
Understand Transformer and Bert Model
1.1 Preliminary Concepts
- Word Embedding
- Recurrent Neural Network
- Back Propagation
- Cosine Similarly
1.2 Attention is all you need
The key idea of the Transformer model and the Bert, or Bidirectional Encoder Representations from Transformers, is the attention structure. The structure is designed to alleviate the information losses in the hidden layers of the recurrent neural network by inspecting the similarities, or the importance of a work token relative to the rest of the materials and itself. This structure enhances the predictability and allows the concurrent calculation in GPU.
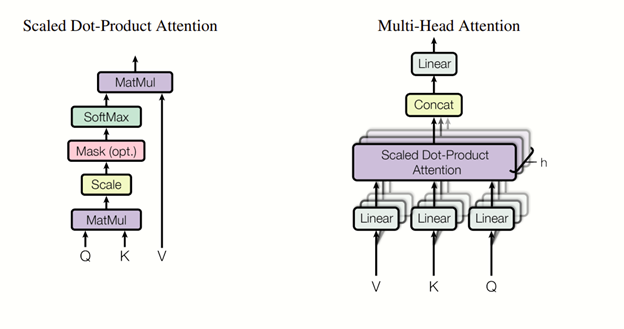
Structure:
For one stack:
Query, Key, and Value:
This set is constructed by the sum of the multiple results of the residual connection, seen in section 1.3, assigned with weights and biases.
The set of Query, Key, and Value is generated by the same way with different weights and biases from the results of the residual connection.
The idea is the following:
-
The similarities between the query of the token and the keys of all tokens are inspected (ex. By the cosine similarity or dot product)
-
This similarity is converted to 0-1 as percentage by SoftMax function
-
The value is modified by the percentage mentioned above to represent the importance of the word relative to the rest of the article.
This structure is applied three times in Transformer model: Encoder, Decoder, and the connection between Encoder and Decoder.
For multiple stacks, the result is just a concat of the stacks.
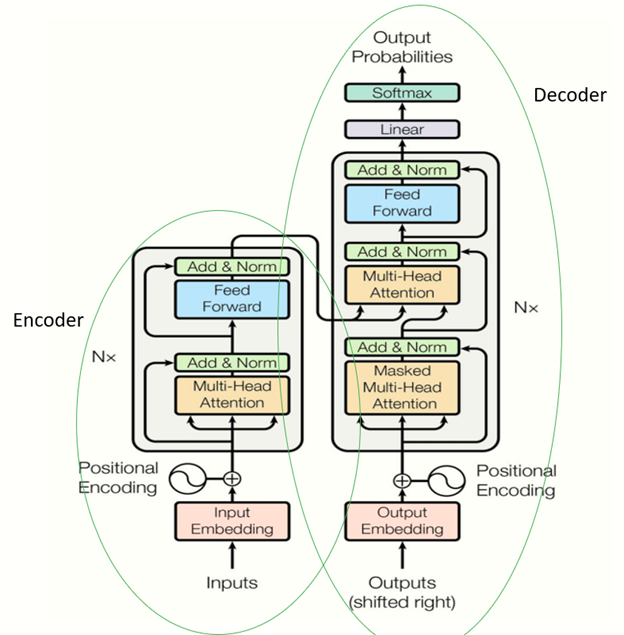
1.3 Encoder
Encoder is an essential idea in machine learning, describing the process of mapping the inputs into the dimensions we want while keeping essential features and patterns to further process.
In transformer model here, the encoder workflow is the following: 1. The numerical form of the text token from Word Embedding is taken as the information of the words.
-
The positional encoding is added up to the input word embedding. The positional encoding is a representation of the information of the position of the word in a sentence of in a document. Ex. One way of doing this is to use sin or cos function to transform to a numeric from.
-
The result of the sum of positional encoding and word embedding is the input values for the Attention structure to generate Query, Key, and Value, as stated above.
-
The output of the attention structure is then processed by Residual connection, seen below, to provide finial results of the encoder part. Let’s call this result as residual-encoder.
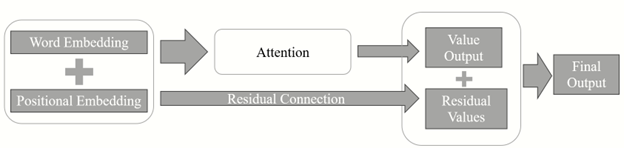
1.3 Residual connection:
The idea of the residual connection is to emphasis the information contained before the convolution process. This idea commonly appears in many variations of the neural network models, such as in image processing, the RintaNet, FPN structures.
Here, the structure is designed by adding up the word embedding and positional embedding.
After the Residual connection, a new set of the key values (we may call it key-encoder), is generated based on residual-encoder values. Theses key values are used later to represent the importance or correlation between the encoders and decoders.
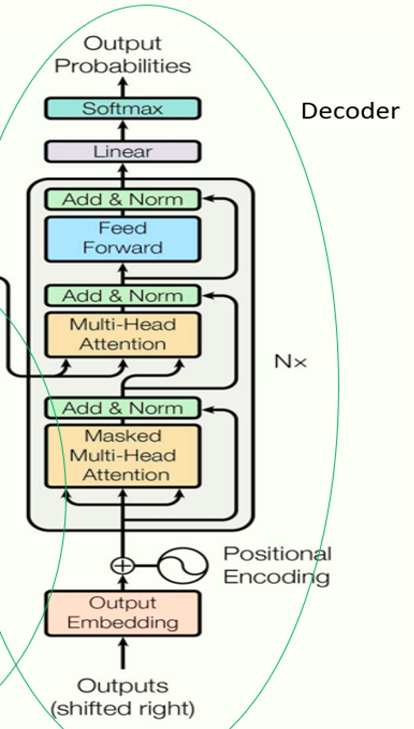
1.4 decoder
-
Decoder starts with the target texts and follows the same structure as the Encoder. We can name the output of the residual connection as the residual-decoder.
-
The new set of the Query values are generated by the residual-decoder values as the same way, (but different weights and bias) in attention structure.
-
The similarity or the correlation between the key values from the residual-encoders and the Query values from the residual-decoders are calculated by the cosine similarity method, or dot product.
-
This similarity modify the new Values and eventually predicts the output, after the softmax function.
1.5 Bert and the pre trained model – Finbert
Bert model, or Bidirectional Encoder Representations from Transformers only takes the encoder part of the Transformer structure, while the Chatgpt only takes the decoder part of the transformer structure. The Bert model can be downloaded in Github via: https://github.com/google-research/bert?tab=readme-ov-file. The Bert model highlights the functions: mask language model to predict mask words, and the Next Sentence Prediction to predict the sequence of the sentences.
One popular pre trained model of Bert in financial field is Finbert. It has 838,720 Downloads last month (2024.1). This model is available via: https://huggingface.co/ProsusAI/finbert and https://github.com/ProsusAI/finBERT?tab=readme-ov-file.
Papers and Resources:
[1]. Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. “Attention Is All You Need.” ArXiv.org. June 12, 2017. https://arxiv.org/abs/1706.03762.
[2]. CMU. Accessed February 23, 2024. http://www.cs.cmu.edu/~02251/recitations/recitation_deep_learning.pdf.
[3]. Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” ArXiv.org. October 11, 2018. https://arxiv.org/abs/1810.04805.
[4]. “Google-Research/Bert.” 2024. GitHub. January 23, 2024. https://github.com/google-research/bert?tab=readme-ov-file.
[5]. “ProsusAI/Finbert · Hugging Face.” n.d. Huggingface.co. https://huggingface.co/ProsusAI/finbert.
[6]. “ProsusAI/FinBERT.” 2024. GitHub. February 22, 2024. https://github.com/ProsusAI/finBERT?tab=readme-ov-file.
[7]. “Transformer Neural Networks, ChatGPT’s Foundation, Clearly Explained!!!” n.d. Www.youtube.com. Accessed February 23, 2024. https://www.youtube.com/watch?v=zxQyTK8quyY&list=WL&index=2.