Background and Goal
Our mission is to analyze the relationship between the sentiment in Federal Open Market Committee Statements and the yields of government bonds. This blog post mainly discusses the code and challenges we encountered during data processing and integration.
For our data selection, we chose the monthly 30-year Treasury Yield (^TYX) as our financial data. And we utilized the Federal Open Market Committee (FOMC) Statements from January 2000 to January 2024 as our sentiment analysis database.
Data Collection
To capture the text data from FOMC Statements, we initially visited the FOMC's official website. Upon attempting to view the details of each month's Statement, we observed that the website's URL changes, indicating that the site is not dynamic, thus rendering common tools like Selenium ineffective for text scraping. Consequently, we resorted to using the requests package in Python for web scraping, successfully collecting 202 FOMC Statements into a single txt file.
A significant challenge encountered was the location of statements on different URLs for periods before and after 2018, necessitating web scraping from two distinct web addresses: FOMC Historical Materials and FOMC Meeting calendars and information to compile the complete dataset.
The detailed steps for scraping FOMC Statement text data involve:
1. Using the requests package to retrieve the URLs of the statements.
2. Employing BeautifulSoup to extract the content of the statements.
Part of our codes for data collection is shown below:
def main():
allStatementContent = ''
response = requests.get('https://www.federalreserve.gov/monetarypolicy/fomccalendars.htm', headers=headers)
html = response.text
soup = BeautifulSoup(html,'html.parser')
panels = soup.find_all('div',{'class':'panel panel-default'})
html_links = []
for panel in panels:
heading = panel.find('div',{'class':'panel-heading'})
meetings = panel.find_all('div',{'class':'fomc-meeting'})
for meet in meetings:
month = meet.find('div',{'class':'fomc-meeting__month'}).text.strip().replace('/',' ')
statement = meet.find('div',{'class':'col-xs-12 col-md-4 col-lg-2'})
links = statement.find_all('a')
html_link = None
for link in links:
if 'HTML' in link.text:
html_link = 'https://www.federalreserve.gov' + link['href']
print(heading.text,month,html_link)
html_links.append((heading.text,month,html_link))
#create a file which contains all statements
if not os.path.exists("files"):
os.makedirs("files")
for year, month, link in html_links:
if link:
fileName = f'files/{year} {month}.txt'
content = getContent(link)
allStatementContent += content
# import content
with open(fileName, 'w', encoding='utf-8') as file:
file.write(content)
print(f'Statement {fileName} is saved.')
year_links = getYearLinks()
for year,year_link in year_links:
html_links = getYearStatementLinks(year_link)
for date,html_link in html_links:
if html_link:
fileName = f'files/{date}.txt'
content = getContent(html_link)
allStatementContent += content
with open(fileName, 'w', encoding='utf-8') as file:
file.write(content)
print(f'Statement {fileName} is saved.')
print(allStatementContent)
main()
We directly downloaded the financial data, specifically the monthly 30-year Treasury Bond yield from January 2000 to January 2024 from Yahoo Finance. Although daily data might offer more granularity for regression and forecasting, the FOMC statements are typically released about once a month, making the use of monthly average yields a suitable match.
Data Observation
Upon examining the FOMC Statement text, it was noted that the extracted information includes not only the main body of the statement but also the date of the speech, the speaker, participants, the main content, related information, and current FAQs. Regarding the Monthly 30-years Treasury Yield data, it is important to focus specifically on the dates and the Adjusted Close values.
Text processing
Open and Read Text
After scraping the information needed from the FOMC website, we arranged all the content into a text document. We opened and read the text first and then imported all the modules and packages we needed.
import nltk
import re
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.stem import PorterStemmer, WordNetLemmatizer
# download necessary NLTK packages
nltk.download('stopwords')
nltk.download('wordnet')
with open('output.txt', 'r', encoding='utf-8') as f: # open text
text = f.read() # read text
#print(text)
The statement example is showed below:
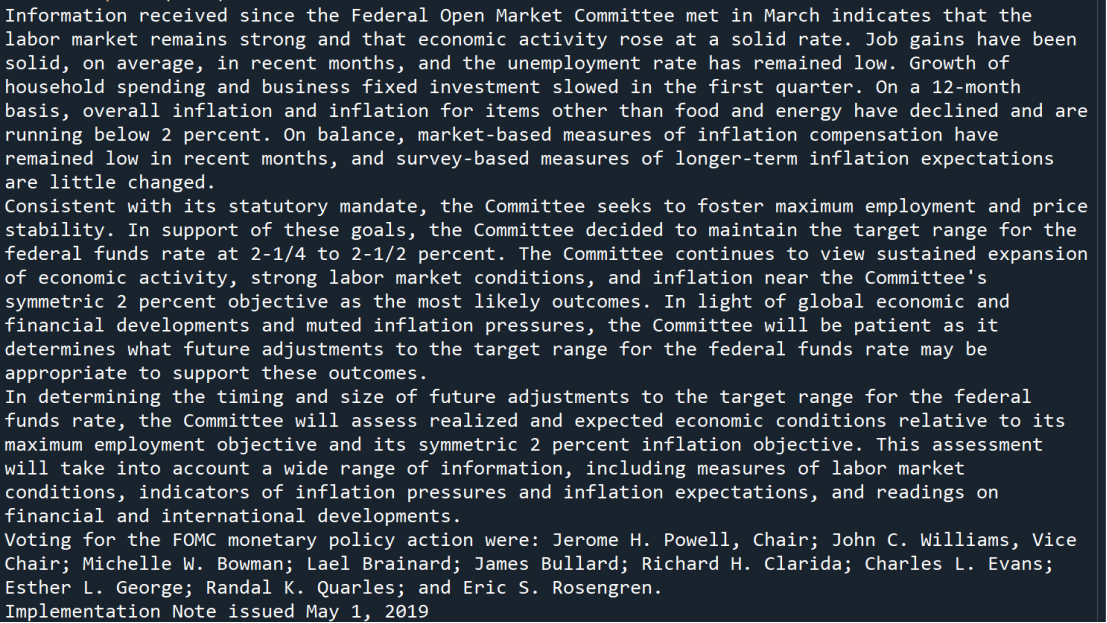
Information received since the Federal Open Market Committee met in March indicates that the labor market remains strong and that economic activity rose at a solid rate. Job gains have been solid, on average, in recent months, and the unemployment rate has remained low. Growth of household spending and business fixed investment slowed in the first quarter. On a 12-month basis, overall inflation and inflation for items other than food and energy have declined and are running below 2 percent. On balance, market-based measures of inflation compensation have remained low in recent months, and survey-based measures of longer-term inflation expectations are little changed. Consistent with its statutory mandate, the Committee seeks to foster maximum employment and price stability. In support of these goals, the Committee decided to maintain the target range for the federal funds rate at 2-1/4 to 2-1/2 percent. The Committee continues to view sustained expansion of economic activity, strong labor market conditions, and inflation near the Committee's symmetric 2 percent objective as the most likely outcomes. In light of global economic and financial developments and muted inflation pressures, the Committee will be patient as it determines what future adjustments to the target range for the federal funds rate may be appropriate to support these outcomes. In determining the timing and size of future adjustments to the target range for the federal funds rate, the Committee will assess realized and expected economic conditions relative to its maximum employment objective and its symmetric 2 percent inflation objective. This assessment will take into account a wide range of information, including measures of labor market conditions, indicators of inflation pressures and inflation expectations, and readings on financial and international developments. Voting for the FOMC monetary policy action were: Jerome H. Powell, Chair; John C. Williams, Vice Chair; Michelle W. Bowman; Lael Brainard; James Bullard; Richard H. Clarida; Charles L. Evans; Esther L. George; Randal K. Quarles; and Eric S. Rosengren. Implementation Note issued May 1, 2019
Split the text into multiple sentences
Considering the entire statement content was complex and scoring its sentiment might be inaccurate or difficult, so we splited each statement into several sentences in a tokenized way, and then deleted punctuations in each sentence. The NLTK library provides a few tokenizers that are specialized for certain applications, such as word or sentence tokenization. To keep the meaning of text, we tried to use sentence tokenization.
# perform sentence tokenization
sentences = sent_tokenize(text)
print(sentences)
Stopwords
After that, we thought stopwords removal is a necessary processing, and lowercase is to unify the letters form. The list comprehension method below is referred by codes from GitHub repositories.
# perform lowercase, word tokenization and stopword removal
stop_words = set(stopwords.words('english'))
tokens = [word.lower() for sent in sentences for word in word_tokenize(sent) if word.lower() not in stop_words]
print(tokens)
Stemming or Lemmatization
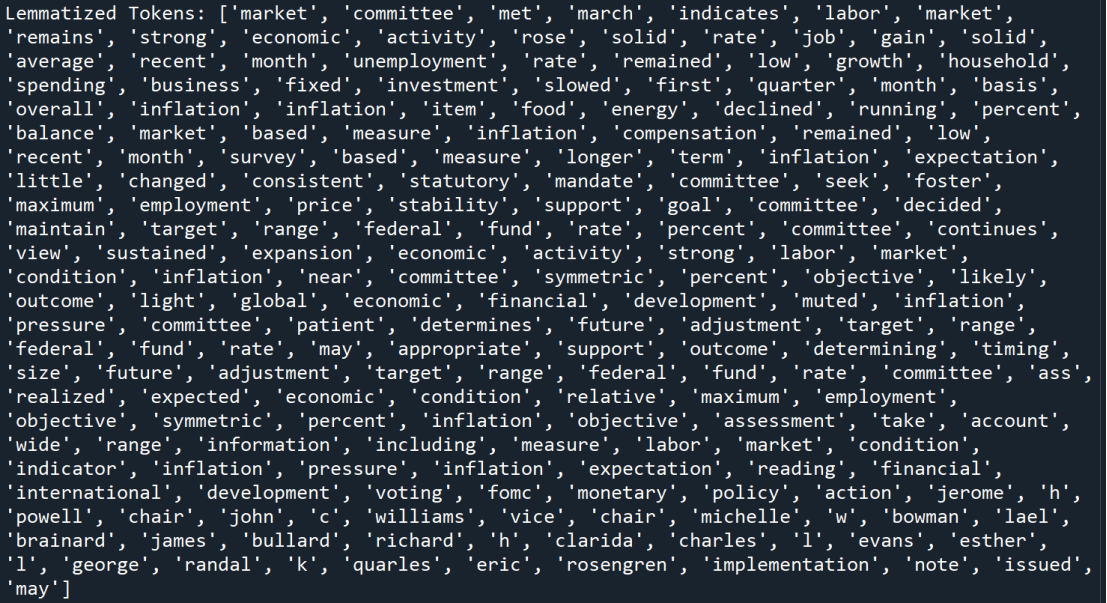
Furthermore, we decided to perform stemming or lemmatization for combining the words of complex grammatical forms. After these steps, the new statement content is showed below:
# perform stemming
ps = PorterStemmer()
stemmed_tokens = [ps.stem(token) for token in tokens]
# perform lemmatization
wnl = WordNetLemmatizer()
lemmatized_tokens = [wnl.lemmatize(token) for token in tokens]
Lemmatized Tokens: ['market', 'committee', 'met', 'march', 'indicates', 'labor', 'market', 'remains', 'strong', 'economic', 'activity', 'rose', 'solid', 'rate', 'job', 'gain', 'solid', 'average', 'recent', 'month', 'unemployment', 'rate', 'remained', 'low', 'growth', 'household', 'spending', 'business', 'fixed', 'investment', 'slowed', 'first', 'quarter', 'month', 'basis', 'overall', 'inflation', 'inflation', 'item', 'food', 'energy', 'declined', 'running', 'percent', 'balance', 'market', 'based', 'measure', 'inflation', 'compensation', 'remained', 'low', 'recent', 'month', 'survey', 'based', 'measure', 'longer', 'term', 'inflation', 'expectation', 'little', 'changed', 'consistent', 'statutory', 'mandate', 'committee', 'seek', 'foster', 'maximum', 'employment', 'price', 'stability', 'support', 'goal', 'committee', 'decided', 'maintain', 'target', 'range', 'federal', 'fund', 'rate', 'percent', 'committee', 'continues', 'view', 'sustained', 'expansion', 'economic', 'activity', 'strong', 'labor', 'market', 'condition', 'inflation', 'near', 'committee', 'symmetric', 'percent', 'objective', 'likely', 'outcome', 'light', 'global', 'economic', 'financial', 'development', 'muted', 'inflation', 'pressure', 'committee', 'patient', 'determines', 'future', 'adjustment', 'target', 'range', 'federal', 'fund', 'rate', 'may', 'appropriate', 'support', 'outcome', 'determining', 'timing', 'size', 'future', 'adjustment', 'target', 'range', 'federal', 'fund', 'rate', 'committee', 'ass', 'realized', 'expected', 'economic', 'condition', 'relative', 'maximum', 'employment', 'objective', 'symmetric', 'percent', 'inflation', 'objective', 'assessment', 'take', 'account', 'wide', 'range', 'information', 'including', 'measure', 'labor', 'market', 'condition', 'indicator', 'inflation', 'pressure', 'inflation', 'expectation', 'reading', 'financial', 'international', 'development', 'voting', 'fomc', 'monetary', 'policy', 'action', 'jerome', 'h', 'powell', 'chair', 'john', 'c', 'williams', 'vice', 'chair', 'michelle', 'w', 'bowman', 'lael', 'brainard', 'james', 'bullard', 'richard', 'h', 'clarida', 'charles', 'l', 'evans', 'esther', 'l', 'george', 'randal', 'k', 'quarles', 'eric', 'rosengren', 'implementation', 'note', 'issued', 'may']
Reduce Useless Data
Besides, we removed weblinks and URLS, emails, phone numbers, and references in the FOMC statements which were not relevant to the sentiment analysis. We used re.sub to substitute the useless words, numbers and links, and they were replaced by the whitespaces. In this process, additional whitespaces were created, so we wrote another code to remove the whitespaces.
#Remove website links and URLs
def clean_URLs(statements):
return re.sub(r'http\S+|www\S+|https\S+',' ',statements)
text=clean_URLs(text)
#Remove email address
def clean_Emails(statements):
return re.sub('([\w\.\-\_]+@[\w\.\-\_]+)',' ',statements)
text=clean_Emails(text)
#Remove phone numbers
def clean_PhoneNum(statements):
return re.sub('(\d+)',' ',statements)
text=clean_PhoneNum(text)
#Remove references
def clean_references(statements):
return statements.split("\n1")[0]
text=clean_references(text)
#Remove additional white space
def whitespace(statements):
statements.strip()
' '.join(statements.split())
return re.sub(r'\s+',r' ',statements)
text=whitespace(text)
print(text)
Reduce Number of Words
Finally, to reduce the number of words in the text, we checked the frequency of the words which set the threshold level of 0.5%. Firstly, clean the punctuations to better count the words. Next, count the frequency of all words and total words. If the percentage of the word of total text is less than 0.5%, we would remove it from the text. However, we found that all words in the statements were less than 0.5%, even less than 0.005%. In this case, we changed to reduce the words which appeared less often. We calculated the threshold by number of total words multiple by e-05 (81147*0.005%), which equals to 4.05735. As a result, the lowest frequent threshold was set at 5 words. One thing that can be thought is that if we change the threshold level to the lowest frequent 10/15…words, the degree of effect on the sentiment analysis and data analysis can be different.
#Reducing number of words
text=text.replace(',',' ').replace('.',' ').replace('!',' ').replace('?',' ').replace(';',' ').replace(':',' ')
for char in "!'#$&%()*+,-./:;<=>?@[\\\\]^_{|}~":
text=text.replace(char,' ')
text_copy=text
text_copy=text_copy.split()
counts={}
for i in text_copy:
counts[i]=counts.get(i,0)+1
items=list(counts.items())
TotalWords=sum(list(counts.values()))
counts_items=counts.items()
sort_items=sorted(counts_items,key=lambda x:x[1])
key_for_del=[]
for keys,values in sort_items[:5]:
key_for_del.append(keys)
print(key_for_del)
for i in key_for_del:
text=text.replace(i,'')
print(text)
Word Cloud
We used wordcloud to create a word cloud and displayed the result using matplotlib. The data we used is mainly based on the previously processed text. We have observed the occurrence of names in the text such as "John C", "C Willams", "L Kohn", etc. Therefore, we remove person names from the text by using spaCy. We load the spaCy English model (en_core_web_sm) and process the text to filter out tokens with the entity type 'PERSON'. The filtered text is stored in the filtered_text variable.
# Remove person names using spaCy
import spacy
processed_text = ' '.join(lemmatized_tokens)
nlp = spacy.load('en_core_web_sm')
doc = nlp(processed_text)
filtered_text = ' '.join([token.text for token in doc if token.ent_type_ != 'PERSON'])
The mask arguement is used here to give the word cloud a cloud-like shape:\
mask = np.array(Image.open('group-NLPGiveMeFive_01_image-cloud.png'))\
Here we add the ‘cloud.png’ image using the NumPy array and store it as a mask variable.

Then we generate the word cloud:
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
# Generate the word cloud
wordcloud = WordCloud(mask = mask,
background_color='white',
stopwords=STOPWORDS,
min_font_size = 4).\
generate(filtered_text)
# Display the word cloud using Matplotlib
plt.figure(figsize=(8, 5), facecolor=None)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.tight_layout(pad=0)
plt.show()
Running the code above, you will get an inverted word cloud, as we previously attempted. In the help documentation for wordcloud, you will find that in the most recent version: All white (#FF or #FFFFFF) entries will be considerd "masked out" while other entries will be free to draw on. Since our image actually has a transparent background, we obtained such a result.

To fix this issue, we create a copy of the mask array called temp_mask and use NumPy indexing to change black pixel values (0) to white (255) and white pixel values (255) to black (0).
# Color swapping
mask = np.copy(temp_mask)
mask[np.where(temp_mask == 0)] = 255 # Change black pixel values to white
mask[np.where(temp_mask == 255)] = 0 # Change white pixel values to black
Then, we get a "real" word cloud:
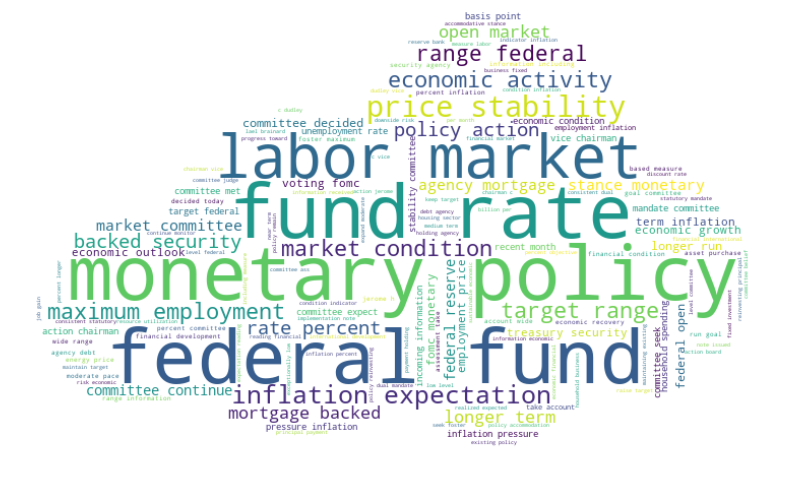
Conclusion
We conducted the data collection, data observation, data preprocessing and cleaning, and word cloud to support further processes, including sentiment analysis, data analysis, suggestions, and limitations. Subsequent details can refer to the second blog in the future.