Improvements on Data Source
In the selection of text data, in addition to considering the sufficient amount and timeliness of data, we also need to carefully analyze the specific content of text data.
Bitcoin Talk
First, we chose Bitcoin Talk as the textual data source, which is a forum dedicated to discussions related to the Bitcoin ecosystem. It provides a platform for discussing Bitcoin, news, innovations, and other topics related to the cryptocurrency.
We crawled 41,375 comments from 2014 to the present from the website and gave each comment a sentiment score using TextBlob()
df['title'] = df['title'].astype(str)
df['polarity'] = df['title'].apply(lambda x: TextBlob(x).sentiment.polarity)
df['subjectivity'] = df['title'].apply(lambda x: TextBlob(x).sentiment.subjectivity)
However, we found no correlation between the sentiment polarity and the bitcoin price.
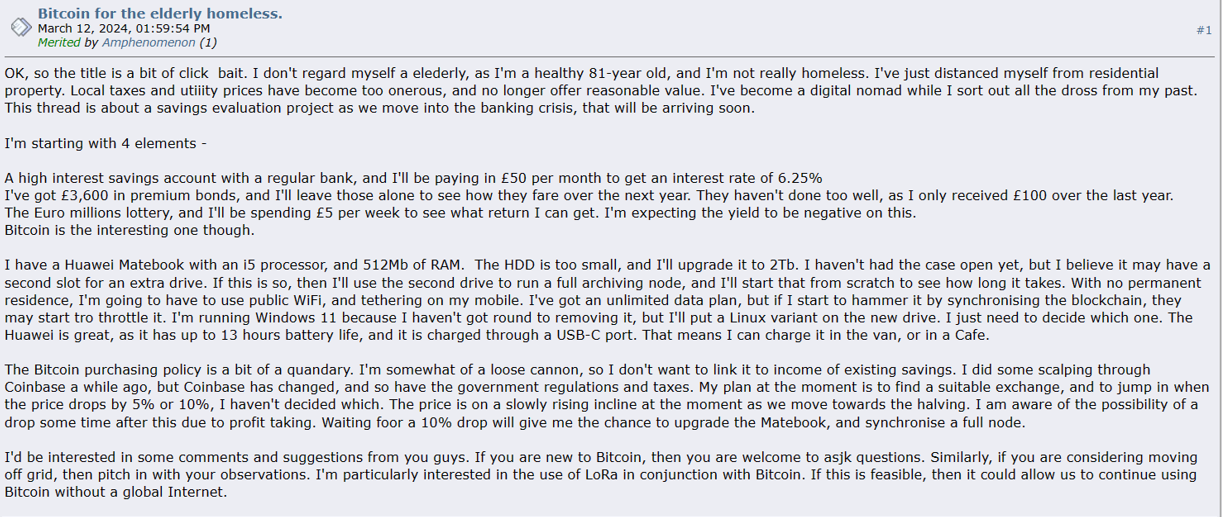
We dug into the comments and found that people were more likely to share their own experiences with Bitcoin than to discuss the latest news. Their comments are usually in a calm mood and therefore not a very good source for sentiment analysis. Below is an example of a comment:
Yahoo Finance
On Yahoo's Bitcoin forum, people were enthusiastically discussing the latest news and their expectations for the price of bitcoin.
We crawled 15716 effective comments from 2022 to the present from Yahoo. Even though the number is less than 40% of that from bitcoin talk, the results got better.
Improvements on Logistic Regression
We used the sentiment score and normalized trading volume as independent variables, the rise and fall of prices as the dependent variable and ran the logistic model. However, the prediction effect of the model is not ideal. The auc of the model is shown below, less than 0.5.
ROC-AUC Score: 0.44077879935100056
Classification
We split the score five classifications in order to reduce the noise and handle the nonlinear relationship better. The AUC of the model had increased, but was still close to 0.5.
ROC-AUC Score: 0.502974580854516
UBL Factor
We borrowed a strategy from a quantitative trading research to construct the UBL factor, which is a factor constructed according to the upper and lower shadow lines. These are some of the formulas we used to calculate the shading and thus the UBL:
candlestick_up = High – Max ( Close, Open )
Williams_down = Close – Low
UBL = std ( candlesticks_up ) + mean ( Williams_down )
After adding the UBL factor, the model has been further improved:
ROC-AUC Score: 0.5413444378346222