
Building Alternative NLP Sentiment Factors - Data Crawling
This blog aims to construct an NLP analysis system by extracting the management’s discussion and analysis of financial condition and results of operations from US stock reports. The goal is to derive sentiment evaluations such as optimism, neutrality, and pessimism from the management’s discourse. By combining this with the volatility and price fluctuations of the stock before and after the quarterly report is released, we hope to draw certain conclusions.
Pre section - Get the constituents of the S&P 500
Because the crawling process takes too long, we are unable to crawl all the companies on the market. Therefore, we filtered the companies before crawling, and the companies we chose are the constituents of the S&P 500.
We use WRDS to obtain the constituents of the S&P 500. The first problem we encountered is that the same ticker can represent different companies at different points in time due to delisting and changes. Therefore, we use permno to represent different companies.
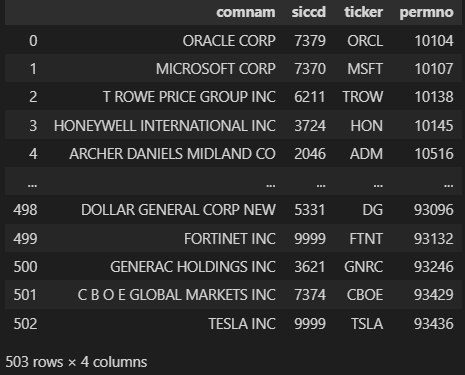
We have obtained 503 constituents of the S&P 500. The reason for this is that some companies, such as Alphabet, have issued multiple classes of shares.
Next, in order to get the industry classification of S&P 500 companies, we use siccd for division. The industry classification rules of sci are as follows
# Reference: https://www.osha.gov/data/sic-manual
def sic_to_sector(sic):
sector = None
if sic is not None:
sic2 = int(str(sic)[:2])
if sic2 <= 9:
sector = 'Agriculture, Forestry, And Fishing'
elif sic2 <= 14:
sector = 'Mining'
elif sic2 <= 17:
sector = 'Construction'
elif sic2 <= 39:
sector = 'Manufacturing'
elif sic2 <= 49:
sector = 'Transportation, Communications, Electric, Gas, And Sanitary Services'
elif sic2 <= 51:
sector = 'Wholesale Trade'
elif sic2 <= 59:
sector = 'Retail Trade'
elif sic2 <= 67:
sector = 'Finance, Insurance, And Real Estate'
elif sic2 <= 89:
sector = 'Services'
elif sic2 <= 99:
sector = 'Public Administration'
return sector
Final result of the S&P 500 companies as follow:

Step 1. Obtain CIK
We can obtain each company’s financial reports through Edgar (the website of the U.S. Securities and Exchange Commission).First, we need to register our email so that we can obtain data through the official API in the future. Here is the website to register your email.
CIK is a unique code for each company, and we can use it to obtain financial reports
import part:
from secedgar import filings, FilingType
import requests
import pandas as pd
import yfinance as yf
import time
login_info = {'User-Agent': "Enter your registered email"} # Enter your direct email here. Note that registration is required at https://www.sec.gov/developer
# Retrieve the original data table
raw_data = requests.get("https://www.sec.gov/files/company_tickers.json", headers=login_info)
# Parse the data
df = pd.DataFrame(raw_data.json().values())
# CIK is a 10-digit number, fill with zeros
df['cik_str'] = df['cik_str'].astype(str).str.zfill(10)
In this code, we are retrieving a JSON file from the SEC website that contains company ticker information. Then parse this data into a pandas DataFrame. The ‘cik_str’ column in the DataFrame contains the CIK (Central Index Key) numbers for the companies, which are unique identifiers assigned by the SEC. We ensure that these CIK numbers are 10 digits long by padding them with zeros on the left if necessary. This is done using the zfill method.
Step 2. Obtain financial reports through CIK
result = pd.DataFrame()
for ticker in df['ticker']:
# Obtain the specific stock's CIK
time.sleep(0.1)
CIK = df[df['ticker']==ticker]['cik_str'].values[0]
# Retrieve the data
try:
data = requests.get(f'https://data.sec.gov/submissions/CIK{CIK}.json', headers=login_info)
# Convert the data into a DataFrame
data = pd.DataFrame.from_dict(data.json()['filings']['recent'])
# Obtain the quarterly reports (10-Q), can be adjusted according to needs, annual reports are 10-K
annual_reports = data[data['form']=='10-Q']
# Remove the "-" in the 'accessionNumber' column
annual_reports.loc[:, 'accessionNumber'] = annual_reports['accessionNumber'].str.replace('-', '')
# Only keep the necessary columns
annual_reports['ticker'] = ticker
annual_reports = annual_reports[['ticker','accessionNumber','primaryDocument','filingDate','reportDate','form']]
# Construct the link to open the file
annual_reports['link'] = "https://www.sec.gov/Archives/edgar/data/" + CIK.lstrip('0') + "/" + annual_reports['accessionNumber'].replace('-','') + "/" + annual_reports['primaryDocument']
except:
pass
result = pd.concat([result, annual_reports])
result.reset_index(inplace=True)
del result['index']
# Note that the 'link' might not be fully displayed, you need to open it in Excel or directly read it through Python.
The rule for the URL of the quarterly reports on the SEC website is as follows:
For example, In https://www.sec.gov/Archives/edgar/data/1507605/000149315223039927/form10-q.htm,
where 1507605 is the CIK with the leading 0 removed
000149315223039927 is the 'accessionNumber' field
form10-q.htm is the 'reportDate' field
In this code, we first retrieve all the reports published by each company through the CIK. Here, the CIK needs to be a 10-digit number.
data = requests.get(f'https://data.sec.gov/submissions/CIK{CIK}.json', headers=login_info)
We then filter out the quarterly reports (10-Q) that we want. If you need other reports, you can replace 10-Q with other fields. For example, 10-K is the annual report.
annual_reports = data[data['form']=='10-Q']
Finally, in accordance with the rules of the website, we concatenate the URL of the financial report.
Step 3. Text Extracting
Now we need to extract the text from the MD&A section of the URL we just obtained in order to prepare for our upcoming text analysis.
We first access the financial report webpage through the URL we previously crawled. Then, we use regular expressions to locate the content of MD&A (Management’s Discussion and Analysis) and Risk Factors.
The core code is as follows:
def getMDAndAFromFile(link_txt):
time.sleep(0.1)
try:
file_content = cleanText(requests.get(link_txt,headers=login_info).text)
rf = re.search(r'Item[\s]?5[.|:]?[\s]*?Market.{100,}Item[\s]?7[.|:]?[\s]*?Management[\S]?s[\s]?Discussion[\s]?and[\s]?Analysis.{,50}Operations(.{30,})Item[\s]?7A', file_content, re.I|re.S)
# rf = re.search(r"(?is)Item.{0,10}?2.{0,10}?(Management's\s+Discussion\s+and\s+Analysis[\s\S]*?)(?=Item.{0,10}?3)", file_content, re.I|re.S)
if rf:
text_item2 = re.sub(r'\s{2,}',' ',rf.group(1))
return text_item2
else:
return 'None'
except:
return 'None'
def getRiskFactorFromFile(link_txt):
time.sleep(0.1)
try:
file_content = cleanText(requests.get(link_txt,headers=login_info).text)
rf = re.search(r'Item[\s]?1[.|:]?[\s]*?Business.{30,}Item[\s]?1A[.|:]?[\s]*?Risk[\s]?Factors(.{30,}?)Item[\s]?1B',
file_content, re.I|re.S)
if rf:
text_item1a = re.sub(r'\s{2,}',' ',rf.group(1))
return text_item1a
else:
rf = re.search(r'Item[\s]?1[.|:]?[\s]*?Business.{30,}Item[\s]?1A[.|:]?[\s]*?Risk[\s]?Factors(.{30,}?)Item[\s]?2',
file_content, re.I | re.S)
if rf:
text_item1a = re.sub(r'\s{2,}',' ',rf.group(1))
return text_item1a
else:
return 'None'
except:
return 'None'
We first log into the webpage through the 'link_txt' field, then extract the content we want and make some format adjustments. If we encounter any problems, we return 'None'.
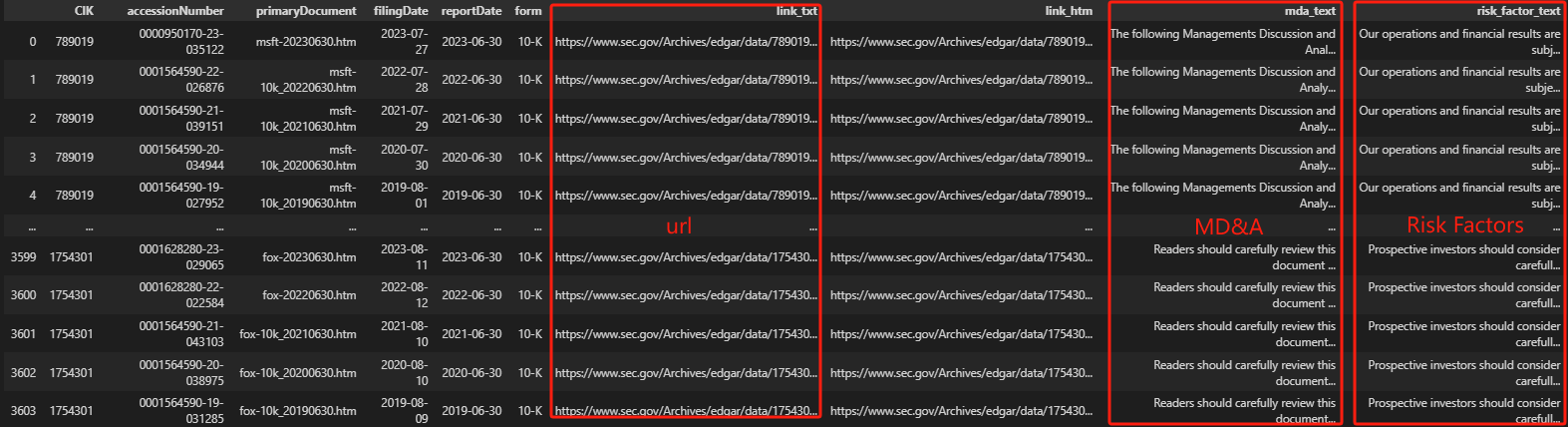
In the end, we can see that the data results we obtained are as follows:
Thoughts during the process
When extracting MD&A and risk factors, we encountered several issues. Some companies’ 10-Q reports lack the risk factors section. Ultimately, we substituted 10-K reports for 10-Q, resulting in a significant reduction in our dataset. Regarding company selection, we opted for constituents of the S&P 500 index as of December 31, 2023. Initially, we considered choosing companies from the same industry for better comparability. However, considering data comprehensiveness and varying market capitalizations, we decided to focus on S&P 500 companies, which we believe provides greater representativeness.