Key points when performing pre-processing for earnings call transcripts
In our first blog post, we dive into the nuances of conducting pre-processing on textual data from earnings call transcripts, and the different methods to do so, inspired by the perspective that:
NLP is 80% preprocessing
When dealing with earnings call transcripts as a data source, it is dangerous to simply treat them as a whole document in its entirety, or to treat them exactly the same as other textual data sources such as equity research reports or company filings. In practice, earnings call transcripts have common layouts and properties that make them a unique source of textual information. They can be regarded as semi-structured data, containing recurring formatting conventions across many different companies, with many 'boilerplate' passages that usually do not contain much meaningful predictive information (if applied to a predictive model in a quant trading strategy). A quick look on Stack Overflow shows that in the context of programming, boilerplate code is defined as follows:
Boilerplate code is any seemingly repetitive code that shows up again and again
Similarly, in earnings call transcripts there is a substantial amount of 'boilerplate' text including greetings, 'thank you's and opening remarks such as 'I am excited to speak to you all today'. Eliminating these passages usually leads to the textual data having less noise, and thus a cleaner resulting trading signal when applied to a machine learning prediction model.
A typical transcript contains two sections with materially different information content:
- Presentation: prepared remarks from management (more scripted and often aligned to the firm’s intended narrative, meaning that there may be exaggerations).
- Q&A: interactive dialogue between analysts and executives (more reactive and granular, sometimes revealing performance uncertainty or operational details that upper management may have wanted to hide or exclude in the Presentation section).
These separations and contextual differences are not merely cosmetic. When Presentation and Q&A are pooled into a single document, downstream signals (e.g. sentiment, forward-looking statements, topics, summaries) may be diluted or distorted. In our workflow, a main theme is that preprocessing choices may dominate model choice: they determine which exact textual source is available to the model, how it is segmented, and what information is emphasized by tokenization and truncation constraints.
Setup: assumptions and a minimal transcript example
To keep the examples self-contained and reproducible, we assume upstream steps already removed HTML tags and obvious regex junk. The example transcript (generated by an LLM) below captures common transcript elements: operator lines, boilerplate text, and then Presentation and Q&A content.
example_transcript = '''
Operator: Good day and welcome to the Q4 2025 earnings call.
Safe Harbor Statement: This call contains forward-looking statements subject to risks and uncertainties.
Presentation
CEO: We delivered strong revenue growth this quarter and expect margins to improve next year.
CFO: We will continue investing in our platform and we anticipate higher operating leverage.
Q&A
Analyst: Can you comment on pricing pressure in Europe?
CEO: We expect pricing to stabilize, but we are monitoring demand closely.
Analyst: What are your capex plans for FY2026?
CFO: We plan to reduce capex as a percentage of revenue over time.
'''
print(example_transcript[:300], "...")
Insight 1: ECTSum-inspired cleaning and lightweight baselines
Our starting point for “content-preserving cleaning” was inspired by the open-source code accompanying ECTSum: A New Benchmark Dataset for Bullet Point Summarization of Long Earnings Call Transcripts (Mukherjee et al., 2022). The key idea is to remove high-frequency, low-information boilerplate (operator scripts, “turn to slide…” guidance) and to mask structured artifacts (phone numbers, timestamps, fiscal shorthand) that can create spurious correlations.
1.1 ECTSum-style phrase filtering + masking (closer to our implementation)
In our codebase, we maintained a fairly long EXCLUDE phrase list. The snippet below shows the same logic, but with a shorter list so it remains readable in a blog format.
import re
import pandas as pd
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True)
IN_PARQ = "preprocessing_data/confcall_sentences_sm.parquet"
OUT_PARQ = "preprocessing_data/confcall_sentences_sm_clean.parquet"
df = pd.read_parquet(IN_PARQ)
EXCLUDE = [
"forward-looking", "subject to risks", "safe harbor",
"operator:", "please refer to", "turn to slide", "press release",
"sec's website", "replay will be available",
]
# Patterns for masking
PHONE = re.compile(r"\b\d{3}[-.\s]?\d{3}[-.\s]?\d{4}\b")
TIME = re.compile(r"\b\d{1,2}:\d{2}\s?(AM|PM)?\b", flags=re.I)
YEAR_S = re.compile(r"\bfy\s?\d{2,4}\b", flags=re.I) # FY2026, FY 26, etc.
TXTNUM = re.compile(r"\b(q[1-4]|10-?k|10-?q|8-?k)\b", flags=re.I) # Q2, 10-K, etc.
def mask_text(text: str) -> str:
text = PHONE.sub("[PHONENUM]", text)
text = TIME.sub("[TIME]", text)
text = YEAR_S.sub("[YEAR]", text)
text = TXTNUM.sub("[TXT-NUM]", text)
return re.sub(r"\s+", " ", text).strip()
# Remove EC-specific boilerplate phrases
mask_excl = ~df["sentence_text"].str.lower().parallel_apply(
lambda s: any(phrase in s for phrase in EXCLUDE)
)
df = df[mask_excl]
# Apply masking
df["sentence_text"] = df["sentence_text"].parallel_apply(mask_text)
# Drop very short lines
df = df[df["sentence_text"].str.split().str.len() >= 4]
df = df[~df["sentence_text"].str.contains(r"\[PHONENUM\]", regex=True)]
df.to_parquet(OUT_PARQ, index=False)
print("Saved →", OUT_PARQ, "shape:", df.shape)
This style of cleaning is transparent and easy to audit: we can read the rules and understand exactly what is removed. The trade-off is that phrase lists and masking patterns can be brittle across transcript vendors, so we generally add sanity checks and monitor failure cases rather than assuming a single list works universally.
1.2 “Minimal” baselines used for ablations
In our codebase for testing, we found it useful to keep at least two lightweight baselines for ablations:
1) Phrase-only filtering:
import pandas as pd
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True)
df = pd.read_parquet("preprocessing_data/confcall_sentences_sm.parquet")
mask_excl = ~df["sentence_text"].str.lower().parallel_apply(
lambda s: any(phrase in s for phrase in EXCLUDE)
)
df = df[mask_excl]
df.to_parquet("preprocessing_data/confcall_sentences_sm_nostop.parquet", index=False)
2) spaCy stopword removal (a stopword-stripping baseline used to test whether function words materially change downstream results):
import spacy
nlp = spacy.blank("en")
STOP_WORDS = nlp.Defaults.stop_words
def remove_spacy_stopwords(text: str) -> str:
doc = nlp.make_doc(text)
return " ".join(tok.text for tok in doc if tok.is_alpha and tok.lower_ not in STOP_WORDS)
df["sentence_no_stop"] = df["sentence_text"].map(remove_spacy_stopwords)
Insight 2: Segmenting into Presentation vs Q&A
Many transcript datasets already provide presentation_text and qa_text. When they do, we treat this as the "ground truth" section split and build our sentence-level datasets separately for each section. When the raw transcript is a single string, a conservative rule-based split around section headers is often sufficient as a first pass.
import re
from dataclasses import dataclass
@dataclass
class CallSections:
presentation: str
qa: str
def split_presentation_qa(raw_text: str) -> CallSections:
pres_pat = r"\bPresentation\b"
qa_pat = r"\b(Q\s*&\s*A|Q\s*and\s*A|Questions?\s*and\s*Answers?)\b"
pres_m = re.search(pres_pat, raw_text, flags=re.I)
qa_m = re.search(qa_pat, raw_text, flags=re.I)
if not pres_m and not qa_m:
return CallSections(presentation=raw_text.strip(), qa="")
if pres_m and qa_m and pres_m.start() < qa_m.start():
return CallSections(
presentation=raw_text[pres_m.end():qa_m.start()].strip(),
qa=raw_text[qa_m.end():].strip()
)
# Conservative fallback (e.g., missing Presentation marker)
return CallSections(
presentation=raw_text[:qa_m.start()].strip() if qa_m else raw_text.strip(),
qa=raw_text[qa_m.end():].strip() if qa_m else ""
)
Section segmentation is interesting because f the goal is to measure “market-relevant surprise,” we often expect the Q&A to contain more incremental information. It is longer as well, compared to the Presentation. At the same time, management guidance is frequently concentrated in prepared remarks, so removing the Presentation section entirely can also discard predictive language. In practice, we treat “Presentation-only,” “Q&A-only,” and “All” as separate preprocessing variants to be compared downstream.
Insight 3: Forward-looking statement labeling with FinBERT-FLS
Forward-looking statements (FLS) provide a natural channel for extracting expectations, guidance, and conditional language. Our pipeline labels at the sentence level using yiyanghkust/finbert-fls, with GPU micro-batching and chunked parquet I/O (to avoid losing progress on long runs).
Below is a condensed version of our approach using AutoTokenizer / AutoModelForSequenceClassification.
import gc
import torch
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
from pathlib import Path
from transformers import AutoTokenizer, AutoModelForSequenceClassification
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
MODEL_NAME = "yiyanghkust/finbert-fls"
BATCH_SIZE = 64
MAX_LEN = 128
CHUNK_ROWS = 50_000
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME).to(DEVICE).eval()
def predict_fls(df: pd.DataFrame) -> list[int]:
preds = []
for start in range(0, len(df), BATCH_SIZE):
texts = df["sentence_text"].iloc[start:start + BATCH_SIZE].tolist()
enc = tokenizer(texts, padding=True, truncation=True, max_length=MAX_LEN, return_tensors="pt").to(DEVICE)
with torch.no_grad(), torch.cuda.amp.autocast(enabled=(DEVICE == "cuda")):
logits = model(**enc).logits
preds.extend(logits.argmax(dim=1).cpu().tolist())
del enc, logits
if DEVICE == "cuda":
torch.cuda.empty_cache()
return preds
def write_chunk(df: pd.DataFrame, writer: pq.ParquetWriter | None, out_path: Path) -> pq.ParquetWriter:
table = pa.Table.from_pandas(df, preserve_index=False)
if writer is None:
writer = pq.ParquetWriter(out_path, table.schema)
writer.write_table(table)
return writer
IN_PARQ = Path("preprocessing_data/confcall_sentences_sm.parquet")
OUT_ALL = Path("preprocessing_data/fls_all.parquet")
OUT_SPEC = Path("preprocessing_data/fls_spec.parquet")
OUT_NSP = Path("preprocessing_data/fls_nspec.parquet")
OUT_NON = Path("preprocessing_data/fls_non.parquet")
writers = dict(all=None, spec=None, nspec=None, non=None)
pfile = pq.ParquetFile(IN_PARQ)
for batch in pfile.iter_batches(batch_size=CHUNK_ROWS):
chunk = batch.to_pandas()
chunk["fls_label_id"] = predict_fls(chunk)
writers["all"] = write_chunk(chunk, writers["all"], OUT_ALL)
writers["spec"] = write_chunk(chunk[chunk["fls_label_id"] == 2], writers["spec"], OUT_SPEC)
writers["nspec"] = write_chunk(chunk[chunk["fls_label_id"] == 1], writers["nspec"], OUT_NSP)
writers["non"] = write_chunk(chunk[chunk["fls_label_id"] == 0], writers["non"], OUT_NON)
del chunk
gc.collect()
for w in writers.values():
if w is not None:
w.close()
This produces multiple datasets that can be used as separate perspectives of the same call: all sentences, specific-FLS sentences, non-specific-FLS sentences, and non-FLS sentences. These views are convenient for downstream ablations: we can test whether predictive content concentrates in a narrower subset of language.
Insight 4: Sentence segmentation → embeddings → aggregation back to call level
A frequent practical constraint is that earnings calls are long, while many encoder models have limited context windows. Our approach therefore computes sentence embeddings and aggregates them back to a call-level representation.
For readability here, we refer to specific call identifiers it as unique_id.
4.1 Sentence segmentation with spaCy (Presentation / Q&A)
import spacy
import pandas as pd
from tqdm.auto import tqdm
nlp = spacy.load("en_core_web_sm", disable=["ner", "tagger"])
def is_valid_sentence(s: str) -> bool:
s = s.strip()
return len(s) >= 20 and sum(ch.isalpha() for ch in s) >= 10
def split_sentences(text: str, unique_id: str, section: str) -> list[dict]:
doc = nlp(text)
out = []
for i, sent in enumerate(doc.sents):
s = sent.text.strip()
if is_valid_sentence(s):
out.append({
"unique_id": unique_id,
"section": section, # "presentation" or "qa"
"sentence_id": i,
"sentence_text": s,
})
return out
# df_calls must include: unique_id, presentation_text, qa_text
rows = []
for _, r in tqdm(df_calls.iterrows(), total=len(df_calls)):
rows += split_sentences(r["presentation_text"], r["unique_id"], "presentation")
rows += split_sentences(r["qa_text"], r["unique_id"], "qa")
df_sent = pd.DataFrame(rows)
df_sent.to_parquet("preprocessing_data/confcall_sentences_sm.parquet", index=False)
4.2 Sentence-BERT embeddings with batch processing and call-level aggregation
This is a compact version of our bucket-based aggregation logic (sum embeddings per (unique_id, section), then divide by count).
import gc
import numpy as np
import torch
import pyarrow.parquet as pq
from sentence_transformers import SentenceTransformer
from tqdm.auto import tqdm
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
MODEL_NAME = "sentence-transformers/all-mpnet-base-v2"
BATCH_SIZE = 256
st_model = SentenceTransformer(MODEL_NAME, device=DEVICE)
emb_dim = st_model.get_sentence_embedding_dimension()
bucket = {} # (unique_id, section) -> [sum_vec, count]
pq_file = pq.ParquetFile("preprocessing_data/confcall_sentences_sm.parquet")
rows_total = pq_file.metadata.num_rows
def add_to_bucket(unique_ids, sections, embeds):
for u, s, v in zip(unique_ids, sections, embeds):
key = (u, s)
if key not in bucket:
bucket[key] = [np.zeros(emb_dim, np.float32), 0]
bucket[key][0] += v.astype(np.float32)
bucket[key][1] += 1
with tqdm(total=rows_total, desc="encode", unit="rows") as bar:
for batch in pq_file.iter_batches(batch_size=50_000):
df = batch.to_pandas()
embeds = st_model.encode(
df["sentence_text"].tolist(),
batch_size=BATCH_SIZE,
convert_to_numpy=True,
show_progress_bar=False,
)
add_to_bucket(df["unique_id"].tolist(), df["section"].tolist(), embeds)
bar.update(len(df))
del df, embeds
gc.collect()
# Aggregate back to call level
out_rows = []
for (u, sec), (vsum, cnt) in bucket.items():
out_rows.append({
"unique_id": u,
"section": sec,
"embedding": (vsum / max(cnt, 1)).tolist()
})
pd.DataFrame(out_rows).to_parquet("preprocessing_data/call_embeddings.parquet", index=False)
Aggregation somewhat defines what it means to 'represent' a call. Mean aggregation is a reasonable baseline, and more complex pooling (section-weighting, topic-weighting) can be introduced as additional variants in future analysis.
Insight 5: Topic classification with RoBERTa + LoRA, then passage construction and passage embeddings
We experimented with topical structure in two stages:
1) Sentence-level topic classification using a RoBERTa classifier fine-tuned with LoRA, and 2) Passage construction by merging consecutive sentences with the same topic, then embedding passages using multiple models.
5.1 Fine-tuning with LoRA
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model
import torch
BASE_MODEL = "roberta-base"
NUM_LABELS = 8 # set to your topic label count
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL)
model = AutoModelForSequenceClassification.from_pretrained(BASE_MODEL, num_labels=NUM_LABELS)
lora_cfg = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.05,
target_modules=["query", "value"],
task_type="SEQ_CLS",
)
model = get_peft_model(model, lora_cfg)
args = TrainingArguments(
output_dir="checkpoints/roberta_topic_lora",
per_device_train_batch_size=32,
learning_rate=2e-5,
num_train_epochs=2,
fp16=torch.cuda.is_available(),
)
trainer = Trainer(model=model, args=args, train_dataset=train_dataset, eval_dataset=eval_dataset)
trainer.train()
5.2 Inference + merging consecutive topics into passages
import pandas as pd
from pathlib import Path
from transformers import pipeline, AutoModelForSequenceClassification, AutoTokenizer
from peft import PeftModel
SENTENCE_FILE = "preprocessing_data/confcall_sentences_sm.parquet"
OUT_DIR = Path("topic_passages")
OUT_DIR.mkdir(parents=True, exist_ok=True)
base = AutoModelForSequenceClassification.from_pretrained(BASE_MODEL, num_labels=NUM_LABELS)
model = PeftModel.from_pretrained(base, "checkpoints/roberta_topic_lora").eval()
topic_pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, batch_size=64, truncation=True)
df_sent = pd.read_parquet(SENTENCE_FILE).sort_values(["unique_id", "sentence_id"])
preds = topic_pipe(df_sent["sentence_text"].tolist())
df_sent["topic"] = [p["label"] for p in preds]
passage_rows = []
for unique_id, group in df_sent.groupby("unique_id"):
cur_topic, cur_texts, passage_id = None, [], 0
for sent, topic in zip(group["sentence_text"], group["topic"]):
if cur_topic is None:
cur_topic, cur_texts = topic, [sent]
elif topic == cur_topic:
cur_texts.append(sent)
else:
passage_rows.append({
"unique_id": unique_id,
"passage_id": passage_id,
"topic": cur_topic,
"passage": " ".join(cur_texts),
})
passage_id += 1
cur_topic, cur_texts = topic, [sent]
passage_rows.append({
"unique_id": unique_id,
"passage_id": passage_id,
"topic": cur_topic,
"passage": " ".join(cur_texts),
})
pass_df = pd.DataFrame(passage_rows)
pass_df.to_parquet(OUT_DIR / "roberta_passages.parquet", index=False)
# Optionally: write per-topic files (mirrors our code)
for lab, sub in pass_df.groupby("topic"):
sub.to_parquet(OUT_DIR / f"roberta_passages_{lab}.parquet", index=False)
5.3 Embedding topic passages with multiple models
import pandas as pd
from sentence_transformers import SentenceTransformer
pass_df = pd.read_parquet("topic_passages/roberta_passages.parquet")
texts = pass_df["passage"].tolist()
st = SentenceTransformer("sentence-transformers/all-mpnet-base-v2", device=DEVICE)
embs_mean = st.encode(texts, batch_size=256, convert_to_numpy=True, show_progress_bar=True)
out = pass_df[["unique_id", "passage_id", "topic"]].copy()
for j in range(embs_mean.shape[1]):
out[str(j)] = embs_mean[:, j].astype("float32")
out.to_parquet("topic_passages/passages_mpnet_mean.parquet", index=False)
For long contexts, a long-context encoder (e.g., Longformer) can be used with windowing.
Passage construction produces more coherent units than isolated sentences and helps align downstream analysis with interpretation (e.g., “pricing” passages vs “guidance” passages). It also provides a natural way to test whether topic-conditioned signals contain incremental predictive content.
Insight 6: DeepSeek API for Q&A pair extraction and structured summaries
We used DeepSeek API calls for two tasks that are difficult to solve reliably with purely rule-based code:
1) splitting raw Q&A into explicit question/answer pairs, and 2) generating topic summaries and section summaries in structured JSON.
The implementation below follows our scripts closely: JSON-mode responses when possible, and defensive parsing (strip code fences, clean invalid newlines, etc.).
6.1 Q&A pair extraction (DeepSeek chat → JSON parsing → parquet)
import os, re, json, ast
import pandas as pd
from openai import OpenAI
from tqdm.auto import tqdm
client = OpenAI(
api_key=os.environ["DEEPSEEK_API_KEY"],
base_url="https://api.deepseek.com"
)
BAD_QUOTE_RE = re.compile(r'(?<!\\)"')
BAD_NL_RE = re.compile(r'(?<!\\)\n')
def safe_json_loads(raw: str):
try:
return json.loads(raw)
except json.JSONDecodeError:
cleaned = BAD_NL_RE.sub(" ", raw)
cleaned = BAD_QUOTE_RE.sub("'", cleaned)
try:
return json.loads(cleaned)
except json.JSONDecodeError:
try:
return ast.literal_eval(cleaned)
except Exception:
return None
def deepseek_chat(prompt: str, expect_json: bool = False, max_tokens: int = 4096) -> str:
kwargs = {
"model": "deepseek-chat",
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.3,
"max_tokens": max_tokens,
}
if expect_json:
kwargs["response_format"] = {"type": "json_object"}
rsp = client.chat.completions.create(**kwargs)
return rsp.choices[0].message.content.strip()
EXTRACT_PROMPT = """
Extract Q&A pairs from the transcript below.
Return JSON with key "transcript" as a list of objects:
[{ "question": "...", "answer": "...", "speaker_q": "...", "speaker_a": "..." }, ...].
Transcript:
"""
def extract_pairs(raw_qa: str) -> list[dict]:
raw = deepseek_chat(EXTRACT_PROMPT + raw_qa, expect_json=True)
raw = re.sub(r"^```(?:json)?\s*|\s*```$", "", raw.strip(), flags=re.I)
data = safe_json_loads(raw)
if isinstance(data, dict) and "transcript" in data:
data = data["transcript"]
return data if isinstance(data, list) else []
df_calls = pd.read_parquet("data/confcall_transcript.parquet")
records = []
for _, row in tqdm(df_calls.iterrows(), total=len(df_calls), desc="DeepSeek Q/A"):
for p in extract_pairs(row["qa_text"]):
p["unique_id"] = row["unique_id"]
records.append(p)
pd.DataFrame(records).to_parquet("QASplit_data/qa_pairs.parquet", index=False)
6.2 Topic summaries and section summaries
SUMMARY_PROMPT = """
Summarize the transcript below.
Return JSON with keys:
- "presentation_summary": string
- "qa_summary": string
- "topics": [{ "topic": "...", "summary": "..." }, ...]
Transcript:
"""
def summarize_sections(pres_text: str, qa_text: str) -> dict:
raw = deepseek_chat(
SUMMARY_PROMPT + "\n\n[PRESENTATION]\n" + pres_text + "\n\n[Q&A]\n" + qa_text,
expect_json=True,
max_tokens=2048
)
raw = re.sub(r"^```(?:json)?\s*|\s*```$", "", raw.strip(), flags=re.I)
data = safe_json_loads(raw)
return data if isinstance(data, dict) else {}
API-based components are useful, but they introduce dependencies on prompt stability, response formatting, and external service availability. For our workflows, deterministic fallbacks and systematic logging (prompt version, model name, error counts) help keep results interpretable and reproducible.
Evaluating preprocessing choices in a predictive setting
The goal is not only to “clean text,” but to test whether different preprocessing variants produce different signals and whether those signals predict outcomes such as future returns, volatility, or abnormal returns around events.
A practical framework:
- Define preprocessing variants
p in {1,...,P}(e.g., Presentation-only vs Q&A-only; with vs without ECTSum cleaning; sentence embeddings vs topic-passage embeddings; rule-based vs DeepSeek Q&A pairs). - For each variant, compute a numeric signal
s_{i,t}^{(p)}for firmiat timet. - Compare predictive power using regression tests and/or portfolio sorts, holding all non-text components fixed.
Cross-sectional regression (Fama–MacBeth style)
For each time period t, estimate:
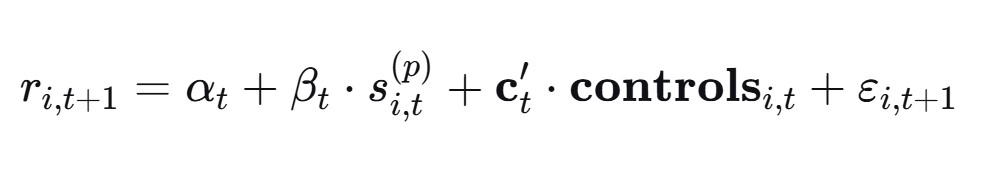
Then evaluate the time-series average of B_t (with an appropriate standard error, e.g., Newey–West if needed). This isolates whether the signal derived from preprocessing variant p has incremental predictive content beyond controls.
Combining multiple NLP-derived signals
If multiple signals are constructed (e.g., FLS intensity, topic-frequency shifts, summary sentiment), a simple combined factor can be:
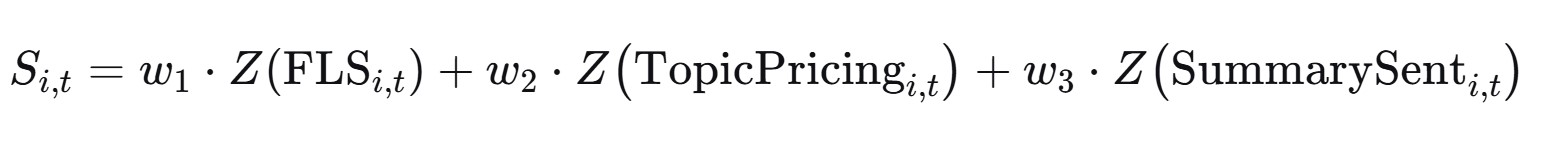
where z(.) denotes a cross-sectional z-score normalization and weights can be equal-weighted, learned via rolling regressions, or tuned via out-of-sample objectives.
Caveats
To compare preprocessing methods fairly, all other choices should be fixed:
- universe, horizon, lags (avoid look-ahead),
- the same labeling/classification model (unless model choice is the variable under study),
- the same evaluation window,
- consistent handling of missing transcripts and unusually short calls.
Closing remarks
A consistent takeaway is that preprocessing is not only an engineering step - it implicitly defines the information set presented to the model. In earnings calls, respecting transcript structure (Presentation vs Q&A), removing boilerplate efficiently, and stabilizing units of analysis (sentences → passages) can materially change the resulting signals and their interpretability.
At the same time, rule-based methods (splits, phrase lists, masking) can fail in edge cases, and API-based methods can drift if prompts or model behavior change. A robust research pipeline benefits from monitored checks, deterministic fallbacks, and careful documentation of each preprocessing choice, especially when the goal is to attribute differences in predictive performance to preprocessing decisions rather than uncontrolled pipeline variation.