Introduction
The objective of our project is to develop a sentiment index using data from FOMC speeches to predict the future inflation rate in the United States. In this blog, we will primarily focus on discussing the data scraping and data pre-processing methods that we have implemented and showcase the output obtained from these methods. Furthermore, we will provide an overview of the methods that we plan to utilize in the next phase of our project.
Data Source
The remarks made by Federal Reserve officials are rich with insights, encompassing retrospectives on the economic landscape as well as prospective measures to be enacted. The tone of these discourses reflects the Federal Reserve's economic outlook, providing valuable data for analysis and forecasting future economic trends.
We chose the period starting from January 2019 to March 2024 to examine the contrast in inflation rates pre- and post-COVID. This allows us to analyze the usage patterns of terms associated with inflation, neutral terminology, and deflation, as well as the sentiment expressed in the speeches during this time span.
We scraped the title, date and text of speeches from the the official FOMC website (https://www.federalreserve.gov/newsevents/speeches.htm) .The code is as follows:
def get_detail(detail_url):
response = requests.get(detail_url, headers=HEADERS)
html_element = etree.HTML(response.text)
result = {}
#Get Speech Title
title = html_element.xpath('//h3[@class="title"]//em/text()')
result['title'] = title[0]
#Get Speech Date
date = html_element.xpath('//p[@class="article__time"]/text()')
result['date'] = date[0]
#Get Speech Text
text = html_element.xpath('//div[@class="col-xs-12 col-sm-8 col-md-8"]//p/text()')
text2 = ''
for each in list(text):
if '1. The views' not in each:
text2 = text2 + ' ' + each
else:
break
result['text'] = text2
return result
Then we export the data, save it as a .csv file.
# Export as csv file
def exportcsv():
csvdata = []
i=1
for url in allurls:
csvdata.append(get_detail(url))
print(i)
i+=1
filename = 'output.csv'
fieldnames = ['title', 'date', 'text']
with open(filename, 'w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(csvdata)
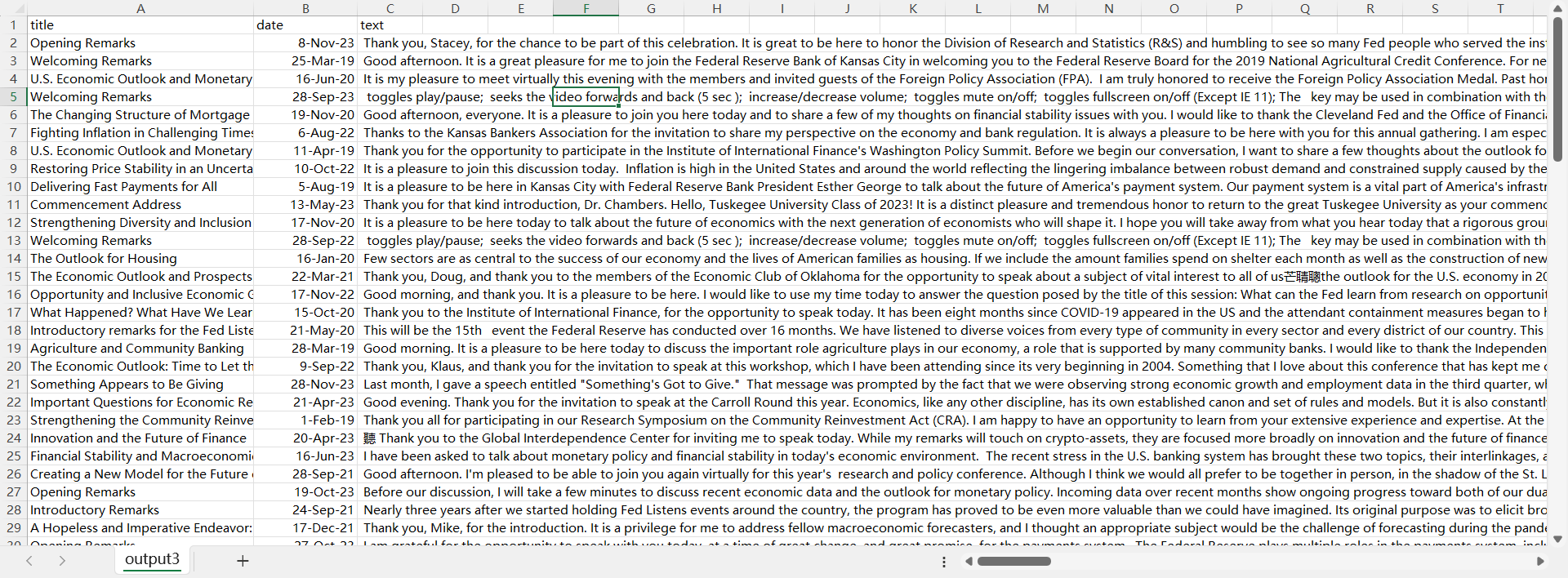
The Output of Data Scraping
After running the web scraping code, we have extracted 3 elements of each speech, which are title, date and text respectively. A sample output is shown as below:
Before we proceed to the data analytics part, data preprocessing is needed first.
Data Preprocessing
To better facilitate future analysis, we use the following steps to process the raw data.
We use Regex to remove useless symbols and letters, the code is as below:
#Load the raw data and merge the data
import pandas as pd
df_raw1= pd.read_csv('C:/Users/a1180/Desktop/MFin7036/project/output1.csv')
df_raw2= pd.read_csv('C:/Users/a1180/Desktop/MFin7036/project/output2.csv')
df_raw3= pd.read_csv('C:/Users/a1180/Desktop/MFin7036/project/output3.csv')
df_raw4= pd.read_csv('C:/Users/a1180/Desktop/MFin7036/project/output4.csv')
df_raw=pd.concat([df_raw1,df_raw1,df_raw1,df_raw1]) #save the raw data
df=df_raw
print(df)
df.columns
#Data preprocessing
#convert all uppercases to lowercases
df['text']=df['text'].str.lower()
#Remove any special character, punctuation and numbers
import re
def keep_letters_and_spaces(text):
'''We only keep letters and spaces in the string here'''
return re.sub(r'[^a-zA-Z\s]','',text)
df['text']= df['text'].apply(keep_letters_and_spaces)
#Remove stopwords
from nltk.corpus import stopwords
def no_stop (text) :
return [w for w in text.split() if w not in stopwords.words('english')]
df['text'] = df['text'].apply(no_stop)
#Lemmatize the words
from nltk.stem import WordNetLemmatizer
def lemmatization (text) :
wnl = WordNetLemmatizer ( )
return [ wnl.lemmatize ( w ) for w in text ]
df['text'] = df['text'].apply(lemmatization)
df['text']=df['text'].apply(lambda x:' '.join(x))
#Output the cleaned data as csv file
outputpath = 'C:/Users/a1180/Desktop/MFin7036/project/cleaned.csv'
df.to_csv(outputpath,sep=',',index=False,header=True)
In natural language processing, useless words are called stop words. We want to eliminate the stop words (eg. "a", "and" and "the") which can appear in high frequency but have little impact on the sentiment. We can achieve this goal by storing a list of words that we want to stop using. NLTK in python has a list of stop words stored in English.
After data cleaning process, output is produced and saved in a .csv file. A screenshot of dataset is as follows:

Future Discussion
After the basic data processing, we can use the following steps to do further execution:
Sentiment Analysis and Scoring
1> Dictionary-based approaches: Use a predefined sentiment lexicon to determine the sentiment score based on the emotional value of words.
2> We use the time interval as a weighting factor to improve the analysis model.
3> Machine Learning approaches: Use traditional machine learning algorithms (e.g., Naive Bayes, Logistic Regression, SVM, Random Forest) or deep learning algorithms (e.g., CNN, RNN, LSTM, BERT) to train a model for sentiment classification.
Application of Results
Market Prediction: Correlate the results of sentiment analysis with past inflation data, and to predict future trends.