Recalling from our previous presentation, our group intend to utilize the news articles related to NVIDIA available online, convert those text data into numerical data by sentiment analylsis, and use this data to predict the volatility of NVIDIA. In kickstart our project, the first and major step is web scraping.
Web scraping is a technique used to extract data from websites. It involves programmatically accessing and retrieving specific information from web pages. In the context of financial research, web scraping allows us to gather a wealth of textual information from news websites.
However, scraping articles from news websites can be complicated. Many websites use dynamic loading, where content is loaded dynamically as the user scrolls or interacts with the page, but the link to this page is not changed. This poses a challenge when attempting to retrieve all the desired data, as the entire page content may not be readily available in the initial HTML response.
In this blog post, we will focus on showcasing our works on scraping the data from CNBC, Yahoo and Washington Post, by demonstrating how to find the links to the articles related to our target company/collecting the text data required.
CNBC
Observing the page
Searching for NVIDIA on the CNBC website, it can be observed that only a portion of the article titles and summaries are displayed initially. As the page is scrolled to the bottom, a new set of articles appears, as showing below.
Before loading:
After loading:
Inspecting the source code we could also find that, the links for all articles are not available at the first glance, which makes it impractical to simply scrape the web source code to obtain link information.
Network inspecting
After several trials, we figured out how to extract news links in bulk from dynamically loaded pages by inspecting information under the Network tool. While we discovered certain specific patterns for this website, the general approach can be applied to similar cases.
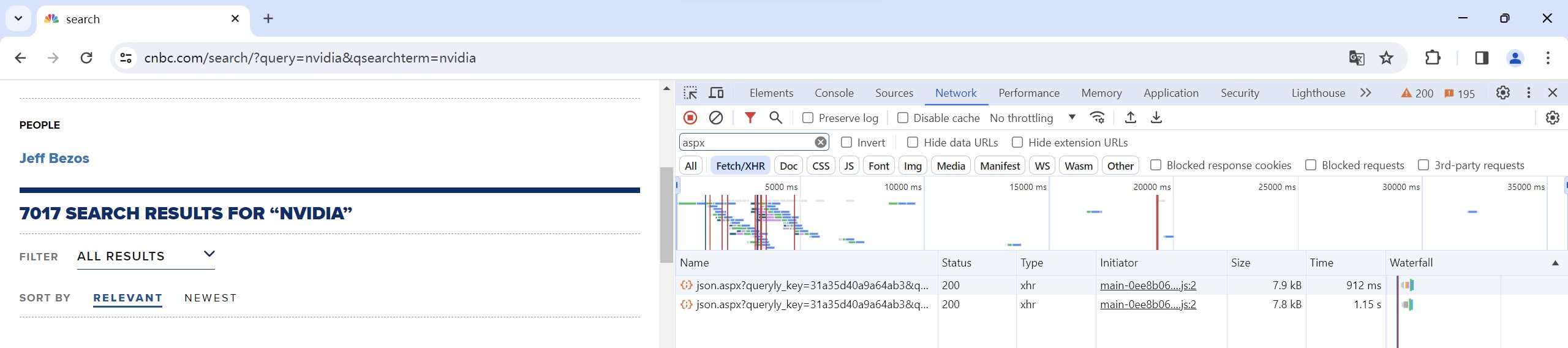
First, click on "Network" and filter out the files whose name contain "aspx". As shown in the screenshot, before loading more webpage content, there are only two files visible. However, after loading more content, the number of files in this section increases accordingly.
Before loading:
After loading:
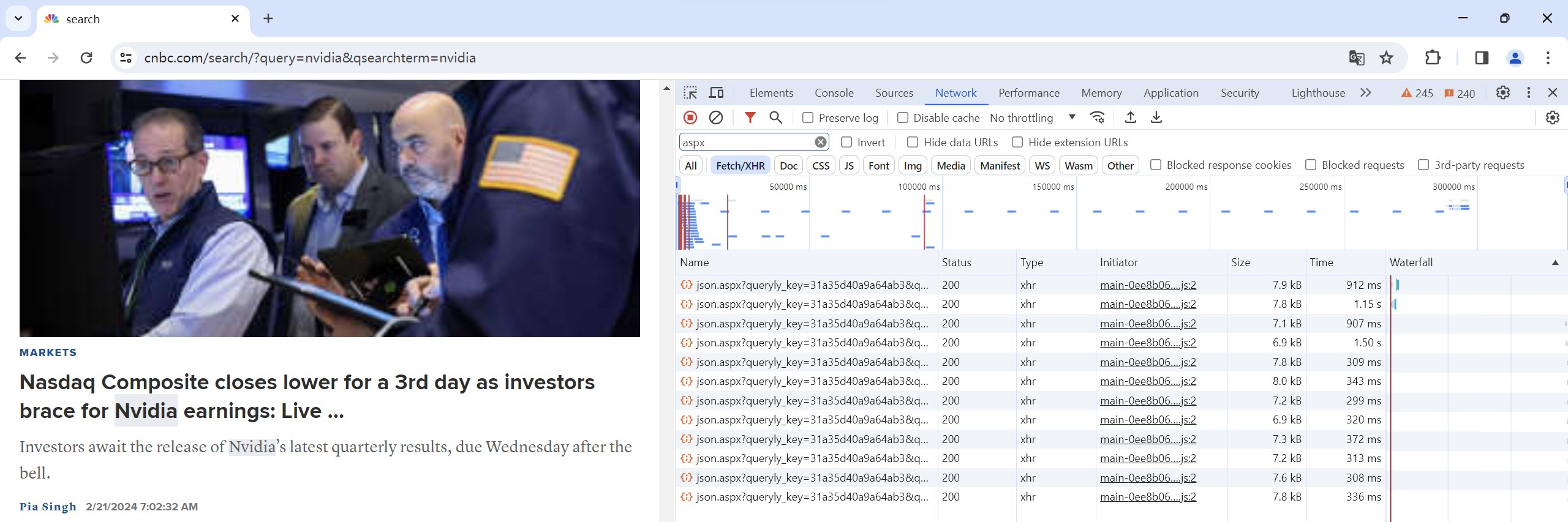
Click on "Preview" and expand the "results" section. Here, we can see the links of the newly loaded articles, neatly arranged in groups of ten.
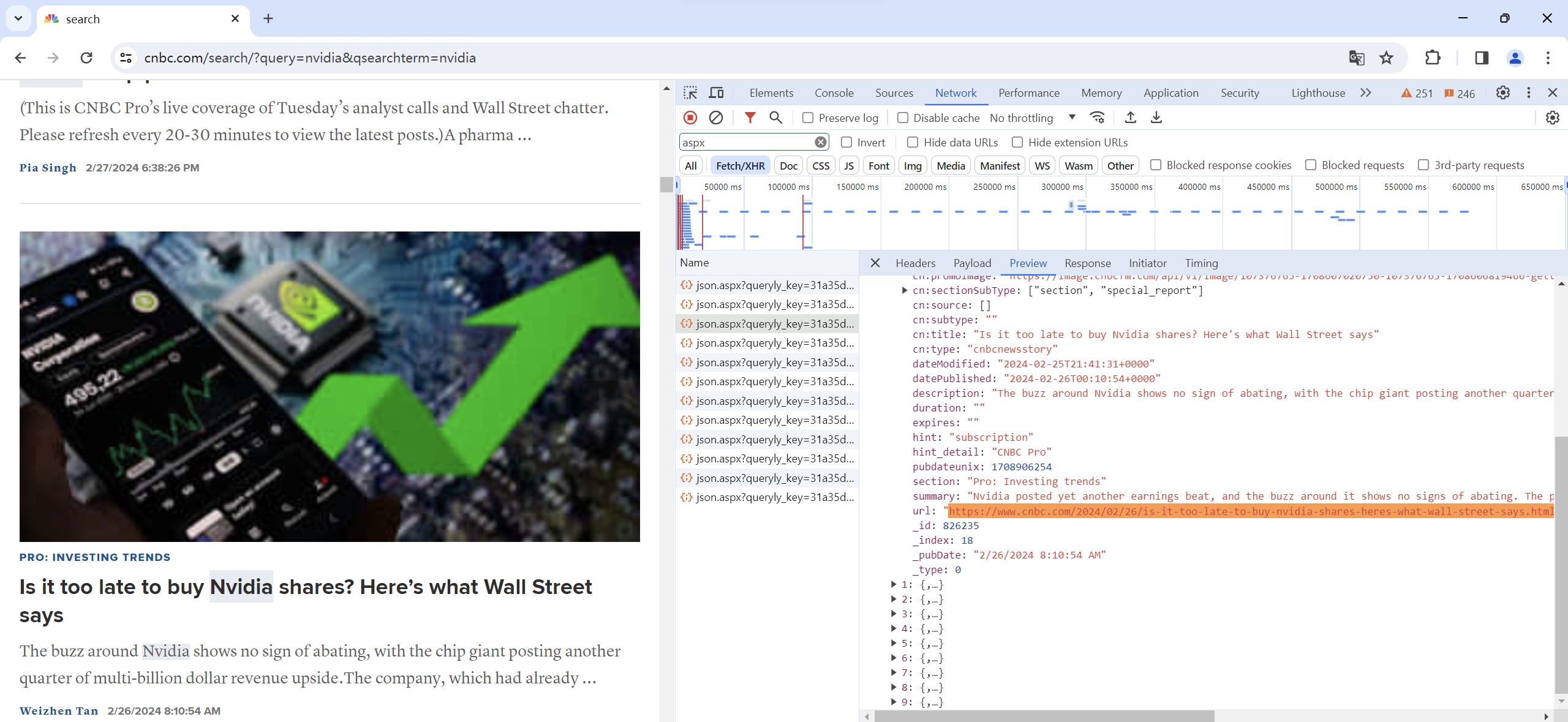
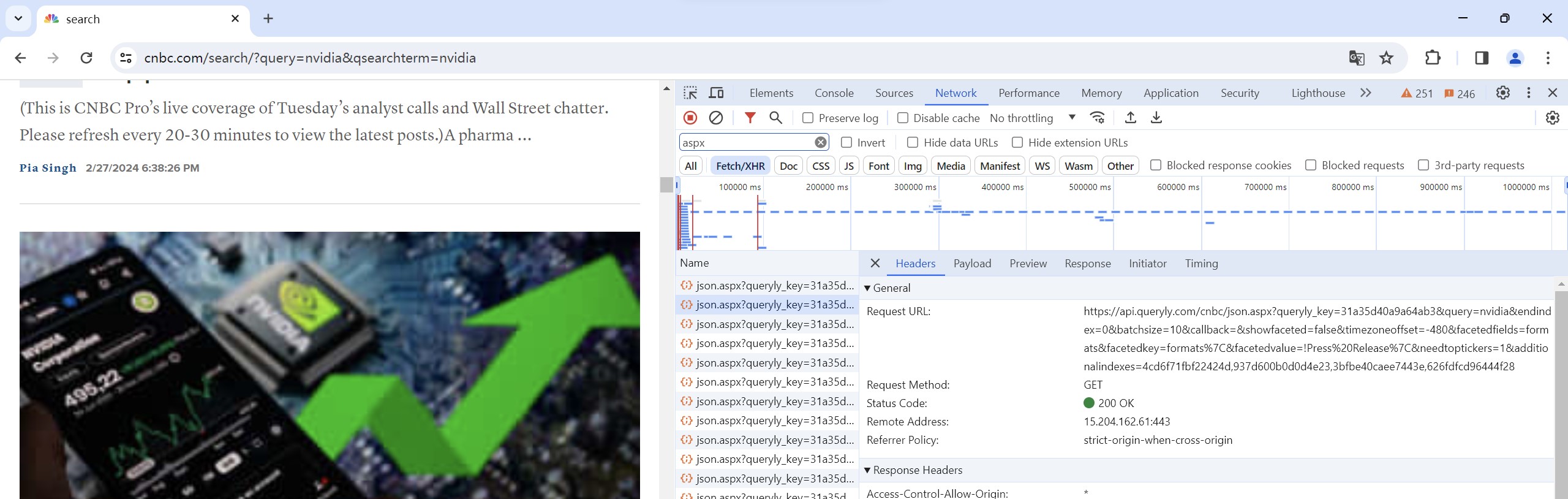
We then go back to "Headers", where "Request URL" is shown. Open it we can find a page containing all ten links to the articles loaded this single time. So this url is what we want. Further explore the structure of the url, we could find that all of them just differ in one number, which start form 0 and increment by 10 each time.
Code for scraping links to news
With this pattern, we can move to the code to scrape the links. By employing a simple loop structure, we can obtain a substantial number of website URLs containing news links. Using regular expression, we can extract the links for news articles.
import re
import requests
import time, random
import pandas as pd
requests.packages.urllib3.disable_warnings()
def status_check(url):
agent = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.79 Safari/537.36'}
resp = requests.get(url, headers = agent, verify = False)
if resp.ok:
return requests.get(url, headers = agent, verify = False).text
return False
linkpattern = r'"url":"(https:\/\/www\.cnbc\.com\/\d+\/.*?)","@id"'
links1 = []
start = time.time()
for i in range(100):
indi = str(10*i)
url = 'https://api.queryly.com/cnbc/json.aspx?queryly_key=31a35d40a9a64ab3&query=nvidia&endindex=' \
+ indi \
+ '&batchsize=10&callback=&showfaceted=false&timezoneoffset=-480&facetedfields=formats&facetedkey=formats%7C&facetedvalue=!Press%20Release%7C&additionalindexes=4cd6f71fbf22424d,937d600b0d0d4e23,3bfbe40caee7443e,626fdfcd96444f28'
if status_check(url) == False:
print(url)
else:
content = status_check(url)
link = re.findall(linkpattern, content)
links1 += link
time.sleep(random.random())
end = time.time()
print((end-start)/60)
It is important to note that the above code is designed to help us retrieve news articles in textual form, excluding videos. However, the titles of videos can also play a role in sentiment analysis. Additionally, there may be some articles that require a membership to read, but their titles can still be valuable. We will consider addressing these situations in the later stages.
Yahoo
Scraper on Github
We were able to find a web scraper on Github to extract Yahoo! News articles summary based on search criteria. Using the scraper, we extracted the articles and the corresponding links related to NVIDIA.
Actual Scraping
Here it's the Python code for scraping Headlines, Sources, Posted, Descriptions, and Links.
import re, requests, csv
from time import sleep
from bs4 import BeautifulSoup
#making HTTP requests to the website and imitating a web browser.
headers = {
'accept': '*/*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'en-US,en;q=0.9',
'referer': 'https://www.google.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36 Edg/85.0.564.44'
}
def get_article(card): #It takes a `card` as input, which represents an article on the webpage.
"""Extract article information from the raw html"""
headline = card.find('h4', 's-title').text
source = card.find("span", 's-source').text
posted = card.find('span', 's-time').text.replace('·', '').strip()
description = card.find('p', 's-desc').text.strip()
raw_link = card.find('a').get('href')
unquoted_link = requests.utils.unquote(raw_link)
pattern = re.compile(r'RU=(.+)\/RK')
match = re.search(pattern, unquoted_link)
clean_link = match.group(1) if match else None
article = {
'Headline': headline,
'Source': source,
'Posted': posted,
'Description': description,
'Link': clean_link
}
return article
def get_the_news(search):
#This function takes a `search` term as input and is the main part of the program.
#It starts a loop to iterate through multiple pages of search results.
#Inside the loop, it sends a GET request to the URL and parses the HTML response using BeautifulSoup.
"""Run the main program"""
template = 'https://news.search.yahoo.com/search?p={}'
url = template.format(search)
articles = []
links = set()
while True:
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
cards = soup.find_all('div', 'NewsArticle')
# extract articles from page
for card in cards:
#Checks if the extracted link is not already in the set of links and adds the article to the `articles` list.
article = get_article(card)
link = article['Link']
if link and link not in links:
links.add(link)
articles.append(article)
#The loop continues until there are no more pages of search results.
# find the next page, and it introduces a delay of 1 second before making the next request to avoid overwhelming the website.
try:
url = soup.find('a', 'next').get('href')
sleep(1)
except AttributeError:
break
#Finally, it saves the article data in a CSV file named "results.csv" and returns the list of articles.
with open('results.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=articles[0].keys())
writer.writeheader()
writer.writerows(articles)
return articles
articles = get_the_news('Nvidia')
for article in articles:
print('-' * 50)#prints a line of dashes as a separator to visually separate each article's information.
print(f"Headline: {article['Headline']}")# prints the headline of the article using an f-string to include the value of `article['Headline']`.
print(f"Source: {article['Source']}")#prints the source of the article using an f-string to include the value of `article['Source']`.
print(f"Posted: {article['Posted']}")#prints the posted date of the article using an f-string to include the value of `article['Posted']`.
print(f"Description: {article['Description']}")#prints the description of the article using an f-string to include the value of `article['Description']`.
print(f"Link: {article['Link']}")#prints the link of the article using an f-string to include the value of `article['Link']`.
print('-' * 50)
744 news articles regarding Nvidia have been posted on Yahoo and are stored in a CSV file. We have mainly gathered links, descriptions and headlines. Our next step would be using the collected links to scrape each articles' text, which will be helpful for sentiment analysis.
Washington Post
Scraping with Apify
We have also utilized a online platform named Apify to help us to scrape the data from Washington Post. However, a limitation of it is that we were not able set a filter to only collect the news related to NVIDIA. We found a work-around by only scraping the articles under Technology. With the results, we can further filter out the articles related to our target.
A snapshot of the working Apify scraper - Scope set as all tech-related news after 2024-01-01:
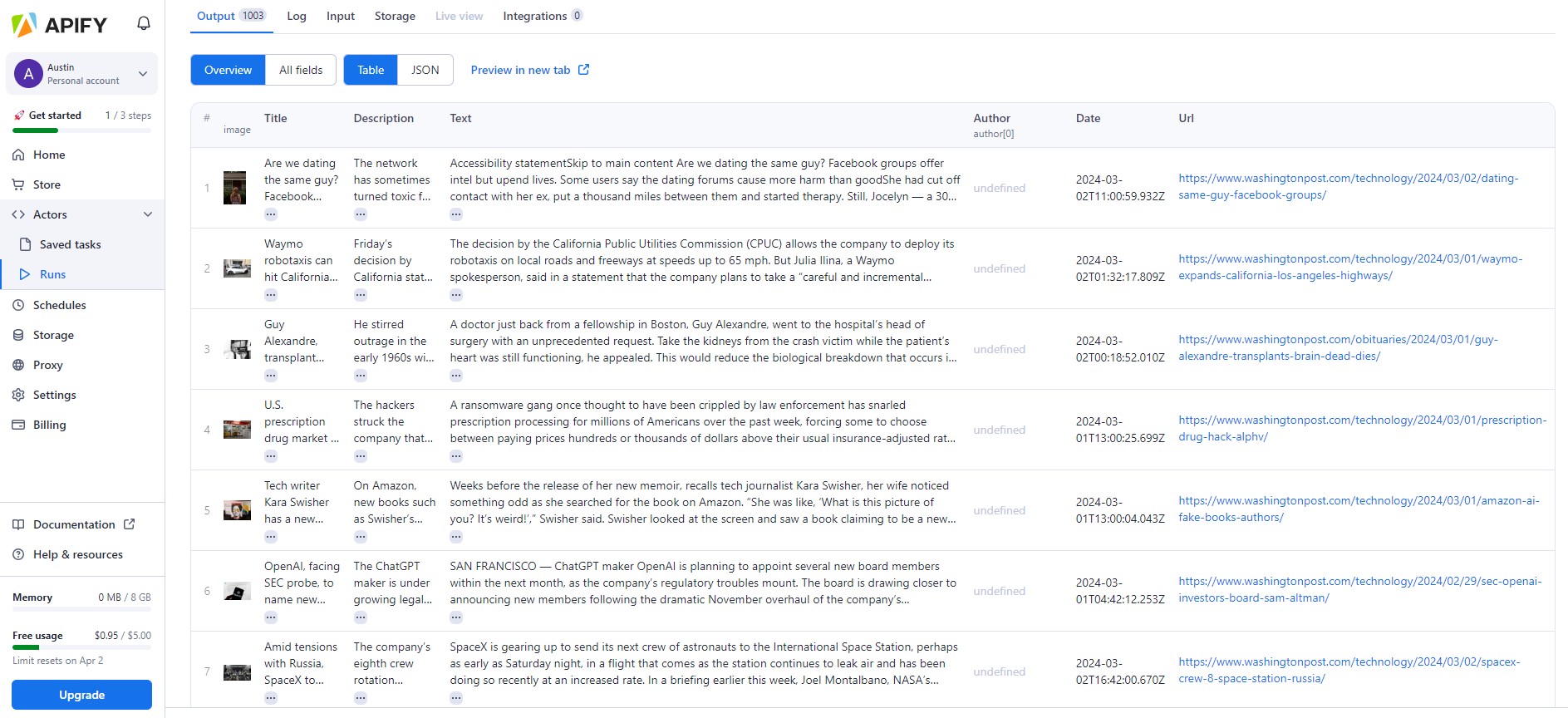
We can see that the scraper sucessfully retrieved the Title, Description and Text of each article. These results can then be exported to csv for our further handling. For the time being, we have scraped the articles after 2024-01-01 on Washington Post using this tool.
Next Step
Text Analysis
We will continue to explore other data sources and assess their abundance of articles related to our target, as well as their accessibility. We aim to scrape from 1 or 2 more websites to allow our data sources to be more diversified.
After that, we will explore the use of different Text Sentiment Analyzers. We will try focus on using NewsSentiment as it is an easy-to-use Python library that achieves state-of-the-art performance for target-dependent sentiment classification on news articles.
Collection of Y-values and model building
We will also work on collecting the necessary Y-values and explore various machine learning/ deep learning models to proceed with the project.
In particular, we intend to employ the data of Average True Range (ATR) and standard deviation as metrics to measure volatility, which serve as the necessary Y-values required to proceed this project. Average True Range (ATR) and standard deviation are both widely recognized measures of volatility in finance.
Average True Range (ATR): ATR is a technical analysis indicator that measures market volatility by calculating the average range of price movements over a specified period. It takes into account the highs, lows, and closing prices of an asset, reflecting the degree of price fluctuations. Since ATR accounts for the extent of price changes, it provides a comprehensive view of the market's volatility, making it a useful tool for assessing risk and determining stop-loss levels.
We employ the Average True Range (ATR) to reflect the true price fluctuations over a specific period. Let \(H_t\), \(L_t\), and \(C_t\) denote the highest price, lowest price, and closing price on day \(t\), respectively; then ATR is defined as follows:
\(TR_t = max(\frac{H_t-L_t}{C_{t-1}}, \frac{abs(H_t-C_{t-1})}{C_{t-1}}, \frac{abs(C_{t-1}-L_t)}{C_{t-1}})\)
\(ATR_{10, t} = \displaystyle \sum_{i=1}^{9}{\frac{TR_{t-1}}{10}}\)
Note: In order to compile the formulas correctly, you may need to install the necessary plugin by running the following command in the terminal:
python -m pip install pelican-render-math.
Standard Deviation: Standard deviation is a statistical measure that quantifies the dispersion of a set of data points, such as the returns of a financial asset. In the context of finance, standard deviation is often used to gauge the volatility of an asset's returns. By measuring the deviation of returns from their mean, standard deviation offers valuable insights into the risk associated with an asset, helping investors make informed decisions regarding their investment strategies.