The objective of our project is to build quantitative trading strategies based on text clustering by analyzing the correlation between news clustering and market movements. In this blog post, we will focus on the process of scraping data from Reuters, specifically demonstrating how we use curl and a delay mechanism to bypass anti-scraping measures, as well as how we process and analyze the market data. Furthermore, we will provide an overview of the methods we plan to use in the next phase of the project.
Reuters News
Considering the large amount of data, we have decided to crawl news only from the Reuters website. After further research, we found that the data of Reuters Archive was only updated until 2023. Therefore, we finally chose the period from January 2019 to December 2023 as the range of data crawling.
Trying to scrap news from Reuters archive
We started with web scraping news data. There are various data sources such as Bloomberg, Reuters and Wall Street Journal. Considering the relevance, data quality and free availability, we finally decided to use Reuters.
To capture the news articles from Reuters archive, we tried using two existing GitHub repositories but ran into issues with outdated links and code.
Github repo 1
After running the GitHub news_scraper, it indicated that it was unable to find the desired archive page.
python3 scraping_reuters.py
Day 2025-01-01 was skipped - Archive Page Not Found
Day 2025-01-02 was skipped - Archive Page Not Found
Day 2025-01-03 was skipped - Archive Page Not Found
Day 2025-01-04 was skipped - Archive Page Not Found
Day 2025-01-05 was skipped - Archive Page Not Found
Day 2025-01-06 was skipped - Archive Page Not Found
Day 2025-01-07 was skipped - Archive Page Not Found
Day 2025-01-08 was skipped - Archive Page Not Found
Day 2025-01-09 was skipped - Archive Page Not Found
We found that the original archive URL (https://www.reuters.com/resources/archive/us/20240101.html) was deprecated and no longer accessible.
Switching to the current archive pattern, we discovered the archive entry point on the Reuters homepage and noted that the most latest archived news dates back to 2023.
In addition, we discovered that there are many duplicate news articles on the archive page, which would be addressed later.
To our surprise, accessing the archive news directly through the website works as expected, and there is a discrepancy between the URL used in our code and what actually works. This means that while the archive folder remains accessible, modifications to our code are necessary.
Github repo 2
We identified another GitHub repo, news-clawer, for this purpose and followed its setup instructions from the README file to test it with Reuters content, but encountered difficulties installing dependencies:
[notice] A new release of pip is available: 24.3.1 -> 25.0.1
[notice] To update, run: pip3 install --upgrade pip
ERROR: ERROR: Failed to build installable wheels for some pyproject.toml ba
sed projects (Pillow)
The code seems to use an older version, but we are unsure if updating will work seamlessly. So, we've left it unchanged for now and plan to install it when executing the Python script later. Besides, when reviewing the configuration file, we noticed a link that doesn't match the pattern on the homepage. Nevertheless, we need to modify it to align with the US market.
# The base url to retrieve BBC News link
base_api_url=https://uk.reuters.com/resources/archive/uk/{year}{month:0>2}
{day:0>2}.html
Finally, we decided to construct the request pattern ourselves.
Designing a Custom Scraper
After discovering that previous three methods were ineffective for scraping Reuters news, we decided to explore a more customized approach to build a scraper that would work effectively with Reuters' website structure.
Pattern learning
After numerous attempts, we found out a way for bulk extracting news links from dynamically loaded pages by inspecting the information under the Network tool. We analyzed the pattern of Reuters' archive URLs, which follow a certain format:
https://www.reuters.com/archive/{YYYY-MM}/{DD}/{PageNo}
This structure consists of three key components: 1. YYYY-MM: The year and month of the news archive (e.g., 2022-01 for January 2022). This is the first part of the URL, indicating the time frame of the articles we want to scrape. 2. DD: The specific day of the month (e.g., 01 for the first day). This segment represents the day for which we want to gather articles. 3. PageNo: The page number, indicating pagination of the articles (e.g., /1/, /2/, etc.). This part allows us to navigate through multiple pages of articles for a specific date.
After analyzing the URL pattern for Reuters’ news archives, we tried to construct links for each day and page number and made sure to check the reponses to verify whether they are valid or not. If we encounter a link that does not return relevant content, we simply skip that link and move on.
We tested one of the links and then inspected the network requests made when browsing the page. Take the link on January 1, 2022 as an example, we examined the first article on the first page. Using the Network tab in the browser's developer tools, we searched for the keyword "Lamar", which is related to an article's content in order to locate the specific network request tied to that article. Based on our observations, we locate one file named 1/, and we inspected its details, focusing on the Response tab to see the content returned by the server.
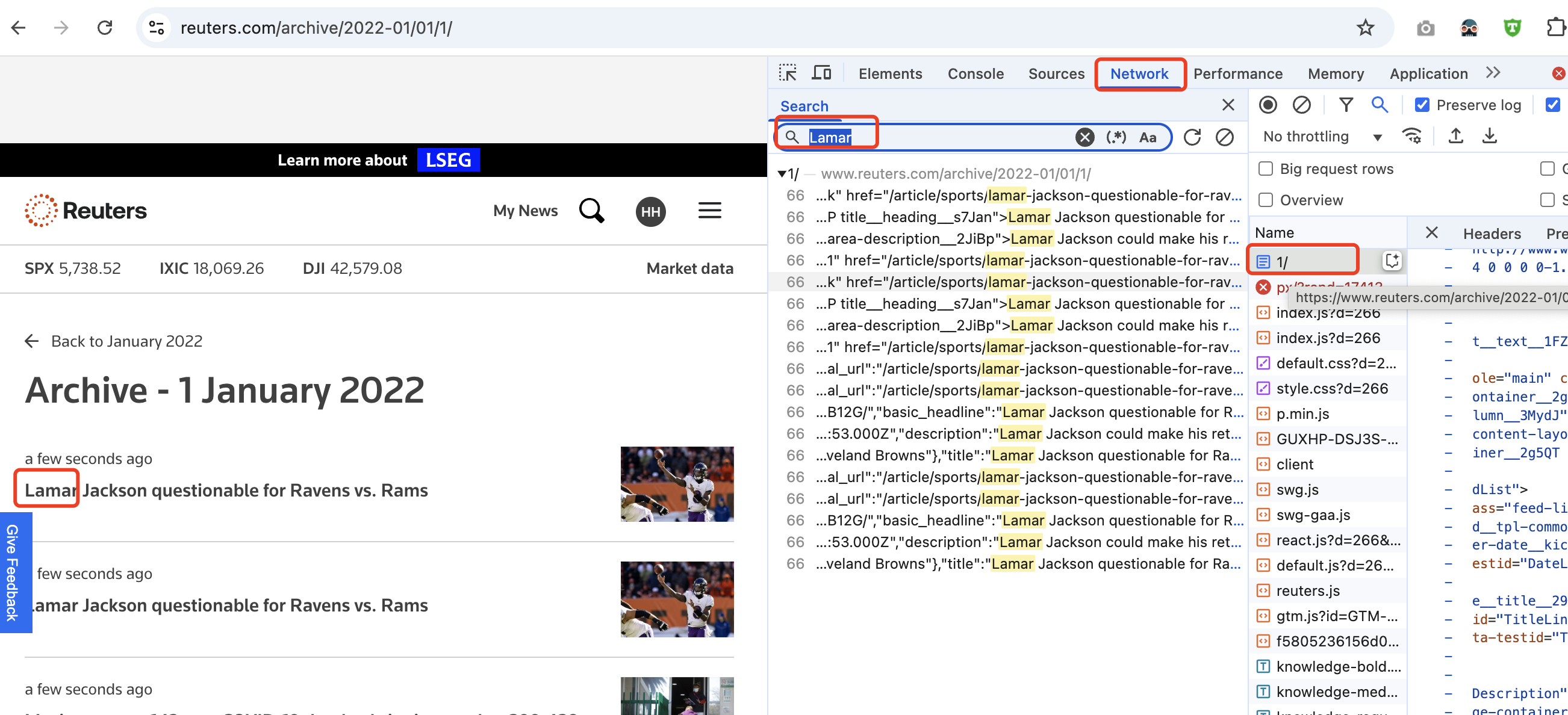
In this case, it looks like HTML content with a reference to "Lamar"’s statement. We deduced that this request was responsible for retrieving the list of articles for that particular day. Then, we right-clicked on the request in the Network tab and selected "Copy as cURL." This option allowed us to copy the entire request (including headers, parameters, and method) in the cURL format, where we could reproduce the same network request outside the browser, using a terminal or command line.
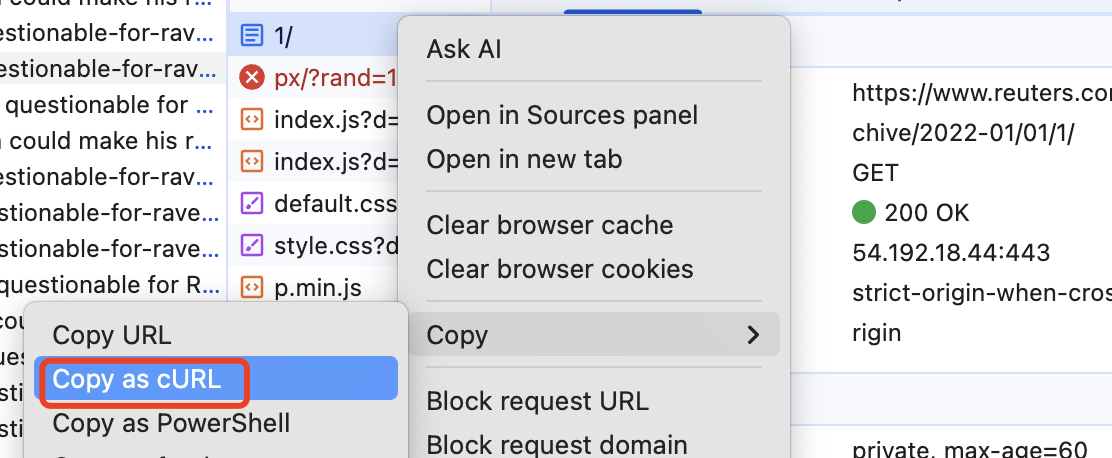
Why Use cURL Commands Instead of Python’s
requests?Given the website's anti-scraping policies, we recognized that using Python's built-in requests library to send HTTP requests could trigger detection mechanisms. These measures would identify our requests as coming from a scraper, eventually triggering robot checks or blocking further access.
To avoid this, we decided to use cURL commands to simulate more legitimate browsing behavior. By copying the network request associated with fetching the article list and converting it into a cURL command, we are able to bypass basic scraping detection mechanisms.
Here’s a illustration of how we make these requests in the code:
def fetch_page(url):
curl_command = [
'curl', url,
'-H', 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'-H', 'accept-language: zh-CN,zh;q=0.9,en;q=0.8',
'-H', 'sec-fetch-dest: document',
'-H', 'sec-fetch-mode: navigate',
'-H', 'sec-fetch-site: none',
'-H', 'sec-fetch-user: ?1',
'-H', 'upgrade-insecure-requests: 1',
'-H', 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36'
]
result = subprocess.run(curl_command, capture_output=True, text=True)
return result.stdout if result.returncode == 0 else None
Handling Redirection
Having established this pattern, we can proceed to the code to scrape the links. After constructing the initial request for the archive page and running the code, we will retrieve an HTML file that contains a list of articles associated with that specific page.
When we tried to access these article, we encounter a redirect, which means we have to locate the redirection link and then directly request the redirection link. Therefore, we open the Network tab in the browser's developer tools again. During the loading process, we noticed two requests in the console, which means we need to handle these two requests:
1. The first request: This retrieves the original article link, but the response contains an HTTP status code 301 Moved Permanently, along with a Location header that indicates the new redirection URL.
2. The second request: We follow the redirection link and fetch the actual article content.
To retrieve the content of each article, we send a request to the redirection link and parse the resulting HTML.

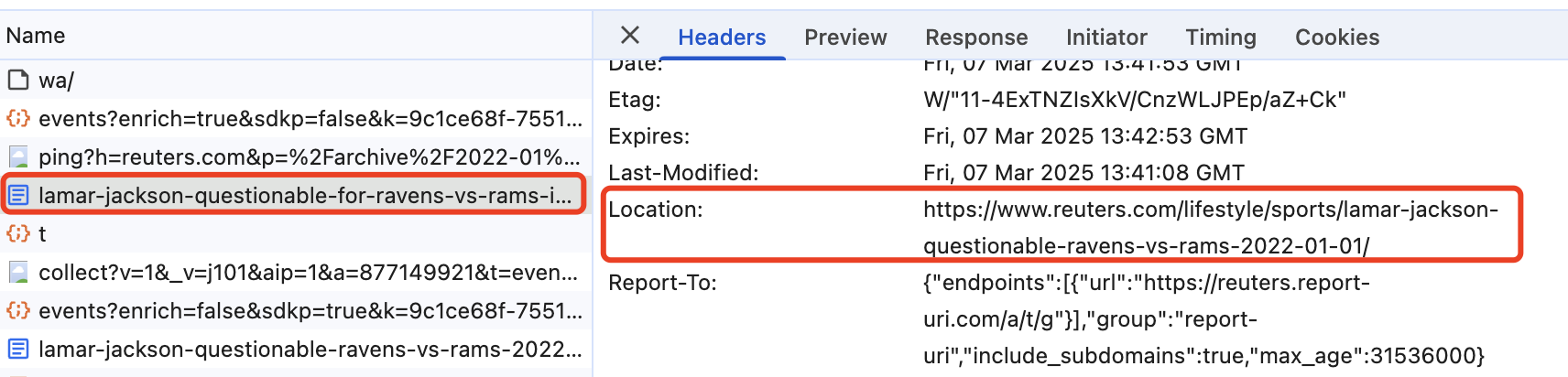
Here is the code for handling the redirection:
for line in headers.split("\n"):
if line.lower().startswith("location: "):
redirected_url = line.split(": ", 1)[1].strip()
print(redirected_url)
return fetch_article(redirected_url)
return body if result.returncode == 0 else None
Fetching Article Content
To retrieve the content of each article, we send a request to this redirect link and parse the generated HTML, and parse the news article page, extracting the article's title, date, time, content, and tags. Meanwhile, the parsed article data is saved to a JSON file in a folder named after the article's publication date.
Here’s the function to parse the article page:
# The Function to parse the article page
def parse_article_page(html):
soup = BeautifulSoup(html, 'html.parser')
title = soup.find('title').get_text(strip=True) if soup.find('title') else ""
date_info = soup.find_all(class_='date-line__date___kNbY')
date, time_, updated = [d.get_text(strip=True) for d in date_info[:3]] if len(date_info) >= 3 else ("", "", "")
body = "".join([p.get_text(strip=True) for p in soup.find_all(class_='article-body__content__17Yit')])
tags = [tag.get_text(strip=True) for tag in soup.find_all(attrs={'aria-label': 'Tags'})]
return {
"title": title,
"date": date,
"time": time_,
"updated": updated,
"body": body,
"tags": tags
}
# The content of one of the articles
{
"title": "Nasdaq hits record high on energy, tech boost | Reuters",
"date": "August 24, 2021",
"time": "1:40 PM UTC",
"updated": "Updated ago",
"body": "Aug 24 (Reuters) - Wall Street's main indexes opened higher on Tuesday as a full U.S. approval of a COVID-19 shot helped boost shares of energy and travel-related companies, while gains in technology stocks lifted the Nasdaq to a fresh high.The Dow Jones Industrial Average(.DJI), opens new tabrose 47.0 points, or 0.13%, at the open to 35382.72. The S&P 500(.SPX), opens new tabrose 4.9 points, or 0.11%, to 4484.4, while the Nasdaq Composite(.IXIC), opens new tabrose 35.5 points, or 0.24%, to 14978.142 at the opening bell.Sign uphere.Reporting by Sruthi Shankar in Bengaluru; Editing by Vinay DwivediOur Standards:The Thomson Reuters Trust Principles., opens new tabSuggested Topics:BusinessShareXFacebookLinkedinEmailLinkPurchase Licensing Rights",
"tags": [
"Business"
]
}
In addition, to prevent being blocked by Reuters, we implement a rate-limiting mechanism using time.sleep. This ensures that we pause for 3 seconds between each article request to mimic natural browsing behavior.
The above is how we developed a custom scraper. For the detailed code, please visit GitHub.
Market Data Collection and Preprocess
The Dividend Discount Model is chosen to price indexes. Firstly, mature, dividend-paying firms dominate indices, making dividends relatively predictable compared to earnings or revenue. Secondly, when using multilple, there is no comprable peers for indexes and no one absolute controls indexes or their affiliates, making the Free-Cash-Flow Model also not feasible. Therefore, ginancial data such as price and dividend yield are extracted from Yahoo Finance and Ycharts, repectively for the price modeling.
Price Data (2019.01–2023.12)
- Source: Yahoo Finance (manual export)
- Method: Downloaded daily adjusted closing prices for the S&P 500 (^GSPC) from January 1, 2014, to December 31, 2024.
Dividend Yield Data (2019.01–2023.12)
- Source: YCharts (manual export)
- Method: Collected quarterly dividend yields and converted yields to decimals for calculations.
Dividend Calculation & Assumptions
This step is to illustrate how to utilize GGM model to predict the security price, using S&P500 index as an example.
Model Function
- D₀ = \(P_0 \times \text{Dividend Yield}\)
- Dividend Value = \(\frac{D_0 \times (1 + g)}{r - g}\)
- Deviation = \((\text{Predicted Price} - \text{Actual Price}) - 1\)
Define Assumption
- D₀: Current dividend payment, source from Ycharts.
- P₀: Current index price, source from Yahoo Finance.
- Growth Rate (g): 4.0% (historical real GDP growth).
- r: 5.5% (historical Discount rate combined with US 10-year treasury bond yield and equity risk premium).
- Predicted Price: Price of index at the next period.
Compute Predicted Price
Taking November 2024 as an example, the main idea of how to compute the predicted price is as follows:
-
D₀ = \(P_0 \times \text{Dividend Yield}\)
-
76.61 = \(6032.38 \times 1.27\) (Dividend Yield of Nov. 2024)
-
Predicted Price = \(\frac{D_0 \times (1 + g)}{r - g}\)
-
5311.63 = \(\frac{76.61 \times (1 + 0.04)}{0.055 - 0.04}\)
-
Deviation = \((\text{Predicted Price} - \text{Actual Price}) - 1\)
-
-9.69% = \((5311.63 - 5881.63) - 1\)
Note: In order to compile the formulas correctly, you may need to install the necessary plugin by running the following command in the terminal:
python -m pip install pelican-render-math.
Future Discussion
Ideas About Trading Strategy
Sentiment-Driven Trading Strategy: This strategy leverages financial news data to gauge market sentiment and make informed trading decisions. It involves analyzing the sentiment of news articles to identify shifts in market mood, which can signal potential upward or downward trends in stock prices.
- Sentiment Analysis: Analyze news articles to derive sentiment scores. These scores can be clustered with price data to create a comprehensive view of market sentiment.
- Trading Logic: Compare daily average sentiment with a rolling average (e.g., 7-day). If the current day's sentiment is positive and higher than the rolling average, enter a long position; if negative and below, enter a short position.
Volatility Clustering Strategy: Volatility clustering refers to periods of high volatility often following each other. This phenomenon can be linked back to traders' reactions towards news events. A strategy could involve anticipating increased volatility after significant news releases.
- News Monitoring: Track major financial news releases.
- Positioning: Enter positions during periods expected to have high volatility following significant announcements.
Volume-Sentiment Divergence: This strategy refers to trade based on the divergence between news sentiment and trading volume.
- Sentiment vs. Volume: Identify instances where sentiment is bullish but volume is low (or vice versa). (e.g., Low volume with bullish sentiment → no trade (lack of conviction); High volume with bullish sentiment → enter long.)
- Trade Execution: Enter trades based on the alignment of sentiment and volume. Exit the trade if volume declines or sentiment shifts.
Sector Rotation Strategy: This strategy uses news clustering and market correlation to identify which sectors are poised to outperform based on macroeconomic or geopolitical news.
- Market Relationships: Cluster news articles by sector (e.g., energy, healthcare, technology). Determine the overall sentiment for each sector. Identify inter-sector relationships (e.g., when energy prices rise, airlines tend to underperform). Use correlation matrices to understand how sectors impact each other.
- Execution: Rotate capital into sectors with positive sentiment and strong momentum. Hedge by shorting underperforming sectors with negative sentiment.