Mini-Blog
In this blog, we tackle some challenges we encountered in earlier stages. Our work include data collection, handling the "toomanyrequests" issue, and addressing the specific concerns regarding post number limitations. In the following sections, we will show details for data cleaning, overcoming API rate limits, and dealing with limitations.
Data Cleaning
In last post, we mentioned about some special elements in our datasets. We now get rid of those elements using regular expression. Those elements include: bot garbage message, markdown formatting string, URLs, '\n', Emojis. Removing these elements helps clean the data, reducing complexity and noise, which in turn enhances the performance of sentiment analysis models. This preprocessing step ensures that the analysis is focused on the text with opinions or feelings. The work includes:
-
Filter comments that contains bot garbage massage. specifically filtering the markdown table format
sample = sample[~sample['Comment Body'].str.contains(':--|:--|:--|:--')] # filter comments containing table
#or
df_submissions = df_submissions[~(df_submissions['cdistinguished'] == 'moderator')]
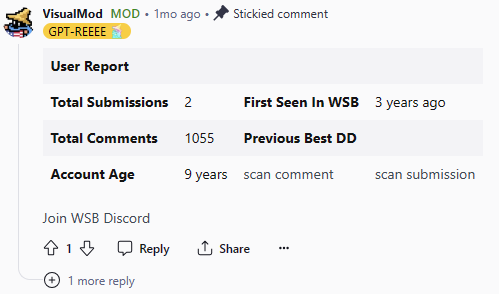
[!NOTE]
Tables are in format of ':--|:--|:--|:--'. Those table usually contain advertisements. The advertisements are usually posted by the "moderator"s. They can be removed by simply filtering out the data 'cdistinguisied' == 'moderator'.
-
Remove markdown formatting string
sample['Comment Body'] = sample['Comment Body'].apply(strip_markdown.strip_markdown) # clean all markdown format
[!NOTE]
'strip_markdown' is a python package that's used to remove the markdown formats.
-
Remove URL
def remove_urls(text):
"""
Removes URLs from a given text string.
"""
return re.sub(r'http\S+', '', text)
sample['Comment Body'] = sample['Comment Body'].apply(remove_urls) # remove urls
[!NOTE]
URLs usually start with 'http\S+'.
-
Remove returning line "\n"
sample['Comment Body'] = sample['Comment Body'].str.strip('\n')
[!NOTE]
'\n' represents next line in the text.
-
Remove Emoji
def remove_emoji(text):
emoji_pattern = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F700-\U0001F77F" # alchemical symbols
u"\U0001F780-\U0001F7FF" # Geometric Shapes Extended
u"\U0001F800-\U0001F8FF" # Supplemental Arrows-C
u"\U0001F900-\U0001F9FF" # Supplemental Symbols and Pictographs
u"\U0001FA00-\U0001FA6F" # Chess Symbols
u"\U0001FA70-\U0001FAFF" # Symbols and Pictographs Extended-A
u"\U00002702-\U000027B0" # dingbats
u"\U000024C2-\U0001F251"
"]+", flags=re.UNICODE)
return emoji_pattern.sub(r'', text)
[!NOTE]
The U thing in the list is the Unicode of the emojis.
Problem in collecting data
Fixed Number of Posts
Since, for now, we only focus on the subreddit 'r/wallstreetbets', we tested and found that only a fixed number of posts will be get from reddit no matter how many times you try. For example, we search the topic ''AI" in 'r/wallstreetbets', and we can at most get 243 posts overall. That may cause a shortage of data for our project. To solve this problem, we decide to put data in several topics with strong connections together as a whole.
TooManyRequests
While we are collecting data using praw, we found reddit actually set a limits on how many posts and comments we can collect in a certain period of time. In order to solve this problem, we make a simple modification to solve the problem:
while True:
try:
post.comments.replace_more(limit=None, threshold=0)
break
except:
print("Handling replace more exception”)
time.sleep(60)
[!NOTE]
We guess that happens because there is a particularly large post with numerous comments, exceeding the package size limit for API responses. Therefore, we added sleep() function to pass the restriction period triggered by the
try-exceptblock. Plus, we might adjustlimitterm according to our requirements.