By Group “Semantic Fragments Synthesizer”
Motivation: Why Words Matter in Earnings Calls
In financial markets, numbers matter—but the way those numbers are explained often matters just as much. Earnings calls are a primary channel through which firm management communicates not only financial performance, but also confidence, uncertainty, and strategic intent. These qualitative elements are particularly important in the automobile industry, where demand cycles, pricing pressure, and the transition toward electric vehicles can rapidly alter market expectations.
Our group project starts from a simple question: does the tone of management’s language during earnings calls contain information that is reflected in short-term stock price reactions? To address this question, we plan to translate earnings call narratives into interpretable textual signals—such as sentiment polarity and uncertainty—and examine how these signals align with market responses around call dates.
Before conducting any sentiment analysis, however, a fundamental challenge must be addressed: how to collect clean, reliable, and reproducible earnings call text data. This first blog post documents our group’s experience in building the text collection pipeline and reflects on the technical and methodological lessons learned at this early stage of the project.
Firms and Project Scope
Our analysis focuses on three major automobile manufacturers: Ford, General Motors (GM), and Tesla. These firms represent different business models and strategic positions within the same industry, making them an ideal setting for comparative textual analysis. Their earnings calls are frequent, information-rich, and closely followed by the market.
This blog concentrates on the data collection and preprocessing stage of the project, which forms the foundation for all subsequent NLP and financial analysis.
Data Sources and Design Considerations
To obtain earnings call transcripts, our group relies on two complementary sources:
- The Motley Fool (fool.com), which provides publicly accessible earnings call transcript pages with relatively consistent HTML structures.
- S&P Capital IQ, which offers broader historical coverage through the university’s subscription but delivers content dynamically via JavaScript.
Because these platforms differ fundamentally in how content is loaded and displayed, we adopted a “two sources, two methods” strategy from the outset. This design choice allows us to balance accessibility, coverage, and data quality, while selecting the most appropriate technical tool for each source.
First Technical Challenge: Naive Scraping and Text Noise
Our initial coding attempt focused on collecting Tesla’s 2024 Q1 earnings call transcript from The Motley Fool. Using Python’s requests and BeautifulSoup, we successfully retrieved the full HTML content of the webpage. However, during the first parsing attempt, we identified a critical issue: the extracted text was not limited to the earnings call transcript itself.
The code we use is as follows:
import requests
from bs4 import BeautifulSoup
url = 'https://www.fool.com/earnings/call-transcripts/2024/04/23/tesla-tsla-q1-2024-earnings-call-transcript/'
r = requests.get('https://www.fool.com/earnings/call-transcripts/2024/04/23/tesla-tsla-q1-2024-earnings-call-transcript/', timeout=3)
all_text = s.get_text()
print(all_text)
Instead, the output included a large amount of irrelevant content, such as navigation menus, advertisements, page headers, and recommended articles. For sentiment analysis, such noise is problematic, as it can distort textual signals and undermine interpretability.
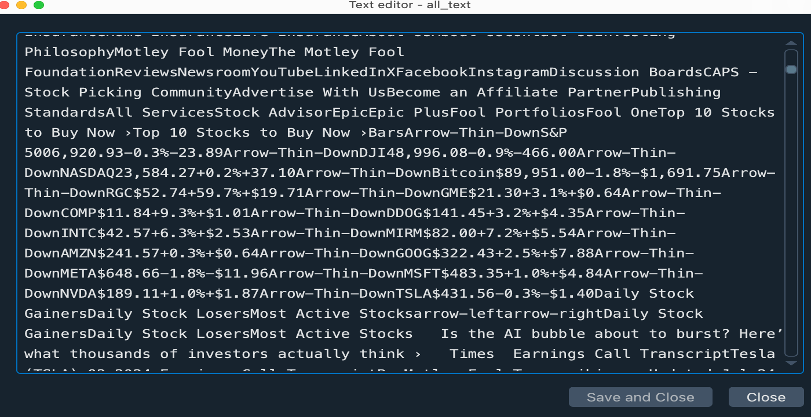
This experience revealed an important methodological insight for financial text analysis: successfully downloading a webpage does not imply that the extracted text is analytically meaningful.
Solving the Problem: DOM-Based Precision Extraction
To resolve this issue, we examined the page’s Document Object Model (DOM) structure in detail. We found that the earnings call transcript was consistently enclosed within a <div> element identified by the unique ID article-body-transcript .
By explicitly targeting this element, we were able to isolate the core transcript content while excluding non-essential webpage components. The refined extraction logic is illustrated below:
url2 = 'https://www.fool.com/earnings/call-transcripts/2024/07/24/tesla-tsla-q2-2024-earnings-call-transcript/'
r = requests.get('https://www.fool.com/earnings/call-transcripts/2024/07/24/tesla-tsla-q2-2024-earnings-call-transcript/', timeout=3)
s = BeautifulSoup(r.text, 'lxml')
transcript_div = s.find(id='article-body-transcript')
transcript_div = s.find(id='article-body-transcript')
if transcript_div:
transcript_text = transcript_div.get_text()
print(transcript_text
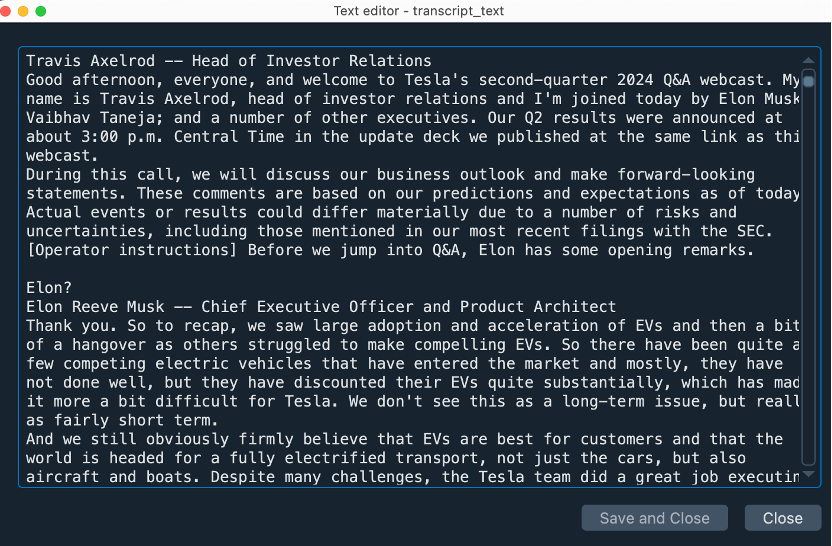
This targeted approach significantly improved data quality. The extracted text now consisted solely of the earnings call dialogue, including management remarks and analyst Q&A, providing clean and uniform raw material for NLP analysis. Applying this method consistently, we successfully retrieved accurate transcripts for all four quarters of Tesla’s 2024 earnings calls.
Second Technical Challenge: Scaling to a Ten-Year Dataset
While the refined extraction method worked well for individual quarters, it quickly became clear that manually processing one earnings call at a time would not scale to our intended ten-year dataset. Hard-coding URLs and variables for each new quarter made the workflow cumbersome, error-prone, and difficult to maintain. The underlying issue was not computational complexity, but lack of scalability and abstraction in the data collection design.
import requests
from bs4 import BeautifulSoup
# Q1 2024
url_q1 = 'https://www.fool.com/earnings/call-transcripts/2024/04/23/tesla-tsla-q1-2024-earnings-call-transcript/'
r1 = requests.get(url_q1, timeout=3)
s1 = BeautifulSoup(r1.text, 'lxml')
transcript_div_q1 = s1.find(id='article-body-transcript')
# Q2 2024
url_q2 = 'https://www.fool.com/earnings/call-transcripts/2024/07/24/tesla-tsla-q2-2024-earnings-call-transcript/'
r2 = requests.get(url_q2, timeout=3)
s2 = BeautifulSoup(r2.text, 'lxml')
transcript_div_q2 = s2.find(id='article-body-transcript')
# Q3 2024
url_q3 = 'https://www.fool.com/earnings/call-transcripts/2024/10/23/tesla-tsla-q3-2024-earnings-call-transcript/'
r3 = requests.get(url_q2, timeout=3)
s3 = BeautifulSoup(r3.text, 'lxml')
transcript_div_q3 = s3.find(id='article-body-transcript')
#Q4 2024
url_q4 = 'https://www.fool.com/earnings/call-transcripts/2024/10/23/tesla-tsla-q3-2024-earnings-call-transcript/'
r4 = requests.get(url_q4, timeout=3)
s4 = BeautifulSoup(r4.text, 'lxml')
transcript_div_q4 = s4.find(id='article-body-transcript')
if transcript_div_q1:
transcript_text_q1 = transcript_div_q1.get_text()
print(f"Q1 2024 Transcript长度: {len(transcript_text_q1)}")
if transcript_div_q2:
transcript_text_q2 = transcript_div_q2.get_text()
print(f"Q2 2024 Transcript长度: {len(transcript_text_q2)}")
if transcript_div_q3:
transcript_text_q3 = transcript_div_q3.get_text()
print(f"Q3 2024 Transcript长度: {len(transcript_text_q3)}")
if transcript_div_q4:
transcript_text_q4 = transcript_div_q4.get_text()
print(f"Q4 2024 Transcript长度: {len(transcript_text_q4)}")
Solving the Problem: Refactoring for Scalability and Reproducibility
To address this limitation, we refactored the code by storing quarterly metadata—such as year, quarter, and URL—in a structured data object and iterating over it using a loop. With this design, adding new transcripts no longer requires modifying the core extraction logic; instead, new entries are simply appended to the data structure.
This refactoring improved efficiency, reduced redundancy, and enhanced reproducibility. Each transcript is automatically retrieved and saved in a standardized format, making the dataset easy to extend and audit. More importantly, this modular pipeline aligns with best practices in empirical finance and NLP research.
import requests
from bs4 import BeautifulSoup
url_list = [
('Q1_2024', 'https://www.fool.com/earnings/call-transcripts/2024/04/23/tesla-tsla-q1-2024-earnings-call-transcript/'),
('Q2_2024', 'https://www.fool.com/earnings/call-transcripts/2024/07/24/tesla-tsla-q2-2024-earnings-call-transcript/'),
('Q3_2024', 'https://www.fool.com/earnings/call-transcripts/2024/10/23/tesla-tsla-q3-2024-earnings-call-transcript/'),
('Q4_2024', 'https://www.fool.com/earnings/call-transcripts/2025/01/29/tesla-tsla-q4-2024-earnings-call-transcript/'),
]
transcripts = {}
for quarter, url in url_list:
r = requests.get(url, timeout=3)
s = BeautifulSoup(r.text, 'lxml')
div = s.find(id='article-body-transcript')
if div:
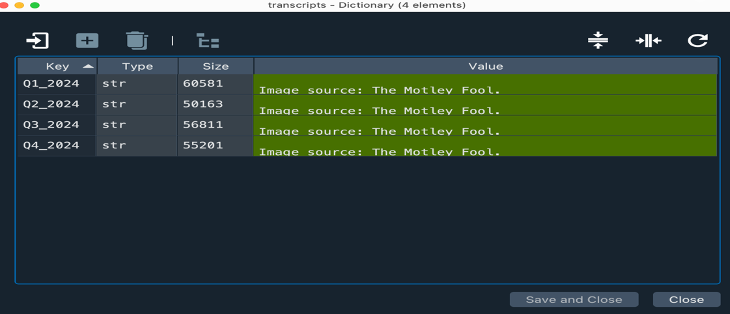
text = div.get_text()
transcripts[quarter] = text
Handling Dynamic Content: Selenium for Capital IQ
Capital IQ loads content dynamically with JavaScript, so Requests wouldn't work. We used Selenium to automate a real browser. The script acts like a virtual assistant: it opens the page, clicks buttons, waits for content to load, and saves everything for us.
Step 1: Launch & Wait for Login
It navigates to the target page and then politely pauses, allowing us to log in manually because Capital is a secure, paid platform. The code will only run until we enter ‘Continue’ in Terminal.
# The script waits after opening the login page
service = Service(executable_path='/usr/local/bin/chromedriver')
driver = webdriver.Chrome(service=service)
driver.get("https://www.capitaliq.com/CIQDotNet/Transcripts/Summary.aspx?CompanyId=27444752")
input("Enter 'Continue' after login:")
Step 2: Click ‘View All’ to load every transcript
The site only shows a few transcripts by default. Our code aims to find and click the ‘View All’ button to load every transcript. We use the CSS Selector to tell a precise location for the element ‘View All’ button on the page.
# This CSS Selector uniquely identifies the “View All” button on the page
view_all_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#_transcriptsGrid__dataGrid > tbody > tr:nth-child(27) > td > div > a:nth-child(4)"))
)
view_all_button.click()
Step 3: Save every transcript with one loop
The following script collects all links, opens each link in a new tab, saves the HTML, and then proceeds to the next link.
1.Find all transcript links
time.sleep(5)
link_elements = driver.find_elements(By.CSS_SELECTOR, "#_transcriptsGrid__dataGrid > tbody > tr > td:nth-child(3) > span > a")
transcript_links = []
for elem in link_elements:
href = elem.get_attribute('href')
if href:
transcript_links.append(href)
print(f"Found link:{href}")
print(f"Total links found: {len(transcript_links)}")
2.Create a folder to save files
desktop_path = os.path.expanduser("~/Desktop")
folder_name = f"Transcripts_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
folder_path = os.path.join(desktop_path, folder_name)
os.makedirs(folder_path, exist_ok=True)
3.Core loop: process and save each transcript in HTML version
for i, link in enumerate(transcript_links):
print(f"\nProcessing link {i+1}: {link}")
#open in new tab
driver.execute_script("window.open(arguments[0]);", link)
driver.switch_to.window(driver.window_handles[-1])
time.sleep(3)
#save html
page_html = driver.page_source
filename = f"transcript_{i+1:03d}.html"
file_path = os.path.join(folder_path, filename)
with open(file_path, 'w', encoding='utf-8') as f:
f.write(page_html)
print(f"Saved HTML: {filename}")
Why the ‘Two Sources, Two Methods’ Approach?
The reason is straightforward: different websites have different mechanisms.
- The Motley Fool presents all the content upfront. So we can simply fetch it using requests.
- Capital IQ reveals content only after the page is loaded; hence, we require Selenium to operate a real browser.
This two-method strategy empowers us to:
- Harvest more complete data: public info from The Motley Fool, plus detailed records from Capital IQ.
- Make the right choice of tool for the task at hand: instead of forcing one tool to do everything.
- Lay a strong foundation: better data from the start means more trustworthy outcomes.
After going the extra mile to gather all the data, we are now in a position to uncover the true stories behind the words.
Reflection and Next Steps: Why the Pipeline Matters
This stage of the project highlights that data collection is not a trivial preprocessing step, but a central component of financial text analysis. Seemingly minor implementation choices—such as how transcript text is isolated within a webpage or how URLs are structured and iterated over—can have significant downstream effects on sentiment measurement and empirical results.
By investing time in building a robust, scalable, and source-aware pipeline, our group reduces the risk of introducing systematic noise into the dataset and improves the credibility and interpretability of later analyses. A carefully designed pipeline also enhances reproducibility, which is particularly important in empirical finance and NLP research.
With a reliable text collection framework now in place, the next phase of the project will focus on cleaning the transcripts, separating speaker roles, and constructing interpretable sentiment and uncertainty measures. These steps will allow us to examine how managerial tone varies across firms and time, and whether such variation is reflected in short-window market reactions around earnings call dates. Having gone the extra mile to gather high-quality textual data, we are now well positioned to uncover the true stories behind the words.