Introduction: Forming the Team and Choosing a Direction
At the beginning of the project, the direction was not immediately clear. Our group was formed through random assignment, and the first challenge was simply understanding each member’s background and strengths. Fortunately, our team leader quickly organized a group chat and scheduled an initial Zoom meeting, which helped establish momentum early on.
During this meeting, we briefly introduced ourselves, focusing on our academic backgrounds and technical skills. Most group members are FinTech students with undergraduate training in economics, mathematics, or computer science. The team leader presented a mind map outlining several potential project ideas, which provided a useful starting point for discussion. After evaluating feasibility, relevance to the course, and time constraints, we converged on a single project idea that all members agreed was both realistic and meaningful.
This blog post documents our initial reasoning, project scope, and early progress, while also reflecting on challenges we anticipate as the project develops.
1. Project Overview and Motivation
Our project focuses on replicating and extending the work of Petropoulos and Siakoulis (2021):
Can central bank speeches predict financial market turbulence? Evidence from an adaptive NLP sentiment index analysis using XGBoost machine learning technique
(ScienceDirect link)
The original study investigates whether the content of central bank speeches contains predictive information about future financial market turbulence. The authors argue that central bank speeches aggregate both quantitative assessments and qualitative judgments regarding macroeconomic conditions, monetary policy, and financial stability. By applying natural language processing (NLP) techniques and machine learning models, they construct sentiment indices that aim to forecast periods of financial distress.
More specifically, the paper builds sentiment dictionaries—both predefined and data-driven—and combines them using machine learning methods to generate a global sentiment index. This index is then evaluated for its ability to signal future market turmoil, defined as significant declines in equity markets over a fixed horizon.
We chose this project for three main reasons. First, replication provides a clear roadmap, which is particularly important given the limited timeframe of the course. Second, some group members already have experience with machine learning models similar to those used in the paper, making replication technically feasible. Third, the project is highly practical and offers valuable exposure to real-world applications of NLP and machine learning in finance.
2. Understanding the Original Paper
To better frame our replication effort, we briefly summarize the key components of the original study.
2.1 Data Collection
To analyze central bank communication, the authors collect a large corpus of central bank speeches along with relevant metadata from the Bank for International Settlements (BIS). This textual dataset is enriched with financial market data, including historical time series of the S&P 500 index and the VIX volatility index. These financial variables are used both in constructing sentiment dictionaries and in evaluating the predictive performance of the resulting sentiment indices.
2.2 Machine Learning Framework
Machine learning methods play two major roles in the paper. First, the authors employ Extreme Gradient Boosting (XGBoost) to create a self-evolving dictionary. This process starts from a predefined set of words that are qualitatively labeled as positive or negative and expands the dictionary based on various linguistic and statistical criteria, such as topic relevance and syntactic features.
Second, several machine learning algorithms are used to combine signals from multiple sentiment dictionaries into a single global sentiment index. These algorithms include Random Forests, XGBoost, Support Vector Machines, and Deep Neural Networks. Given time constraints, our replication will likely focus on a subset of these models, depending on progress.
2.3 Natural Language Processing Pipeline
Since this project is conducted within an NLP course, the text-processing pipeline is of particular importance. The paper outlines a multi-stage workflow, illustrated in figure below:
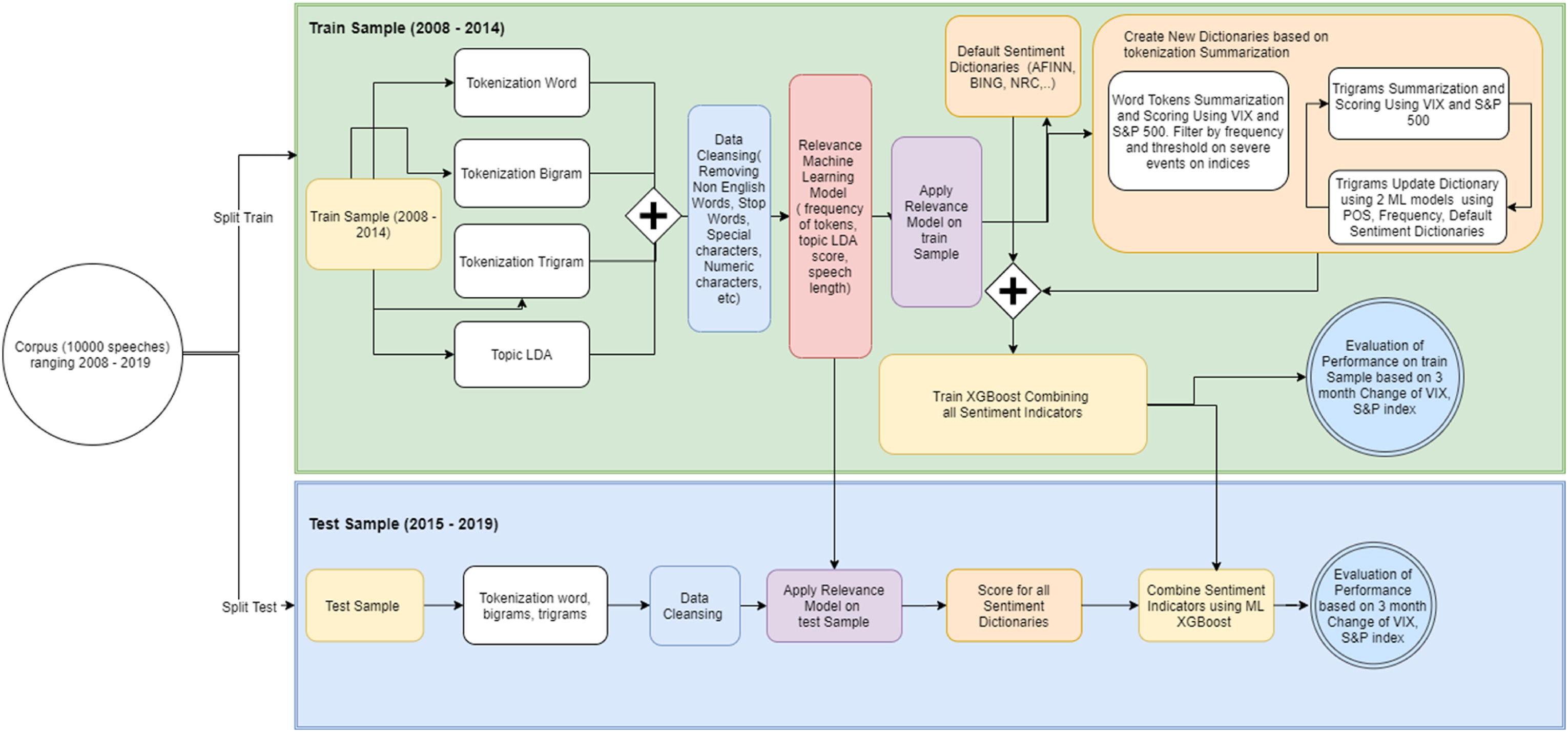
In summary, the speech corpus is split into training and testing sets, tokenized, and passed through a relevance topic filter that automatically identifies speeches with financial and economic content. Sentiment dictionaries are then applied to generate individual sentiment indicators, which are aggregated into a global sentiment index.
This index serves as the input to an early warning system, where financial distress events are defined as binary outcomes. In the article, they define financial distress events as "an S&P 500 decline of more than 8% over a three-month horizon". At a high level, the problem is framed as a classification task.
At this stage, we deliberately avoid going into further technical detail. On the one hand, implementation has not yet begun; on the other hand, more detailed discussion will be more appropriate for future blog posts once empirical results are available.
3. Progress So Far
During our initial meeting, we divided responsibilities among group members. Two members focused on data collection, one on data cleaning and manipulation, and the remaining two on the machine learning and NLP components.
Due to overlapping examination schedules, progress has so far been limited to data collection and cleaning. Central bank speeches were obtained from BIS, while market data for the S&P 500 and VIX were sourced from publicly available financial APIs. These datasets were relatively clean and required minimal preprocessing.
Below is how market data were retrieved using Python:
import yfinance as yf
# Download S&P 500 and VIX
sp500 = yf.download("^GSPC", period="max", interval="1d")
vix = yf.download("^VIX", period="max", interval="1d")
# Save raw data
sp500.to_csv("./data/sp500_yahoo.csv")
vix.to_csv("./data/vix_yahoo.csv")
print("Done. Files saved.")
# Almost too easy right?
This step was completed literally under 5 minutes and highlights that the more demanding aspects of the project will arise later during modeling and text analysis.
4. Next Steps and Reflection
All group members still have an examination scheduled for January 9th. Following this, we plan to begin the core NLP and machine learning components of the project, which are expected to constitute the majority of the workload.
Several potential issues have already become apparent. First, the workload distribution across tasks may need to be revisited, as data-related tasks required less effort than initially anticipated. Second, given the limited timeframe, it may be necessary to make careful decisions about which components of the original paper to prioritize and which extensions are realistically achievable. Third, improved communication will be important as the project progresses. Consolidating more discussions within the group chat may help ensure transparency and coordination.
5. Conclusion
In this first blog post, we introduced our group project, motivated our choice of paper, summarized the key elements of the original study, and documented our initial progress. While the project presents several challenges, we believe that continuous reflection, clear communication, and collaborative effort will be crucial in addressing them. Future blog posts will document our progress as we move from planning to implementation and analysis.