By Group "GenZ AI"
After combining and preprocessing all the data, we can try to visualize the data and make it more readable. After learning more about Latent Dirichlet Allocation(LDA) model in the class, we decided to choose it as our first attempt. Our goal is to find main topics in earning call transcripts.
At the beginning, we just tried to debug and run the model and set the topic number equal to 10, which was randomly chosen. However, after the success of the model, here came a significant question: how many topic numbers should we choose? We can see the importance of topic numbers from followed two pictures. The first picture shows LDA model with 8 topic numbers, and we can see from the right part that most of the words are related to healthcare sector, such as covid, patient and health care. However, in the second picture which shows LDA model with 10 topic numbers, the result is quiet different. Most of the topics are related to system and product. We can conclude that topic numbers are important for us to interpret the final result of our data.
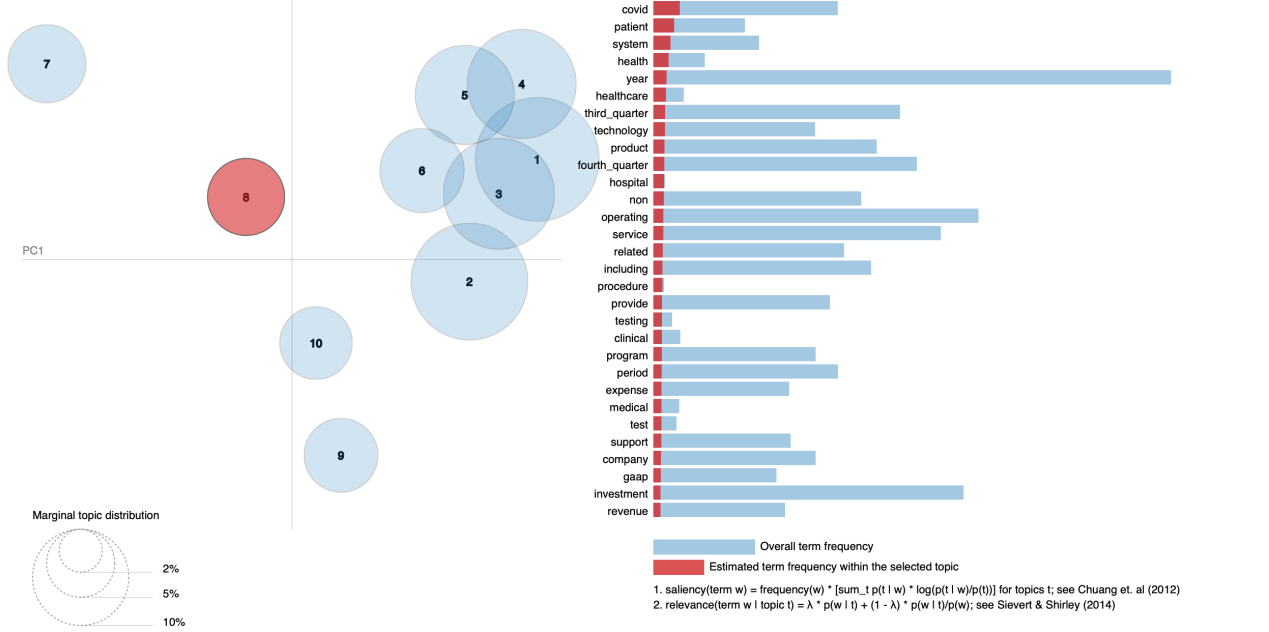
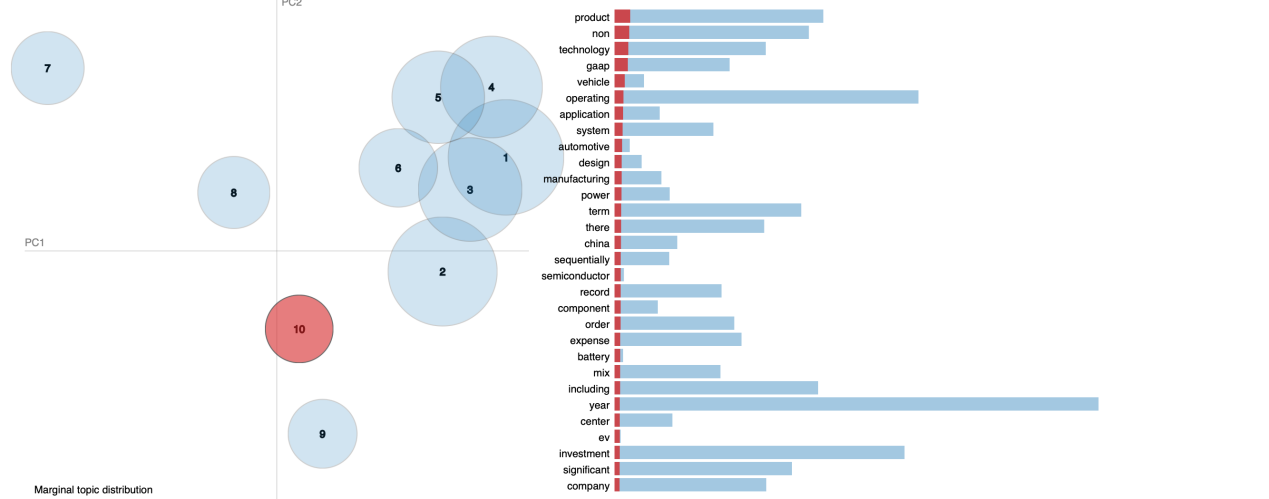
Key Tools for Choosing Topic Numbers
Here are few key tools we took into account for choosing topic numbers.
-
Based on Statistical Metrics and Model Evaluation: (a) Perplexity It can measures the model’s generalization ability on unseen data. Lower values indicate better performance. The topic number is chosen at the turning point of the perplexity curve (but risks overfitting). (b) Coherence It evaluates semantic consistency of topics using metrics like UMass or CV.The topic number is chosen with the highest values.
-
Based on Nonparametric Bayesian Methods: Hierarchical Dirichlet Process (HDP) automatically infers the topic number from data, avoiding manual tuning. It is suitable when no strong prior exists.
Method 1: Perplexity-Based Approach
At first, we tried the method of Perplexity, because the turning point is visualized and clear. With the suggestion that we had better not to put too many numbers which might make the turning point less obvious, we set the maximum number equal to 10. The codes are as followed.
plexs = []
scores = []
# topic number from 1 to 10
for i in range(1, 10):
print(f"Calculating the {i} topic number")
lda_model = LatentDirichletAllocation(
n_components=i,
max_iter=50,
learning_method='batch',
learning_offset=50,
random_state=0
)
lda_model.fit(X_lda)
plexs.append(lda_model.perplexity(X_lda))
scores.append(lda_model.score(X_lda))
# Draw perplexity picture
import matplotlib.pyplot as plt
x = list(range(1, 10))
plt.plot(x, plexs, marker='o')
plt.xlabel('Number of Topics')
plt.ylabel('Perplexity')
plt.title('LDA Model Perplexity by Topic Number')
plt.show()
However, very unfortunately, this attempt was failed.The result is shown in the picture below. The first question was there was no turning point in the final result, which meant no topic number was suggested by this method. To solve this question, we made an assumption that maybe it was because 10 didn’t exceed the best topic number. However, this model cost us a lot of time and we ran more than 10 hours to get the final result of perplexity. If we raise the topic number to 20 or 40, it might cost us for more than 20 or 40 hours, which was very time-consuming. As a result, we switched to HDP model.
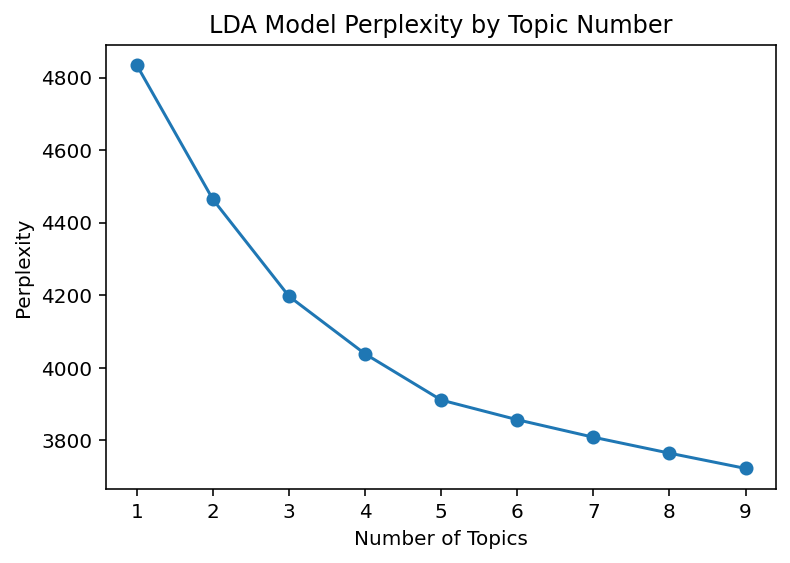
Method 2: Hierarchical Dirichlet Process (HDP)
The advantage of HDP model is that it can calculate the best topic numbers from data automatically. The code is shown as followed.
# 1. Loading data
# ----------------------
try:
df = pd.read_excel('processed_data.xlsx')
assert 'processed_transcript' in df.columns, "There is no processed_transcript"
sia = SentimentIntensityAnalyzer()
df['sentiment_score'] = df['processed_transcript'].apply(
lambda x: sia.polarity_scores(str(x))['compound'])
texts = [doc.split() for doc in df['processed_transcript']]
dictionary = Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
except Exception as e:
print(f"Error!: {str(e)}")
sys.exit()
# 2. HDP model
# ----------------------
print("\nTraining HDP Model")
hdp_model = HdpModel(
corpus=corpus,
id2word=dictionary,
chunksize=2000,
random_state=42,
kappa=1.0,
tau=64.0,
K=15, # first topic number
T=150 # max topic number
)
# determine the best topic number
optimal_topics = len(hdp_model.get_topics())
print(f"According to HDP model, the best topic number is: {optimal_topics}")
However, after more than 12-hours waiting, the result did not become better. HDP model told us that the best topic number should be 150, and it is too much to show the topic clearly. The result of HDP model is shown in the picture below.
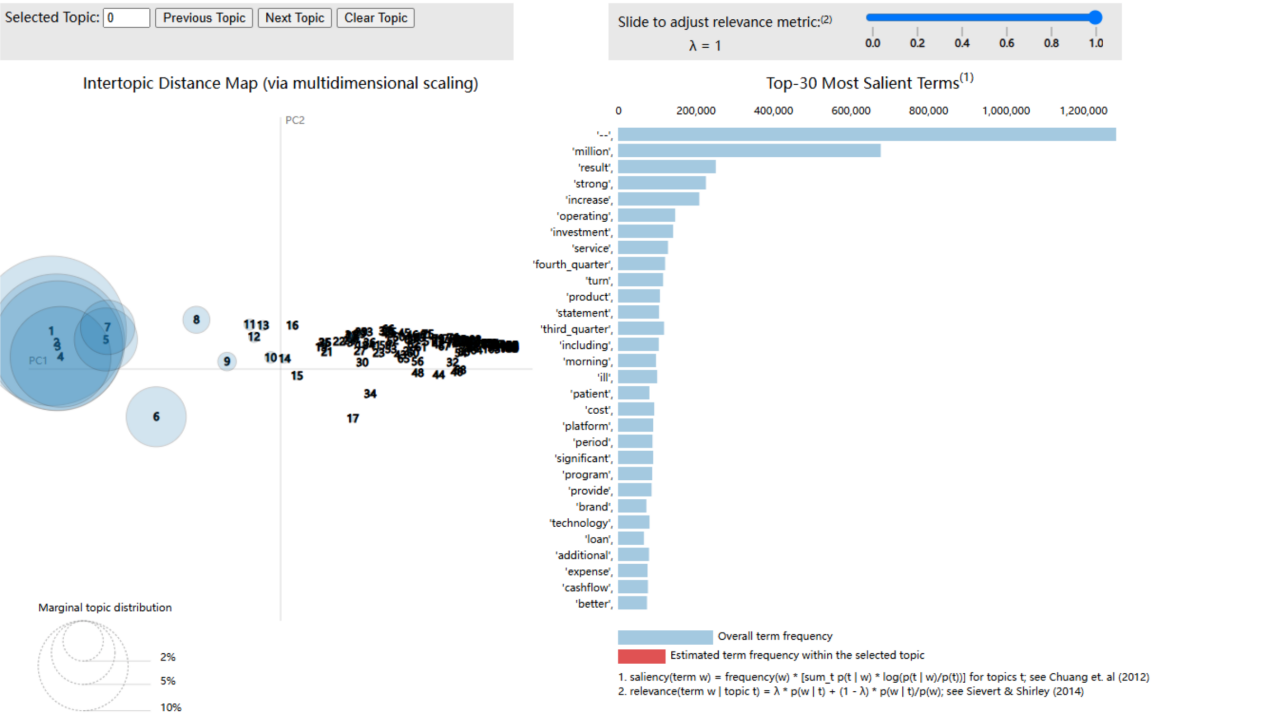
What caused the failure of perplexity and HDP model? According to our conjecture, the main reason is that there are too many different topics in the transcripts. With data which was collected without identifying their sectors, it might be difficult to show all the topic within 30 words. In addition, since data was not balanced, it is also possible that some industries have too large a proportion of tokens. After thinking carefully about the possible question, we will try to separate data with their sectors,which can also achieve our goal in another way.