Recall
Looking back at our last blog, our group encountered many difficulties and obstacles while scraping news about Intel. These included anti-scraping measures on websites, insufficient information, and data garbling issues. Through the collective efforts of the group, we were finally able to share our successful experiences in this blog.
Successful Web Scraping
def clean_text(text):
"""清理文本内容"""
if not text:
return ""
# 移除HTML标签
text = re.sub(r'<[^>]+>', '', text)
# 移除多余的空白字符
text = re.sub(r'\s+', ' ', text.strip())
# 移除特殊字符
text = re.sub(r'[^\w\s.,!?-]', '', text)
return text
def get_news_from_google(query, language="en-US"):
"""从Google News获取新闻"""
encoded_query = quote(query)
rss_url = f"https://news.google.com/rss/search?q={encoded_query}&hl={language}&gl=US&ceid=US:{language[0:2]}"
try:
feed = feedparser.parse(rss_url)
return feed.entries
except Exception as e:
print(f"获取Google News '{query}'的新闻feed时出错: {str(e)}")
return []
def get_news_from_other_sources(query):
"""从其他新闻源获取新闻"""
news_feeds = {
'Ars Technica': 'https://feeds.arstechnica.com/arstechnica/index',
'Ars Technica Technology': 'https://feeds.arstechnica.com/arstechnica/technology-lab',
'Ars Technica Gadgets': 'https://feeds.arstechnica.com/arstechnica/gadgets'
}
all_entries = []
Here is the core method of our web scraping. I will give brief introduction about the core part.
clean_text(text): Cleans the text content by removing HTML tags and special characters
get_news_from_google(query, language="en-US"): Fetches news from Google News
get_news_from_other_sources(query): Fetches news from Ars Technica
scrape_all_news(max_results=5000): Main function that collects Intel-related news from multiple sources
Finally, we collected total of 4991 news samples were collected from Google News and Ars Technica,and the results were saved as a CSV file, with the following column headers:

Preprocessing
Data Loading and Date Cleaning:
The process starts by importing the necessary libraries and loading the news data from a CSV file into a structured format. It then focuses on cleaning the date information by removing extraneous timezone indicators and formatting the date into a standardized "YYYY-MM-DD" format. This ensures consistency in the date information, which is essential for any time-based analysis later on.
Text Tokenization:
Next, the script applies tokenization to the news titles. Tokenization involves breaking down each title into individual words (tokens). This step converts continuous text into a list of words, making it easier to analyze the text at the word level.
Stopword Removal:
After tokenization, the code filters out common stopwords—words like "the," "is," and "and" that typically do not add significant meaning to the text. Removing these words helps reduce noise and improves the focus on the more meaningful words in the text.
Lemmatization:
Then, the script applies lemmatization to the tokenized words. Lemmatization converts words to their base or dictionary form (for example, "running" becomes "run"), which standardizes the text data. This normalization step is crucial for reducing variations of words and thus enhances the effectiveness of subsequent text analysis or machine learning tasks.
Word Embedding:
The final part of the code introduces the foundation for generating word embeddings using the gensim library’s Word2Vec model. In simple terms, word embeddings transform words into numerical vectors that capture their semantic meaning. This means that words with similar meanings will have similar vector representations in a continuous space.
By setting up the Word2Vec model, the code lays the groundwork for converting the preprocessed tokens (obtained from earlier steps like tokenization, stopword removal, and lemmatization) into these meaningful vectors. This transformation is crucial because it enables machine learning algorithms to work with textual data in a mathematical form, facilitating tasks such as sentiment analysis, text classification, or semantic similarity analysis.
Accumulating of data
After scraping the data, we successfully preprocessed and cleaned it. Following that, we conducted sentiment analysis and K-means classification. This part is detailed in our final report and previous presentations, so we will skip over it here.
The core of this section is how we established a trading strategy to validate the impact of news analyzed through sentiment analysis or K-means classification on the next day's stock price fluctuations.
We observed that the number of news articles after cleaning is not fixed; that is, the number of news articles varies each trading day, making it difficult to associate each article with the day's stock prices. Therefore, we decided to aggregate the results of sentiment analysis and clustering by each trading day, counting the total number of articles for each cluster and sentiment. This will serve as the basis for constructing variables.
For example, on January 10, 2023, we scraped three news articles, one of which had a positive sentiment, while the other two had a neutral sentiment. In terms of clustering, one article was in Cluster 1, and the other two were in Cluster 7. On January 12, 2023, we only scraped one news article, which had a neutral sentiment and was located in Cluster 7.

In this way, we can obtain a series of daily time series dummy variable data, which facilitates the association with daily returns for subsequent causal analysis.
This differs from our initial idea of simply categorizing daily news and examining the next day's stock price fluctuations based on the number of articles in each category.
Our method has two obvious advantages: First, it allows us to consider daily news across different categories and sentiments separately. Initially, we thought that daily news would be limited and repetitive, leading to only one sentiment or category. However, we found that when significant news occurs for Intel, not all reports share the same perspective. For instance, regarding product launches, some sources view it as a positive signal, while others see it as a failed release.
Second, we no longer analyze by "number of days," but rather by "each individual news article." This significantly increases our sample size.
Regression
We use a time series model for analysis, and a crucial point is determining the lag order in the regression equation. Therefore, we employ the VAR model (Vector Auto-regression Model) and determine the lag order using the SC (Schwarz criterion) and HQ (Hannan-Quinn criterion) indicators

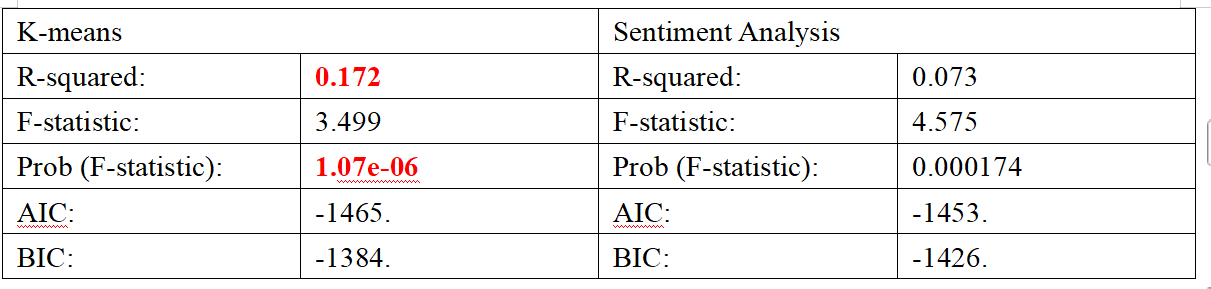
We were pleasantly surprised to find that our regression results are highly significant! Moreover, the comparative results align exactly with our expectations: the clusters identified through K-means classification provide a much stronger explanation for the next day's stock price fluctuations. This means that, compared to the already mature and widely implemented sentiment analysis, our K-means classification offers a stronger explanatory effect for stock prices.
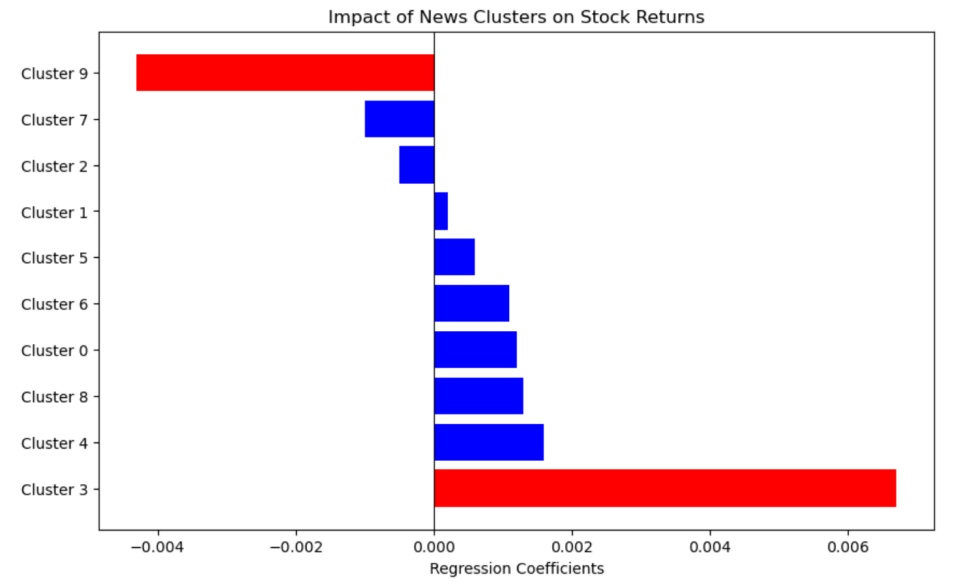
Returning to our initial idea, our goal was to develop a trading strategy. In our final results, Cluster 3 and Cluster 9 have clear positive and negative impacts on the next day's stock prices, respectively. This means that if I aim to sell at a high point and discover that today's news belongs to Cluster 9, that would be my best opportunity. Conversely, if I want to buy before a price increase, identifying news in Cluster 3 would represent the best chance.
Conclusion
In summary, our biggest gain compared to last time is that we successfully scraped the latest news and accumulated a substantial amount of objective data. We believe the highlight of our final analysis lies in our approach to cumulative data to construct variables for regression.
We look forward to communicating with you
Thanks for reading :D