
df.loc[denom != 0, h_col] = df.loc[denom != 0, h_col] / denom[denom != 0]
# When both scores sum to zero, assign 0.5 to both
df.loc[denom == 0, d_col] = 0.5
df.loc[denom == 0, h_col] = 0.5
Here is one example of the output stacked diagramimgs
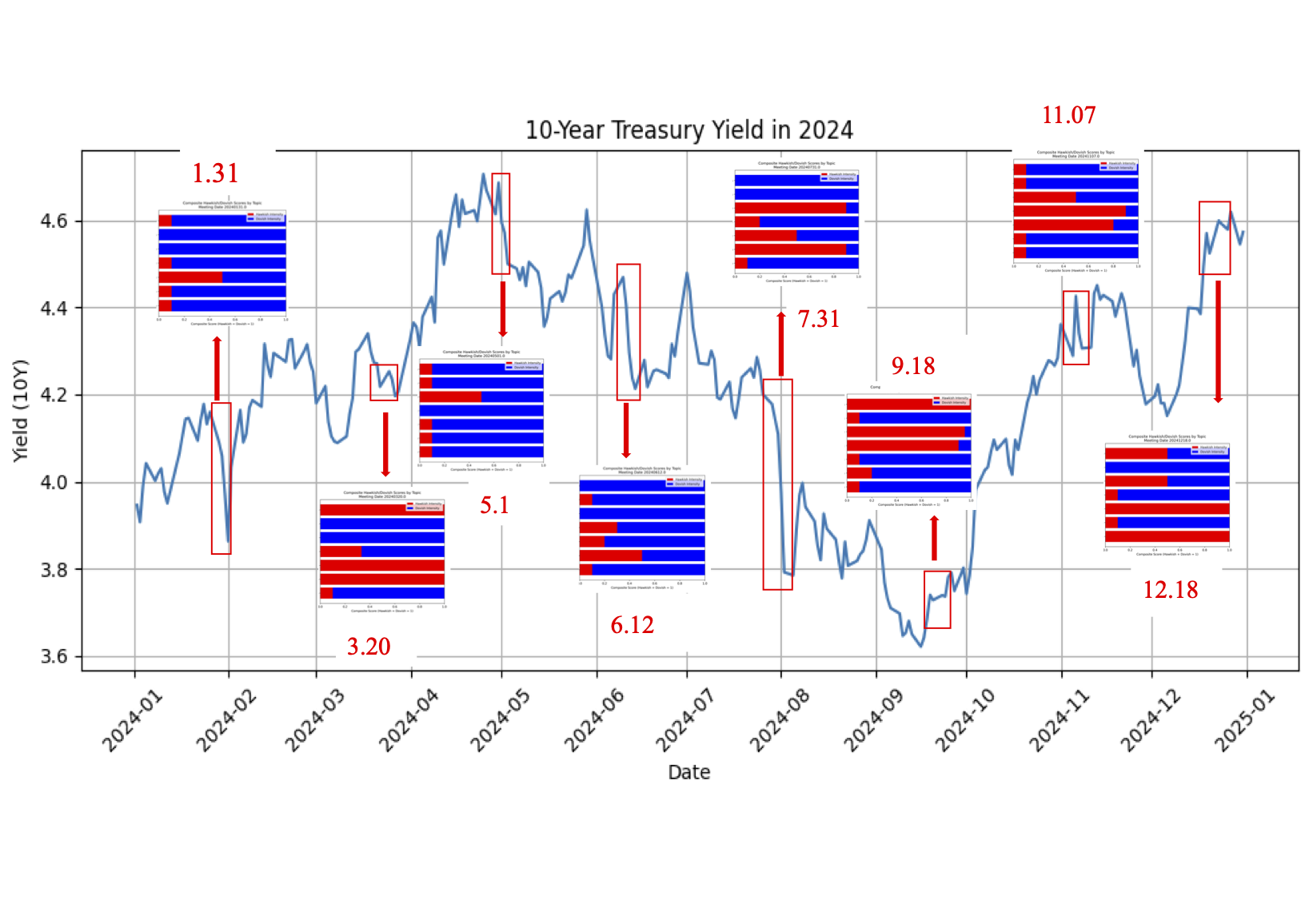
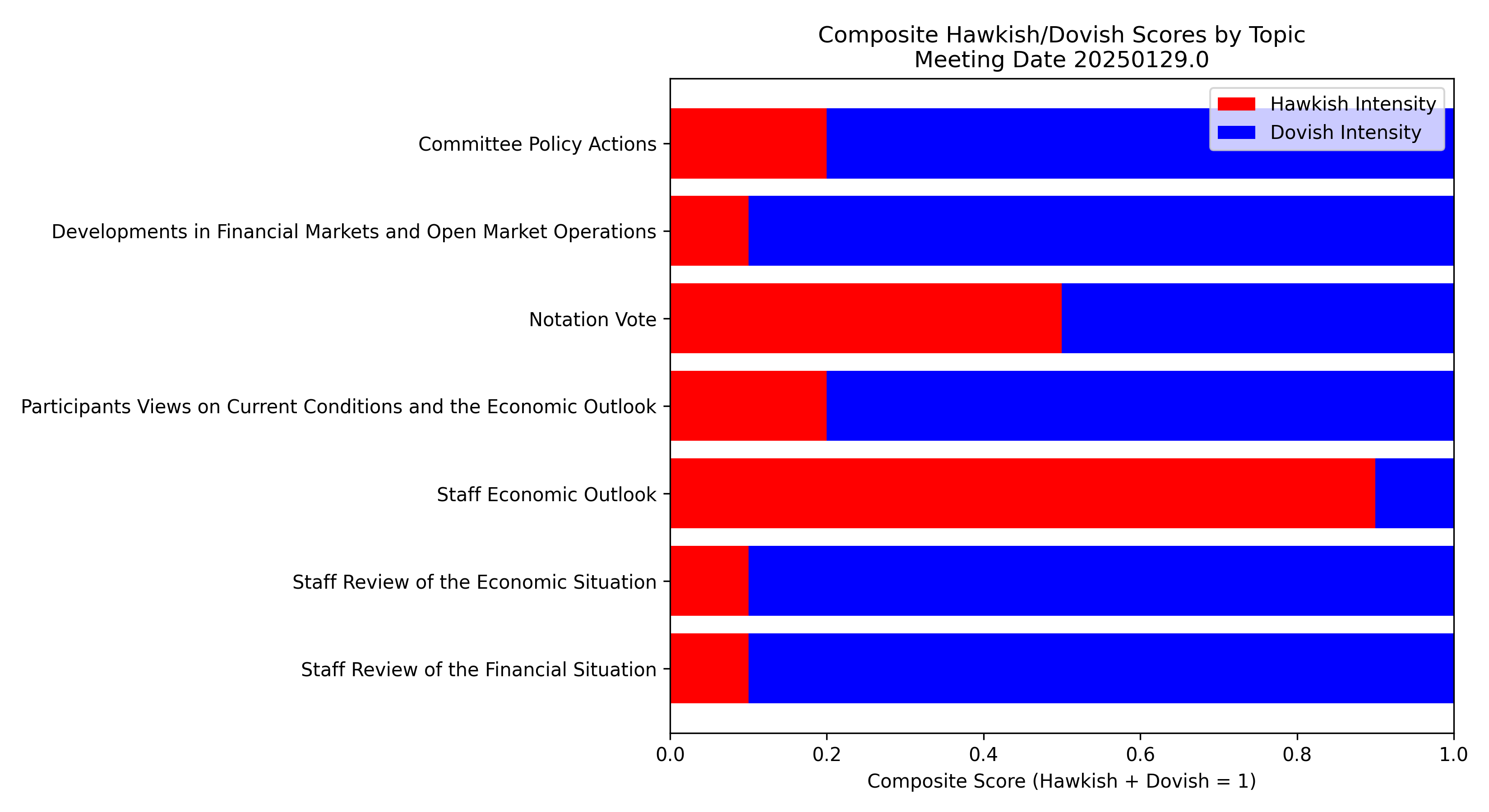 Here uses 2024 as an example to visualize the impact of FOMC meeting minutes on the 10-Year Treasury Yield:
Here uses 2024 as an example to visualize the impact of FOMC meeting minutes on the 10-Year Treasury Yield:
3.4 Word Cloud Analysis (Sentiment Feature Visualization)
Word clouds display high-frequency hawkish and dovish keywords to validate sentiment scores. We use an API-based large language model with strict prompts to convert text into structured sentiment data.
prompt = f"""
You are a financial analyst. Analyze the provided FOMC minutes text.
Task: Extract exact sentences that are Hawkish or Dovish.
Definitions:
- Hawkish:
Support tightening, raising rates, fighting inflation, concerned about high prices.
- Dovish:
Support easing, lowering rates, concerned about unemployment/growth, tolerating inflation.
"""
However, financial texts are context-dependent, making keywords insufficient to capture sentiment. After cleaning the junk words, we implemented Part-of-Speech (POS) tagging to strictly filter for Noun Phrases (specifically Adjective+Noun or Noun+Noun). By filtering for patterns, we captured specific, descriptive economic indicators:
- Instead of just "Labor," the code captures "Tight Labor."
- Instead of just "Supply," the code captures "Supply Chains."
- Instead of just "Prices," the code captures "High Prices."
def create_circle_mask(width, height):
x, y = np.ogrid[:width, :height]
center_x, center_y = width / 2, height / 2
radius = min(width, height) / 2
mask = (x - center_x) ** 2 + (y - center_y) ** 2 > radius ** 2
return 255 * mask.astype(int)
def smart_phrase_extraction(text: str) -> Counter:
if pd.isna(text) or text.strip() == "":
return Counter()
text = text.lower()
text = re.sub(r"[\n\r]+", " ", text)
text = re.sub(r"[^\w\s-]", " ", text)
text = re.sub(r"\d+", "", text)
text = re.sub(r"\s+", " ", text).strip()
tokens = word_tokenize(text)
tagged_tokens = pos_tag(tokens)
valid_phrases = []
for i in range(len(tagged_tokens) - 1):
w1, t1 = tagged_tokens[i]
w2, t2 = tagged_tokens[i+1]
if w1 in JUNK_WORDS or w2 in JUNK_WORDS:
continue
is_adj_noun = t1.startswith('JJ') and t2.startswith('NN')
is_noun_noun = t1.startswith('NN') and t2.startswith('NN')
is_verb_noun = t1.startswith('VBG') and t2.startswith('NN')
if is_adj_noun or is_noun_noun or is_verb_noun:
phrase = f"{w1} {w2}"
valid_phrases.append(phrase)
return Counter(valid_phrases)
For example, in 2021, the stance shifted from mostly dovish to increasingly hawkish. Early in the year, focus was on labor recovery and pandemic risks (“20210428”). As inflation persisted, hawkish concerns arose around supply constraints (“20211103”). By year-end, the Committee moved away from the “transitory” view, signaling inflation risks outweighed patience.


4. Empirical Results & Analysis
4.1 Correlation Analysis
The heatmap shows correlations between FOMC statement sentiment and policy actions:
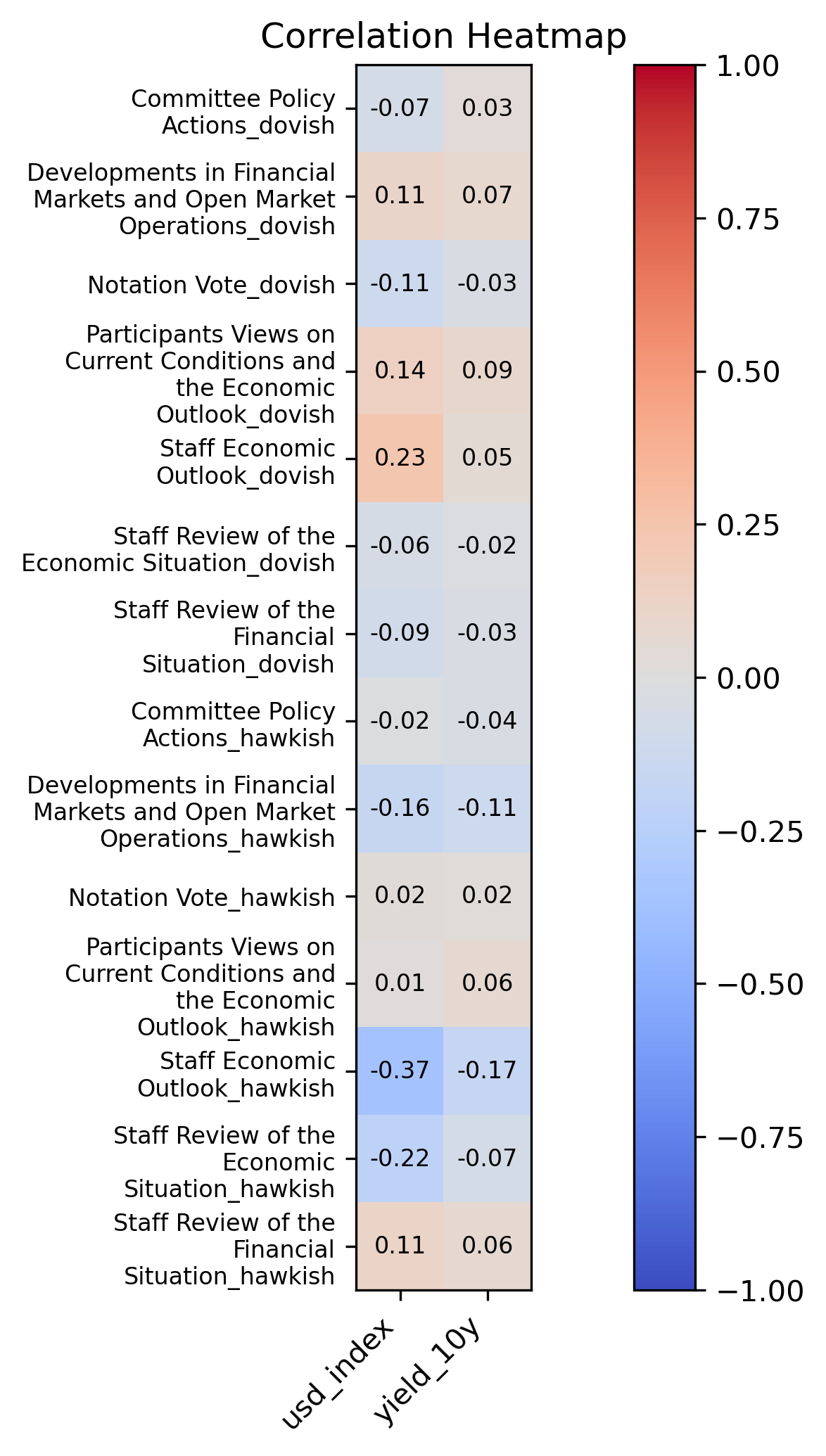 Dovish indicators have weak positive correlations with changes in the USD index, while Hawkish indicators tend to exhibit negative correlations with the USD index.
Dovish indicators and hawkish indicators present mixed correlations with 10-year treasry yields.
Dovish indicators have weak positive correlations with changes in the USD index, while Hawkish indicators tend to exhibit negative correlations with the USD index.
Dovish indicators and hawkish indicators present mixed correlations with 10-year treasry yields.
4.2 Correlation Verification
We further use P-value to tesify the correlation and draw heatmap.
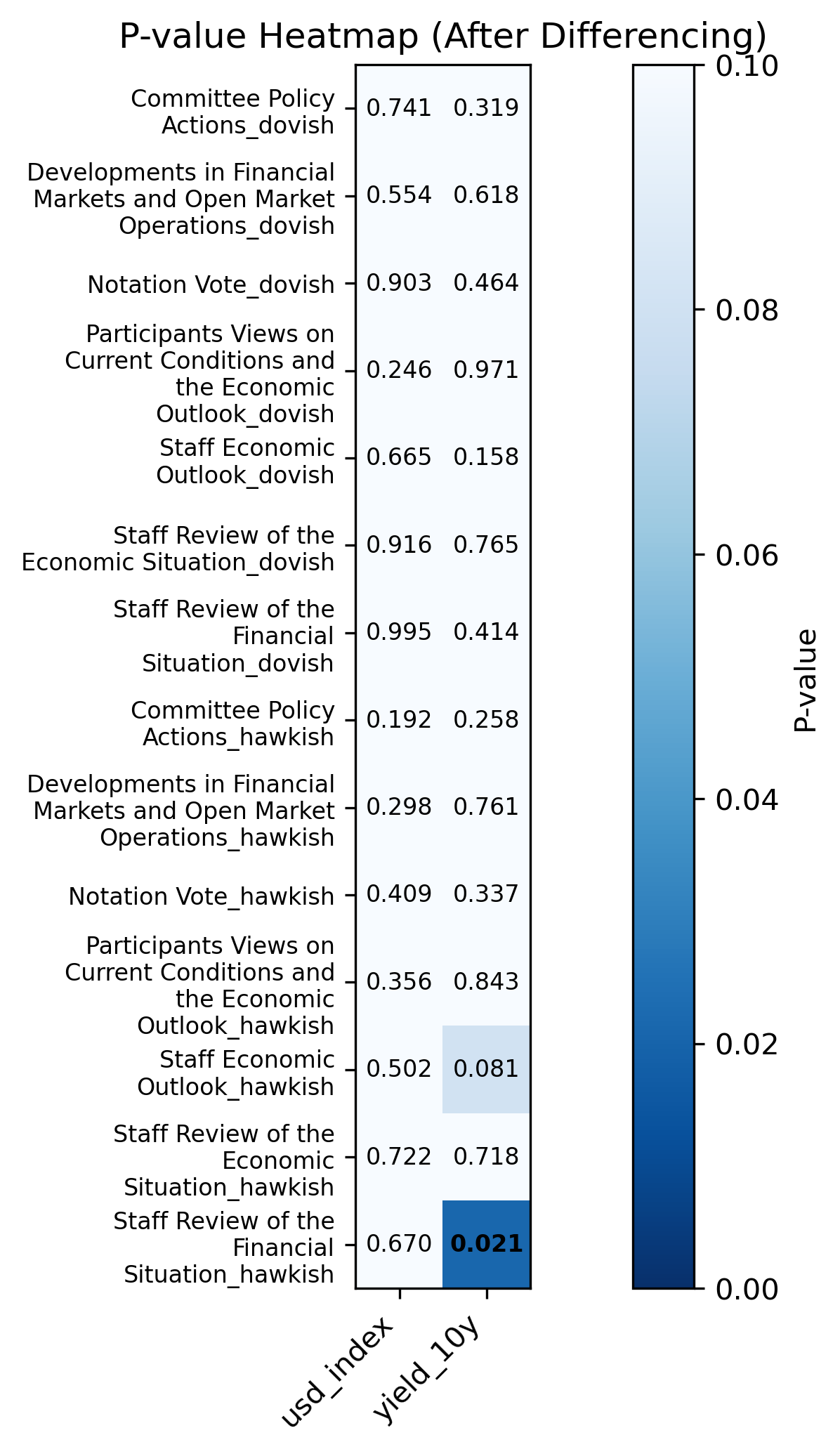 From the P-value results, we can get the conclusions:
Overall, the p-value results suggest that most of the estimated correlations between FOMC sentiment measures and macroeconomic indicators are not statistically significant at conventional significance levels. For the majority of sentiment–macro pairs, the observed correlations are likely driven by noise rather than systematic relationships. This implies that short-term fluctuations in hawkish or dovish language intensity are not strongly or consistently associated with contemporaneous movements in the U.S. dollar index or the 10-year Treasury yield.
Notably, the correlation between hawkish sentiment in the Staff Review of the Financial Situation and the 10-year Treasury yield is statistically signigicant (p = 0.02). This result suggests a potential link whereby increases in hawkish language within staff assessments of financial conditions are associated with short-term changes in 10-year interest rates.
From the P-value results, we can get the conclusions:
Overall, the p-value results suggest that most of the estimated correlations between FOMC sentiment measures and macroeconomic indicators are not statistically significant at conventional significance levels. For the majority of sentiment–macro pairs, the observed correlations are likely driven by noise rather than systematic relationships. This implies that short-term fluctuations in hawkish or dovish language intensity are not strongly or consistently associated with contemporaneous movements in the U.S. dollar index or the 10-year Treasury yield.
Notably, the correlation between hawkish sentiment in the Staff Review of the Financial Situation and the 10-year Treasury yield is statistically signigicant (p = 0.02). This result suggests a potential link whereby increases in hawkish language within staff assessments of financial conditions are associated with short-term changes in 10-year interest rates.
5. Future Improvement
-
Reliance on a single API for sentiment scoring may introduce bias due to lack of multi-model cross-validation.
-
External shocks such as geopolitical events and unexpected economic incidents were not accounted for, potentially confounding yield movements.
-
Introduce pretrained models like BERT to train custom sentiment classifiers, enhancing accuracy and robustness.