By Group "GPT Chatters"
1. Project Introduction and Background
1.1 Background
Over the past decade, cryptocurrencies have evolved from a niche digital asset into a mainstream asset with high attention and significant influence in the global financial market. Different from the traditional financial assets like stocks and bonds, cryptocurrency’s prices do not depend on actual cash flows or other fundamental information about the assets themselves; their price volatility is largely influenced by market sentiment, market attention, and investor expectations.
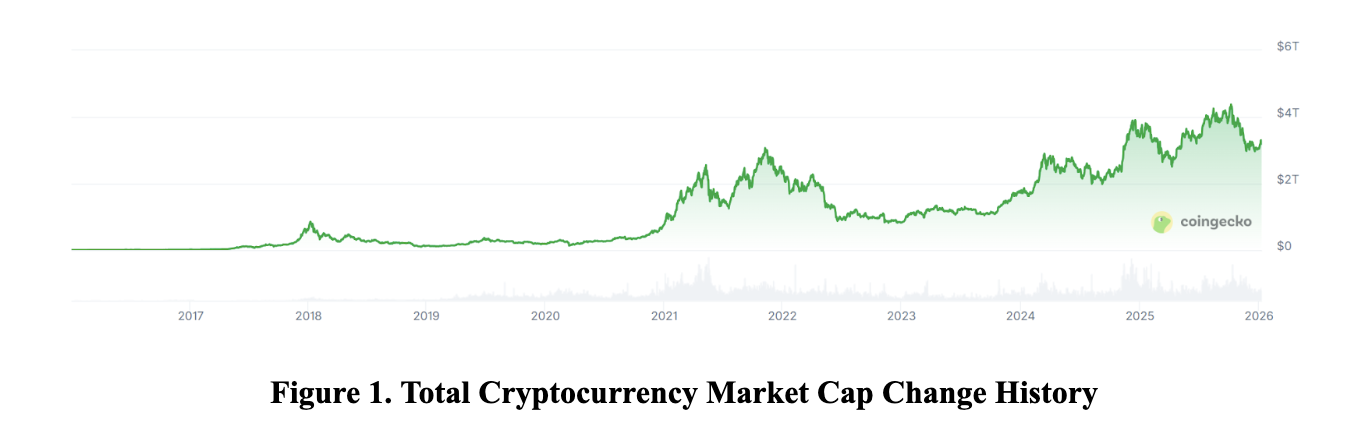
1.2 Intuition of The Relationship Between Market Sentiment and The Price Volatility of Cryptocurrency:
Intuitively, negative market sentiment, such as panic selling, hacker attacks, and declining market expectations, tends to result in higher price volatility. In addition, positive sentiment, such as market superheating, the introduction of favorable policies, and the growth of market expectations, can also lead to excessive speculation by investors, which results in significant price fluctuations. Obviously, both types of market sentiment contribute to the increase in price volatility of cryptocurrency; however, the exact impact of these two sentiments on volatility in the real market remains unclear and inconsistent.
1.3 Importance in Finance:
In the financial field, research on this issue is very important. To begin with, it helps us have a deeper and more comprehensive understanding of the irrational behavior and risk formation mechanisms in the cryptocurrency market. Moreover, for risk management, volatility prediction, and trading strategy design, distinguishing the influence strength of different sentiment types can effectively enhance the interpretability and practical performance of models, and even improve the returns of trading strategies to some extent. Last but not least, from a broader perspective, this research also provides a highly emotionally sensitive and rapidly responsive research environment for exploring the relationship between market sentiment and market volatility.
1.4 Project Overview and Research Objectives:
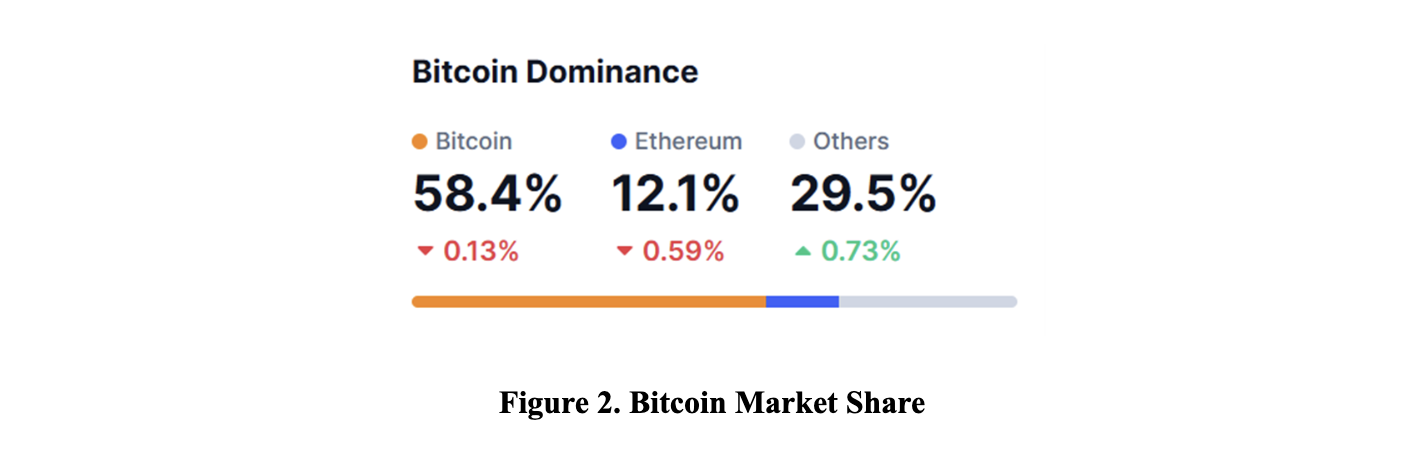
In the current cryptocurrency market, Bitcoin accounts for approximately 58.4% of the market share, making it the most critical asset in this market, which significantly influences the overall market trend. Because Bitcoin significantly outperforms other cryptocurrencies in terms of market capitalization, liquidity, and market attention, its price volatility often serves as a clear market indicator. When market sentiment shifts, Bitcoin is typically the first to reflect the change in investors’ risk appetite and then has spillover effects on other cryptocurrencies. Therefore, our project will focus on Bitcoin, using natural language processing (NLP) and text analytics to quantify the positive and negative sentiment in the texts about Bitcoin in news or social media, and using statistical methods to systematically analyze their impact on Bitcoin volatility and the relative strength of that impact.
2. Methodology
2.1 Data Source and Data Collection
2.1.1 Bitcoin News
a. CryptoPanic:
The primary source of cryptocurrency news data will be CryptoPanic, a news aggregator that redistributes headlines and short summaries from major crypto media outlets such as CoinDesk, CoinTelegraph, and Decrypt. CryptoPanic provides an official and documented API, making it a stable and reproducible data source for academic research.
The project will collect Bitcoin-related news headlines and summaries at the daily frequency. Articles will be filtered using the keyword Bitcoin to ensure topical relevance. Compared with full article texts, headlines and summaries are expected to capture the most salient information while reducing noise and simplifying daily sentiment aggregation.
b. Hugging Face:
An open-source dataset available at https://huggingface.co/datasets/edaschau/bitcoin_news/tree/main. This dataset provides historical Bitcoin-related news articles, which can be downloaded and integrated using the Hugging Face Datasets library in Python. It offers a diverse collection of articles from various outlets, allowing for broader coverage.
c.NewsData.io:
NewsData.io provides a real-time and historical news API focused on specific topics like Bitcoin. It offers structured JSON responses with headlines, summaries, and full articles from multiple sources. Access requires an API key, and data can be queried by keywords such as “Bitcoin” with date filters for daily aggregation.
d.Google News:
Google News serves as an additional aggregator for Bitcoin-related articles, accessible via its RSS feeds or the Google News API. It aggregates content from a wide range of global sources, providing headlines, summaries, and links to full articles. Data can be filtered by topic “Bitcoin” and date ranges for daily collection, enhancing diversity in perspectives.
2.1.2 Social Media
To complement professional news sentiment, the project will primarily use Reddit comment data from cryptocurrency-related subreddits such as r/Bitcoin. Reddit provides an official API, which can be accessed using the Python library PRAW. However, due to potential rate limits, access restrictions, and high noise levels, Reddit data will be treated as a core secondary source.
For further supplementation and to capture real-time public discourse, the project will consider incorporating Twitter data in subsequent phases. Twitter data can be accessed via the Twitter API (v2) or libraries like Tweepy, focusing on Bitcoin-related tweets and replies. This will provide a broader social sentiment perspective, especially for trending topics. Similar to Reddit, rate limits and noise will be managed through targeted queries.
2.1.3 Financial Data
Daily Bitcoin price data will be obtained from Yahoo Finance using the ticker BTC-USD, which provides consistent and publicly accessible historical price series. The analysis will rely on daily closing prices.
To mitigate reverse causality, sentiment indicators constructed from textual data will be lagged by one day when analyzed against volatility measures.
To support the construction of investment strategies, the project will incorporate the Bitcoin DVOL Index (Deribit Volatility Index), which measures implied volatility for Bitcoin options. This index reflects market expectations of future price swings and can inform long-short strategies (e.g., going long on low-volatility periods or short on high-volatility signals). DVOL data can be fetched from the Deribit public API, providing historical volatility readings.
2.2 Model Variables
2.2.1 Model Inputs
The input variables are daily measures of positive and negative sentiment derived from textual data. News articles related to Bitcoin are collected via APIs and web-based sources (e.g., CryptoPanic, which aggregates content from major crypto media). For each article, sentiment scores are computed using NLP-based sentiment models. These article-level scores are then aggregated across all Bitcoin-related news published on day (t−1) to obtain daily sentiment indicators.
Using lagged sentiment variables allows the model to capture how previously available information is associated with subsequent market dynamics, while mitigating concerns about reverse causality between price movements and news tone.
In addition to single-day sentiment measures, the model design also considers rolling-window sentiment inputs, such as multi-day averages of sentiment scores. The specific window length (e.g., 3-day or 7-day) is not fixed a priori and will be determined based on empirical performance during the experimental stage.
2.2.2 Model Output and Volatility Measurement
The output variable is Bitcoin market volatility on day (t), constructed from daily price data. Let (( P_t )) denote the daily closing price of Bitcoin. Daily log returns are computed as:
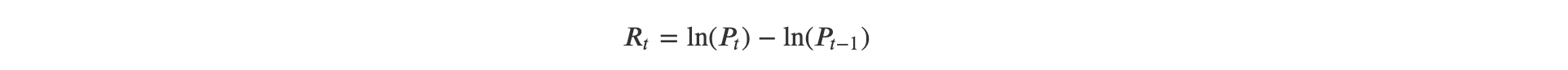
Market volatility is proxied using standard return-based measures:
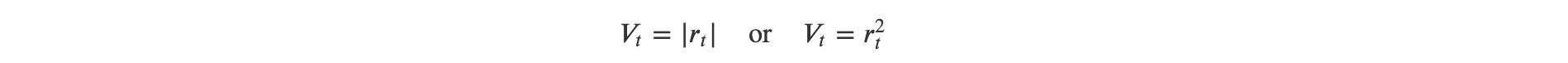
These measures capture the magnitude of daily price movements regardless of direction and are widely adopted in empirical finance as simple and effective proxies for realized volatility at the daily frequency.
2.2.3 Sentiment Modeling Considerations
The construction of sentiment scores from textual data is a key component of this study. At the initial stage, the project plans to employ lexicon-based sentiment models, such as VADER and FinBERT, due to their ease of implementation, computational efficiency, and widespread use in financial text analysis. These models allow for rapid sentiment scoring of large volumes of news text.
However, lexicon-based approaches may suffer from context insensitivity, particularly in cryptocurrency-related news where technical terminology or neutral wording may still convey strong market implications. As a result, sentiment scores obtained from these methods may contain measurement noise.
To address these limitations, more advanced approaches are considered. One option is to apply machine learning–based sentiment classification models, which may better capture complex semantic patterns but typically require large, labeled training datasets that may not be readily available in the cryptocurrency domain. Alternatively, the project considers adopting sentiment scoring methodologies proposed in existing academic literature, where validated models have been applied to financial or crypto-related texts. If necessary, large language model (LLM)–based sentiment scoring may be explored as a supplementary approach, particularly for robustness checks or qualitative validation.
2.3 Model Construction
2.3.1 Linear Regression Model
As the foundation for forecasting, Linear models are widely used in empirical finance due to their interpretability, simplicity, and ease of hypothesis testing. In our analysis, we employed linear regression models as our baseline approach to quantify the relationship between the sentiment scores derived from the text corpora of news and Bitcoin’s price volatility. Specifically, we constructed a series of ordinary least squares (OLS) regressions of the form:
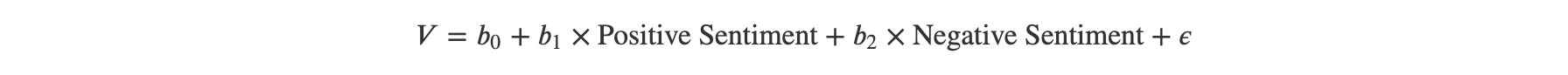
where:
- "V" is a realized volatility measure on day t,
- "Positive Sentiment" are the positive sentiment scores derived from news within sliding windows
- "Negative Sentiment" are the negative sentiment scores derived from news within sliding windows.
2.3.2 Machine Learning Models
Based on previous researches, it was highly likely that the relationship between sentiment scores and price volatility is non-linear. In response to this situation, we also explored a wide range of machine learning models beyond the classical linear regression model. The machine learning models we investigated included Random Forest, XGBoost and LightGBM.
a. Random Forest:
Random Forest is an ensemble tree-based model that builds many decision trees, lets them work simultaneously, making their own decisions and uses majority voting to determine the final prediction, rendering it to become robust to messy noises. In the context of Bitcoin sentiment analysis, it can automatically capture non-linear effects between multiple sentiment indicators and market variables without extensive feature engineering. Its stability and resistance to overfitting make it a strong non-parametric baseline for volatility forecasting when linear assumptions are insufficient.
b. XGBoost:
XGBoost is a powerful gradient boosting framework that builds trees sequentially, where each subsequent tree corrects the errors of previous ones. This learning strategy enables the model to capture the intricate patterns and subtle non-linear dependencies in financial time series. These characteristics often allow the model to achieve superior predictive performances compared to simpler ensembles. Its built-in regularization and flexibility make it particularly suited for modeling the nuanced relationship between sentiment scores and future Bitcoin volatility.
c. LightGBM:
LightGBM is an optimized gradient boosting model designed for efficiency and scalability on large datasets, using a leaf-wise tree growth strategy and histogram-based splitting. It is especially appropriate when iterating over many hyperparameter configurations or when working with extensive news-derived feature sets that would be computationally heavy for other boosting implementations. Using a large dataset with more than 100k lines of items, LightGBM becomes favorably suitable for our research and is currently presumed to be our top choice among these machine learning models. It efficiently offers faster training and lower memory consumption while still capturing complex feature interactions.
2.4 Model Summarization
In our methodology design, we developed a sentiment-driven framework to forecast Bitcoin price volatility by systematically transforming unstructured news text into predictive signals. We systematically collected Bitcoin-related news from multiple sources and applied NLP-based sentiment analysis models to construct daily aggregated positive and negative sentiment scores. Using these lagged sentiment measures, we adopted a two-stage modeling strategy. First, we employed linear regressions as a benchmark to test economic intuition and directional effects. However, due to the limitations of linear assumptions, we extended our analysis to non-linear machine learning models as well — including Random Forest, XGBoost, and LightGBM — to capture complex interactions and nonlinear dependencies between sentiment and market dynamics. Finally, we evaluated the performances for all our models through out-of-sample forecasts, assessed their consistencies between predicted and actual volatility, and eventually selected the model with the strongest predictive power as our proposed model.
3. Problems and Challenges
Using news and social media sentiment to predict Bitcoin volatility sounds intuitive, but it comes with real challenges. Not all posts matter equally: a viral tweet from a well-known account can move markets, while most comments add little signal. Aggregating everything the same way often introduces noise rather than insight. Timing is another issue. Sentiment is usually measured daily, even though news and social media react in real time, which can blur short-lived market reactions. On the modeling side, Bitcoin volatility is highly unstable, with sudden regime shifts and extreme movements that simple or static models struggle to handle. Relying on sentiment alone also ignores valuable information from prices, volume, and market structure. Finally, it’s hard to tell cause from effect—markets influence news just as much as news influences markets.
4. Future Research Directions
Future work can improve on these limitations in several ways. Sentiment measures could weight posts by influence, engagement, or relevance to major events instead of treating all content equally. Using intraday or mixed-frequency data may better match how information actually reaches markets. Combining sentiment with technical indicators like volatility, volume, or momentum can also lead to more stable predictions. On the modeling side, sequence-based approaches such as LSTMs or Transformers can capture how sentiment and volatility evolve over time, while attention mechanisms help identify which news really matters. Finally, testing models across different market regimes and using more robust tuning strategies can make results more reliable and easier to trust.