Note: Since the code is too lengthy, please refer to our GitHub repository (Google_news2024_getandclean_v1) for the relevant implementation.
1.Data source
We aim to develop a sentiment analysis model for financial markets. The initial objective is to acquire monthly news data and monthly social media data for 14 major financial assets within the timeframe from January 2003 to December 2024.
| Ticker | Asset | Asset Class |
|---|---|---|
| GSPC | S&P 500 Index | Equities |
| IXIC | NASDAQ Composite | Equities |
| DJI | Dow Jones Industrial Average | Equities |
| FCHI | CAC 40(France) | Equities |
| FTSE | FTSE 100(UK) | Equities |
| STOXX50E | EuroStoxx 50 | Equities |
| HSI | Hang Seng Index(Hong Kong) | Equities |
| 000001.SS | Shanghai Composite(China) | Equities |
| BSESN | BSE Sensex(India) | Equities |
| NSEI | Nifty 50(India) | Equities |
| KS11 | KOSPI(South Korea) | Equities |
| GC=F | Gold | Commodities |
| SI=F | Silver | Commodities |
| CL=F | WTI Crude Oil Futures | Commodities |
2.News Data Collection
2.1 Source 1: API.ai
First, we want to share the difficulties encountered, solutions explored, and final outcomes in obtaining news data.
After studying the Data Sources in the Lecture Notes, we first considered obtaining data from NewsAPI.ai. Its advantages over other methods are as follows:
-
Simple REST API interface
-
Returns JSON format data directly, including title, body, source, and timestamp
-
Relatively fast download speed
So, we registered an account on the API website and obtained the API key.
import requests
API_KEY = "Our_API_Key"
API_URL = https://eventregistry.org/api/v1/article/getArticles
2.1.1 API Connection Testing and Primary Data Acquisition Attempt
We first conducted a test to see if we could connect to the API and successfully retrieve data for the S&P 500 for the last month of 2025.
def test_api():
print("It is a test")
test_params = {
"apiKey": API_KEY,
"action": "getArticles",
"keyword": "S&P 500",
"dateStart": "2025-12-01",
"dateEnd": "2025-12-31",
"dataType": "news",
"lang": "eng"
}
try:
response = requests.get(API_URL, params=test_params, timeout=15)
if response.status_code == 200:
data = response.json()
print("Connect to API successfully")
if "articles" in data:
articles = data["articles"].get("results", [])
print(f"get {len(articles)} articles")
if articles:
print(f"Title example:{articles[0].get('title', 'N/A')[:80]}...")
return True, len(articles)
return True, 0
else:
print(f"{response.text[:200]}")
return False, 0
except Exception as e:
print(f"{e}")
return False, 0
Running the test_api function, the test passed smoothly, successfully retrieving 100 news articles related to the S&P 500 for December 2025.
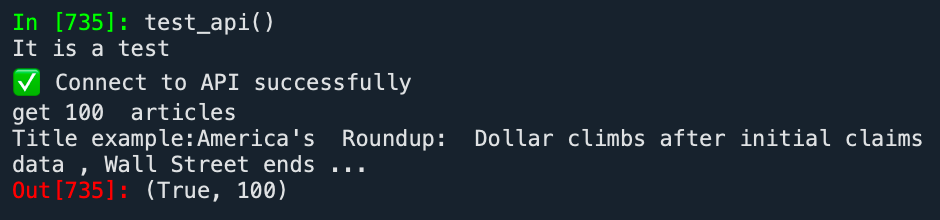
We then continued to attempt to retrieve news data related to the S&P 500 for our required time window.
def news_api(keyword):
print("It is a test")
test_params = {
"apiKey": API_KEY,
"action": "getArticles",
"keyword": "S&P 500",
"dateStart": "2025-12-01",
"dateEnd": "2025-12-31",
"dataType": "news",
"lang": "eng"
}
But to our surprise, we retrieved 0 articles related to the S&P 500 for the window period from January 2003 to December 2024.

2.1.2 Problem Diagnosis Process
To solve this problem, we constructed multiple keywords for the asset to search for news. However, all five keywords failed to retrieve any results.
simple_queries = ["S&P 500", "SPX", "S&P500", "Standard & Poor's", "stock market", "Wall Street"]
results_simple = {}
for query in simple_queries:
success, articles = news_Main(query)
results_simple[query] = len(articles) if articles else 0
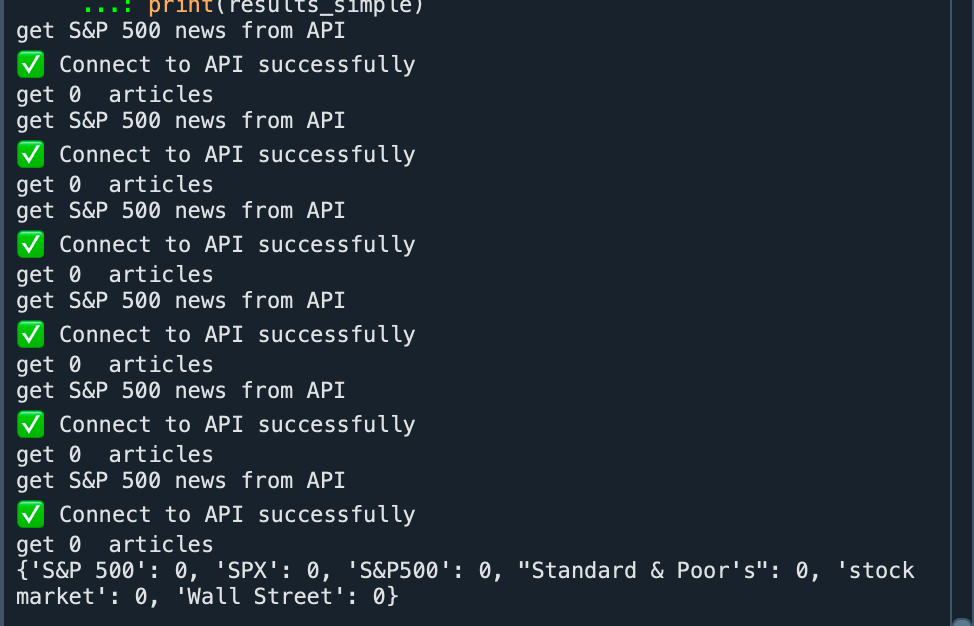
Ultimately, we suspected that due to the data retrieval limitations of the API's free tier, we could not obtain data for a long time window. Therefore, we attempted to design a comprehensive diagnostic program to identify the root cause.
fetch_news_for_range(days) is the time-window diagnostic function we designed specifically to test the historical data support level of NewsAPI.ai.
This function accepts a days parameter, automatically calculates the corresponding date range, and then queries for news related to "EuroStoxx 50" (the reason for not querying S&P 500 related news here is that the number of S&P 500 related articles is too large, exceeding the return limit from the very first time window; the return limit will be mentioned later).
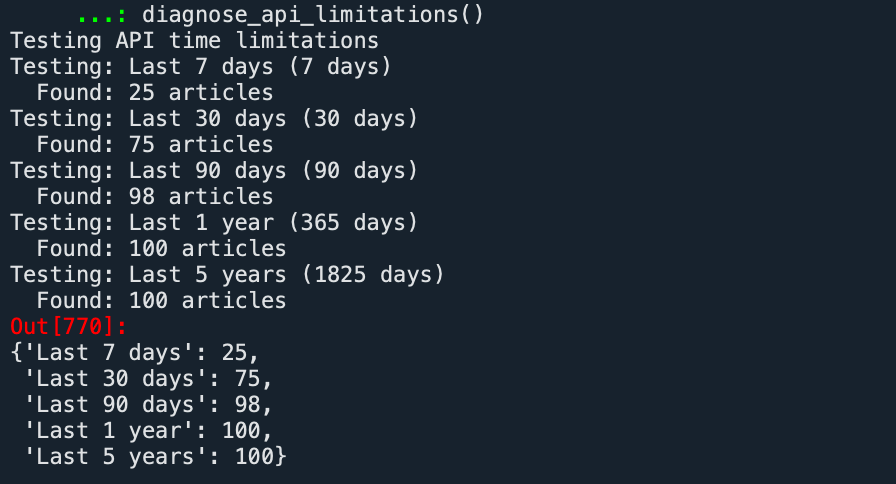
By testing different days values (7 days, 30 days, 90 days, 1 year, 5 years), we could clearly understand the actual capability boundary of the free version of the API.
def fetch_news_for_range(days):
from datetime import datetime, timedelta
end_date = datetime.now()
start_date = end_date - timedelta(days=days)
date_from = start_date.strftime("%Y-%m-%d")
date_to = end_date.strftime("%Y-%m-%d")
params = {
"apiKey": API_KEY,
"action": "getArticles",
"keyword": "EuroStoxx 50",
"dateStart": date_from,
"dateEnd": date_to,
"dataType": "news",
"lang": "eng"
}
try:
response = requests.get(API_URL, params=params, timeout=15)
if response.status_code == 200:
data = response.json()
return data
else:
return {"articles": {"results": []}}
except Exception as e:
return {"articles": {"results": []}}
def diagnose_api_limitations():
test_ranges = [
("Last 7 days", 7),
("Last 30 days", 30),
("Last 90 days", 90),
("Last 1 year", 365),
("Last 5 years", 5 * 365),
]
results = {}
print("Testing API time limitations")
for name, days in test_ranges:
# Test each time range
print(f"Testing: {name} ({days} days)")
data = fetch_news_for_range(days)
article_count = len(data.get("articles", {}).get("results", []))
results[name] = article_count
print(f" Found: {article_count} articles")
return results
From the diagnostic results, we did not truly test the time range limit of the API. The data increased to 100 as the query window expanded and then stopped rising. On the surface, it seemed constrained by the time window, but after testing with other keywords and combining it with the previous test_api result which also returned 100 articles, we finally confirmed: The actual limitation is not the time range, but the API's single-page return limit -- a maximum of 100 records per page. The time window test was essentially masked by this quantity limit, failing to truly reflect the API's complete support capability for historical data.
To distinguish between the return limit and time constraints, we redesigned our testing strategy, shifting from continuous time window testing to segmented time interval analysis. We divided the timeline into six non-overlapping intervals, each queried independently, avoiding the distortion of results by the single-query quantity limit.
from datetime import datetime, timedelta
def fetch_news_for_range(start_days_ago, end_days_ago):
from datetime import datetime, timedelta
end_date = datetime.now() - timedelta(days=end_days_ago)
start_date = datetime.now() - timedelta(days=start_days_ago)
date_from = start_date.strftime("%Y-%m-%d")
date_to = end_date.strftime("%Y-%m-%d")
params = {
"apiKey": API_KEY,
"action": "getArticles",
"keyword": "EuroStoxx 50",
"dateStart": date_from,
"dateEnd": date_to,
"dataType": "news",
"lang": "eng"
}
…
def diagnose_api_limitations_segmented():
test_ranges = [
("0-7 days", 7, 0, 7),
("7-30 days", 30, 7, 23),
("30-90 days", 90, 30, 60),
("90-180 days", 180, 90, 90),
("180-365 days", 365, 180, 185),
("365-730 days", 730, 365, 365),
]
results = {}
print("Segmented API Time Range Test")
total_articles = 0
for name, start_days, end_days, span_days in test_ranges:
data = fetch_news_for_range(start_days, end_days)
article_count = len(data.get("articles", {}).get("results", []))
results[name] = {
"articles": article_count,
"start_days": start_days,
"end_days": end_days,
"span_days": span_days,
"date_range": f"{(datetime.now() - timedelta(days=start_days)).strftime('%Y-%m-%d')} to {(datetime.now() - timedelta(days=end_days)).strftime('%Y-%m-%d')}"
}
print("Summary:")
print("Article Distribution:")
for name, info in results.items():
percentage = (info["articles"] / total_articles * 100) if total_articles > 0 else 0
print(f"{name:15} | {info['articles']:4} articles | {percentage:5.1f}%")
return results
The results show that the EuroStoxx 50 related news returned by the API exhibits a significant temporal decay trend: all articles are concentrated within the most recent 90 days, while the data retrieval result for periods before 90 days is zero. This indicates that this API has strict limitations on the time coverage of historical news; the actual usable data window likely does not exceed three months.
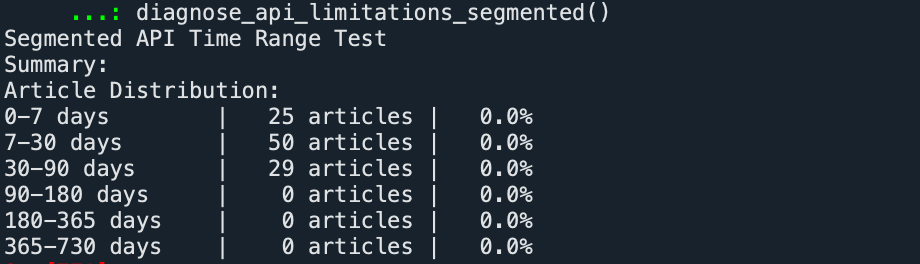
This demonstrates that the API approach is not viable, prompting us to turn to web scraping from Google News for data acquisition.
2.1.3 Conclusions and Insights
During this process of examining the data retrieval limits of the API, we had a vague sense that the path to obtaining complete data through this interface was not smooth. In fact, some team members had already begun turning to Google News scraping as an alternative solution. However, we still persisted in systematically verifying the reasons for the retrieval failure with code—this persistence itself is an important lesson we learned in the process: Sometimes the value of a problem lies not in being solved, but in being clearly identified and understood. The significance of technical exploration lies not only in finding a feasible path but also in understanding why a certain path is not feasible.
2.News Data Collection
2.1 Source 1: API.ai
First, we want to share the difficulties encountered, solutions explored, and final outcomes in obtaining news data.
After studying the Data Sources in the Lecture Notes, we first considered obtaining data from NewsAPI.ai. Its advantages over other methods are as follows:
-
Simple REST API interface
-
Returns JSON format data directly, including title, body, source, and timestamp
-
Relatively fast download speed
So, we registered an account on the API website and obtained the API key.
import requests
API_KEY = "Our_API_Key"
API_URL = https://eventregistry.org/api/v1/article/getArticles
2.1.1 API Connection Testing and Primary Data Acquisition Attempt
We first conducted a test to see if we could connect to the API and successfully retrieve data for the S&P 500 for the last month of 2025.
def test_api():
print("It is a test")
test_params = {
"apiKey": API_KEY,
"action": "getArticles",
"keyword": "S&P 500",
"dateStart": "2025-12-01",
"dateEnd": "2025-12-31",
"dataType": "news",
"lang": "eng"
}
try:
response = requests.get(API_URL, params=test_params, timeout=15)
if response.status_code == 200:
data = response.json()
print("Connect to API successfully")
if "articles" in data:
articles = data["articles"].get("results", [])
print(f"get {len(articles)} articles")
if articles:
print(f"Title example:{articles[0].get('title', 'N/A')[:80]}...")
return True, len(articles)
return True, 0
else:
print(f"{response.text[:200]}")
return False, 0
except Exception as e:
print(f"{e}")
return False, 0
Running the test_api function, the test passed smoothly, successfully retrieving 100 news articles related to the S&P 500 for December 2025.
We then continued to attempt to retrieve news data related to the S&P 500 for our required time window.
def news_api(keyword):
print("It is a test")
test_params = {
"apiKey": API_KEY,
"action": "getArticles",
"keyword": "S&P 500",
"dateStart": "2025-12-01",
"dateEnd": "2025-12-31",
"dataType": "news",
"lang": "eng"
}
But to our surprise, we retrieved 0 articles related to the S&P 500 for the window period from January 2003 to December 2024.
2.1.2 Problem Diagnosis Process
To solve this problem, we constructed multiple keywords for the asset to search for news. However, all five keywords failed to retrieve any results.
simple_queries = ["S&P 500", "SPX", "S&P500", "Standard & Poor's", "stock market", "Wall Street"]
results_simple = {}
for query in simple_queries:
success, articles = news_Main(query)
results_simple[query] = len(articles) if articles else 0
Ultimately, we suspected that due to the data retrieval limitations of the API's free tier, we could not obtain data for a long time window. Therefore, we attempted to design a comprehensive diagnostic program to identify the root cause.
fetch_news_for_range(days) is the time-window diagnostic function we designed specifically to test the historical data support level of NewsAPI.ai.
This function accepts a days parameter, automatically calculates the corresponding date range, and then queries for news related to "EuroStoxx 50" (the reason for not querying S&P 500 related news here is that the number of S&P 500 related articles is too large, exceeding the return limit from the very first time window; the return limit will be mentioned later).
By testing different days values (7 days, 30 days, 90 days, 1 year, 5 years), we could clearly understand the actual capability boundary of the free version of the API.
def fetch_news_for_range(days):
from datetime import datetime, timedelta
end_date = datetime.now()
start_date = end_date - timedelta(days=days)
date_from = start_date.strftime("%Y-%m-%d")
date_to = end_date.strftime("%Y-%m-%d")
params = {
"apiKey": API_KEY,
"action": "getArticles",
"keyword": "EuroStoxx 50",
"dateStart": date_from,
"dateEnd": date_to,
"dataType": "news",
"lang": "eng"
}
try:
response = requests.get(API_URL, params=params, timeout=15)
if response.status_code == 200:
data = response.json()
return data
else:
return {"articles": {"results": []}}
except Exception as e:
return {"articles": {"results": []}}
def diagnose_api_limitations():
test_ranges = [
("Last 7 days", 7),
("Last 30 days", 30),
("Last 90 days", 90),
("Last 1 year", 365),
("Last 5 years", 5 * 365),
]
results = {}
print("Testing API time limitations")
for name, days in test_ranges:
# Test each time range
print(f"Testing: {name} ({days} days)")
data = fetch_news_for_range(days)
article_count = len(data.get("articles", {}).get("results", []))
results[name] = article_count
print(f" Found: {article_count} articles")
return results
From the diagnostic results, we did not truly test the time range limit of the API. The data increased to 100 as the query window expanded and then stopped rising. On the surface, it seemed constrained by the time window, but after testing with other keywords and combining it with the previous test_api result which also returned 100 articles, we finally confirmed: The actual limitation is not the time range, but the API's single-page return limit -- a maximum of 100 records per page. The time window test was essentially masked by this quantity limit, failing to truly reflect the API's complete support capability for historical data.
To distinguish between the return limit and time constraints, we redesigned our testing strategy, shifting from continuous time window testing to segmented time interval analysis. We divided the timeline into six non-overlapping intervals, each queried independently, avoiding the distortion of results by the single-query quantity limit.
from datetime import datetime, timedelta
def fetch_news_for_range(start_days_ago, end_days_ago):
from datetime import datetime, timedelta
end_date = datetime.now() - timedelta(days=end_days_ago)
start_date = datetime.now() - timedelta(days=start_days_ago)
date_from = start_date.strftime("%Y-%m-%d")
date_to = end_date.strftime("%Y-%m-%d")
params = {
"apiKey": API_KEY,
"action": "getArticles",
"keyword": "EuroStoxx 50",
"dateStart": date_from,
"dateEnd": date_to,
"dataType": "news",
"lang": "eng"
}
…
def diagnose_api_limitations_segmented():
test_ranges = [
("0-7 days", 7, 0, 7),
("7-30 days", 30, 7, 23),
("30-90 days", 90, 30, 60),
("90-180 days", 180, 90, 90),
("180-365 days", 365, 180, 185),
("365-730 days", 730, 365, 365),
]
results = {}
print("Segmented API Time Range Test")
total_articles = 0
for name, start_days, end_days, span_days in test_ranges:
data = fetch_news_for_range(start_days, end_days)
article_count = len(data.get("articles", {}).get("results", []))
results[name] = {
"articles": article_count,
"start_days": start_days,
"end_days": end_days,
"span_days": span_days,
"date_range": f"{(datetime.now() - timedelta(days=start_days)).strftime('%Y-%m-%d')} to {(datetime.now() - timedelta(days=end_days)).strftime('%Y-%m-%d')}"
}
print("Summary:")
print("Article Distribution:")
for name, info in results.items():
percentage = (info["articles"] / total_articles * 100) if total_articles > 0 else 0
print(f"{name:15} | {info['articles']:4} articles | {percentage:5.1f}%")
return results
The results show that the EuroStoxx 50 related news returned by the API exhibits a significant temporal decay trend: all articles are concentrated within the most recent 90 days, while the data retrieval result for periods before 90 days is zero. This indicates that this API has strict limitations on the time coverage of historical news; the actual usable data window likely does not exceed three months.
This demonstrates that the API approach is not viable, prompting us to turn to web scraping from Google News for data acquisition.
2.1.3 Conclusions and Insights
During this process of examining the data retrieval limits of the API, we had a vague sense that the path to obtaining complete data through this interface was not smooth. In fact, some team members had already begun turning to Google News scraping as an alternative solution. However, we still persisted in systematically verifying the reasons for the retrieval failure with code—this persistence itself is an important lesson we learned in the process: Sometimes the value of a problem lies not in being solved, but in being clearly identified and understood. The significance of technical exploration lies not only in finding a feasible path but also in understanding why a certain path is not feasible.
2.2 Source 2: Google News
Building a web scraper to collect financial data from Google News presented a unique set of challenges. The goal was clear: programmatically gather news articles related to specific financial indices like the S&P 500 to analyze market sentiment. The reality, however, involved navigating significant access restrictions. This section chronicles the key technical hurdles encountered and what we learned about responsible data collection.
2.2.1 Dealing with Google's access restrictions
Reflection: Why automated access is difficult
Google News employs sophisticated measures to detect and block automated access. Our initial attempts using Selenium-controlled browsers were quickly flagged. Through this process, we learned that Google's systems check for multiple signals including browser configuration, request patterns, and behavioral consistency.
Rather than providing a detailed guide to circumventing these protections, the key lessons were:
- Automated scraping of Google services is against their Terms of Service. We ultimately recognized this and shifted toward alternative data sources (see Section 2.3 below).
- Rate limiting matters. Even when accessing sites that permit scraping, adding reasonable delays between requests (e.g., 2–5 seconds) is essential to avoid overloading servers.
- Official APIs and data exports should always be the first choice. The time spent working around access restrictions would have been better invested in finding legitimate data sources from the start.
2.2.2 Other issues
Beyond access restrictions, we also encountered technical problems specific to the target website. Two significant issues were related to search query formatting and result pagination.
a.Issues encountered with search keywords
When searching for "S&P 500", the ampersand (&) character is interpreted by the URL as a parameter separator. My initial script would only send "S" as the search term, completely breaking the functionality. The solution was to properly encode the search term before inserting it into the URL.
from urllib.parse import quote_plus
search_term = "S&P500 OR SPX OR SP500"
search_term_encoded = quote_plus(search_term)
# Result: 'S%26P500+OR+SPX+OR+SP500'
This encodes the special characters, ensuring the server receives the exact query intended.
b.Start and end dates of the time filter
A more complex problem was scraping more than the initial 10 results displayed by Google News. Simply scrolling down the page was insufficient; it only loaded dynamic content within the first page. To access the true "next page" of results, the script needed to interact with the "More results" button. This required a robust method to find and click the button, accounting for potential variations in its label or design.
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
more_button_selectors = [
"input[value*='More']",
"a[aria-label*='More']",
"a:contains('More results')", # Requires a different lookup method
"button:contains('More')"
]
def click_more_results(driver):
for selector in more_button_selectors:
try:
# Example using CSS_SELECTOR for simplicity
more_button = driver.find_element(By.CSS_SELECTOR, selector)
if more_button.is_displayed():
driver.execute_script("arguments[0].scrollIntoView(true);", more_button)
time.sleep(1)
driver.execute_script("arguments[0].click();", more_button)
time.sleep(3)
return True
except NoSuchElementException:
continue
return False
This function attempts to locate the button using multiple possible selectors, making the pagination process more reliable.
2.2.3 Problem nsolvable for now: CAPTCHA and IP Blocks
Despite all these efforts, the most formidable obstacle remains: Google's reCAPTCHA and subsequent IP address bans. When the system determines that traffic is suspicious, it presents a CAPTCHA challenge. Automatically solving these is ethically questionable and technically very difficult. Often, the only immediate "solution" is to wait for the IP address to be released from what scraper developers colloquially call "Google jail." This highlights the inherent limitations of such projects and underscores the importance of respectful scraping practices, such as adhering to robots.txtand minimizing server load.
2.2.4 Data Output
Finally, we structure the data into a table, which includes “asset_name”, “title”, description”, “content”, “author”, “content_length”, “word_count”, “year”, “month” ,etc.. Then, we export the data to Excel. A sample output is shown below:
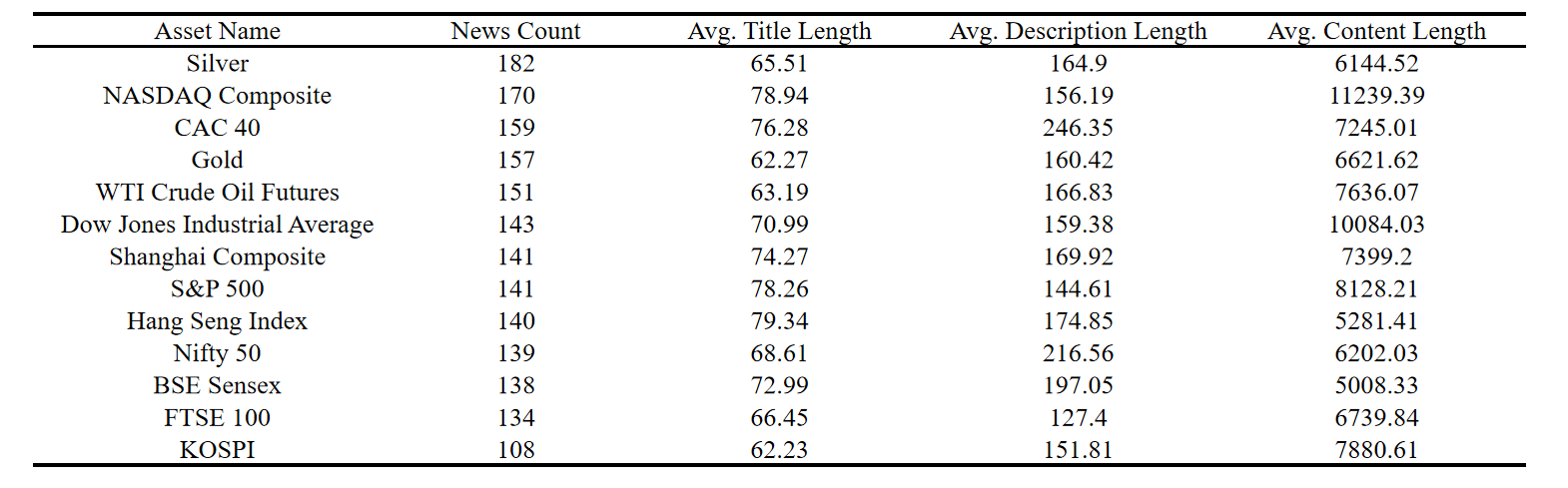
Also, here is our text data statistics table:
3.Social media data source
Based on our needs for building a financial market sentiment analysis model, social media data, in addition to mainstream news, is a crucial supplementary source. We attempted to extract relevant discussions from Reddit(especially financial subreddits like r/wallstreetbets and r/stocks) to extract retail investor sentiment.
The core crawling strategy and output summary are as follows:
3.1 Crawling Logic
We traversed multiple target subreddits and used a combination of sorting methods such as "Popular," "Newest," and "Best of the Year," while also using keywords such as "S&P 500" for searching, attempting to maximize data coverage.
3.2 Main Output Results
Data Statistics:
Total Posts: 2374
Earliest Post: 2025-01-13 05:53:56
Latest Post: 2026-01-10 19:00:15
Daily Posting Statistics:
date
2026-01-01 97
2026-01-02 100
2026-01-03 84
2026-01-04 52
2026-01-05 63
2026-01-06 114
2026-01-07 149
2026-01-08 131
2026-01-09 144
2026-01-10 391
dtype: int64
Although the crawler successfully ran and retrieved thousands of data points, the results revealed a fundamental contradiction. While the code is robust, having crawled 2000+ posts, the data's time span is only about one year, and the posts are highly concentrated around the crawl dates. This is unusable for research requiring backtesting with years of historical data (e.g., 2003-2024).
It is found out to be a limitation of the platform design. The Reddit API and page access mechanism default and prioritize returning the latest content creating an invisible barrier to deep access to historical data. This attempt clearly shows that Reddit cannot directly provide long-term, uniform historical sentiment data. It also modified terms of use of data API to explicitly prohibit usage of Reddit data for commercialized and noncommercialized machine learning training.
Other alternative channels also had shortcomings: Twitter's (X) API policy had shifted towards commercialization, making historical data acquisition costly; YouTube's comment data, due to its dynamic page loading mechanism and API quota limitations, was difficult to crawl stably and in large quantities; and labeled datasets like Sentiment140 lacked accurate timestamps, making alignment with market data difficult.
To address these issues, we experimented with several open-source toolkits on GitHub specifically for data collection and explored other platforms.
We found that StockTwits, which focuses on stock discussions, while requiring an API key application, had relatively clear and user-friendly interface rules,
potentially providing a viable alternative data source for our research.
4.Summary and Insights
4.1 Summary
This project aims to build a high-quality financial asset text dataset covering news and social media data for the period 2003–2024. The main achievements are as follows:
4.1.1 News Data
Attempts to obtain data via NewsAPI.ai revealed that its free tier has historical data time window limitations (≈90 days) and single-query return limits (100 entries), making it unsuitable for long-term needs. Subsequently, we turned to Google News web scraping. By simulating browser behavior, introducing random delays, using dynamic User-Agents, encoding queries, and implementing intelligent pagination, we successfully scraped and structured news data.
4.1.2 Social Media Data
Attempts to scrape financial discussions from Reddit yielded 2,000+ entries, but the data was heavily concentrated around recent dates, making it unsuitable for long-term analysis. We also found that platforms like Twitter and YouTube posed challenges for historical data collection due to API restrictions. Finally, StockTwits was identified as a potential alternative data source.
4.2 Insights
4.2.1 Identifying the Problem Is a Valuable Outcome
While testing the API, we systematically diagnosed and confirmed its time and quantity limitations, validating the idea that “sometimes the value of a problem lies not in being solved, but in being clearly understood.” Technical exploration involves not only finding feasible paths but also understanding why certain paths are not viable.
4.2.2 Stay Flexible and Maintain Backup Sources
Single data sources often have unexpected limitations. Shifting from APIs to scraping, and from Reddit to StockTwits, demonstrates the importance of adaptability and multi-source preparation. In complex data projects, alternative plans should be prepared in advance.
4.2.3 Data Quality Assessment Should Start Early
The “recent concentration” of Reddit data illustrates that even large volumes of data may be unusable if poorly distributed over time. Preliminary statistical analysis should be conducted during the data collection phase to avoid wasting resources later. In conclusion, this data collection process not only enhanced technical skills but also highlighted the importance of problem diagnosis, strategic adaptation, compliance awareness, and early quality assessment in data-driven projects.
Group Dice8
January 10, 2026