By Group "Alpha Miner"
This blog post documents our textual data collection from financial news websites and Twitter website in order to analyze the market sentiment. All content regarding webscraping is only for academic demonstration purposes, and we respect the download policies.
1. Selection of News Websites for Webscraping
There are many financial news websites such as Yahoo finance, Bezinga, and Barron, but not all of them are suitable for web-scraping. So we try to investigate each website to find the best one.
1)Yahoo finance
We can easily find the financial news related to the company on yahoo finance. But we need to continuously scroll down to get news in earlier days. What’s more, the date is vague, so we can’t find the return data of a specific day.
2)Benzinga
Benzinga is a free online news source that posts 50 to 60 articles daily on average, containing financial news about the world's financial markets as well as financial commentary and analysis.
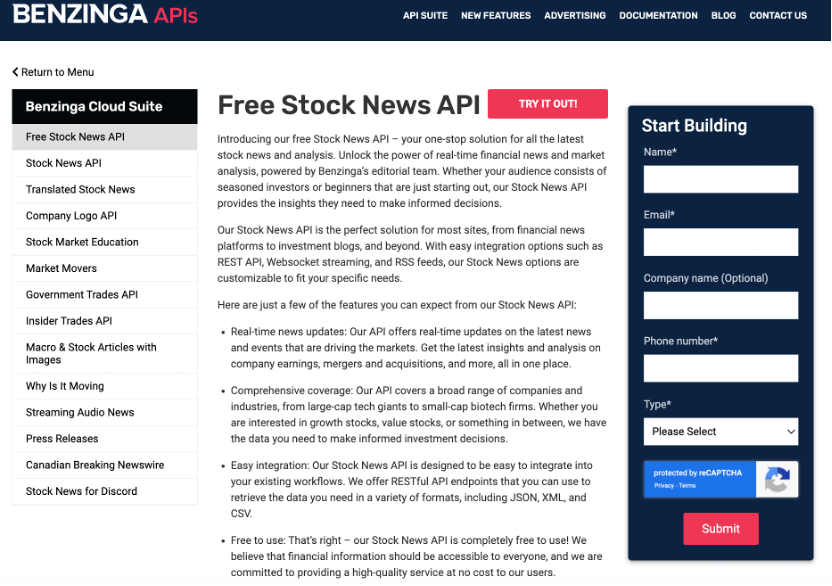
Benzinga provides a full set of official APIs , among which we will opt for its free stock news API. So we first register and get the token, we can obtain the news data by simply inputting the stock tickers of the thirty companies and the date range. However, the website only provides access to data for the past year.
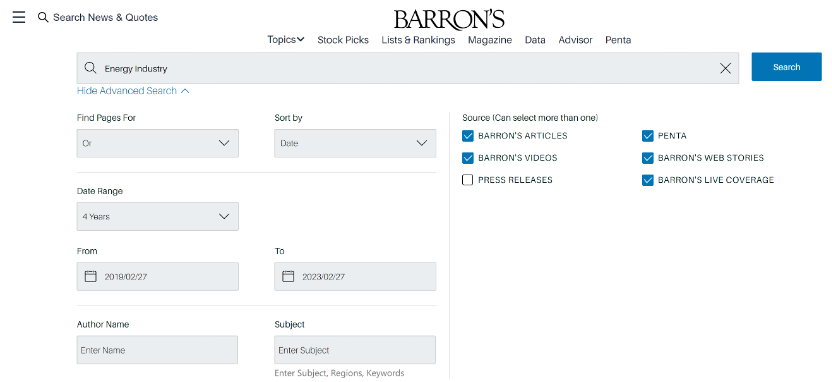
3)Barron's
Barron serves as a great resource for us to use selenium to download data. The url of Barron's can show all the search parameters such as search theme, date range and page numbers. What’s more, the data is neatly arranged, so we can just use the xpath to find the data. It also provides us with access to news data for the past four years.
So we choose Bezinga and Barron as our data sources of financial news, and we are equipped with the necessary webscraping skills to deal with both static and dynamic websites based on our the learnig of 9.2 Web Scraping.
2. Data Collection from selected news websites
1)Benzinga
Collecting data from Benzinga is relatively straightforward, as the they published an official document with detailed instructions, and package of request is sufficiently powerful to webscrape it. We just need to change the ticker to get relevant data. Then we collect the news date meet the date requirements.
The key code snippet is attached below:
params['page'] = str(page)
# send a get request to the specified api url with the params dictionary and headers provided by Benzinga.
res = requests.get(url, params=params, headers=headers)
# use the xmltodict module to parse the XML content of the response into a dictionary.
xml_dict = xmltodict.parse(res.content)
# extract the item list from the result dictionary in the xml_dict
newslist = xml_dict['result']['item']
for news in newslist:
newstime = datetime.datetime.strptime(news['created'], \
'%a, %d %b %Y %H:%M:%S %z').date()
# find the data within our prespecified date range
if newstime < start_date | newstime > end_date:
date_bool=False
break
else:
pass
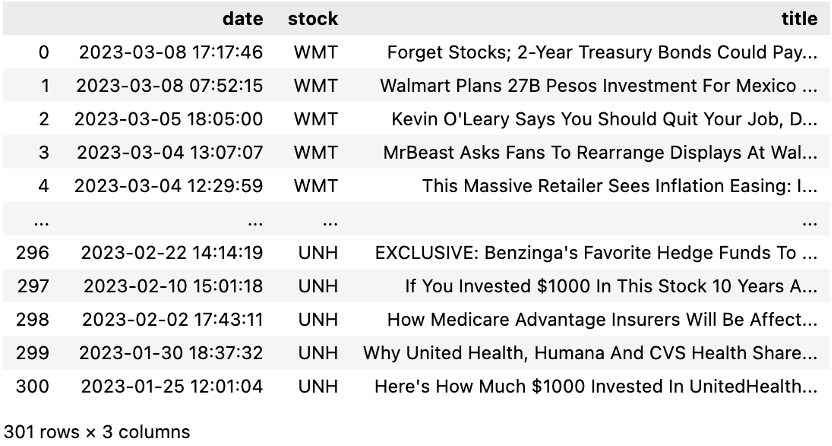
Here is an example output of the raw data we got from Benzinga.
2)Barron's
For data collection on Barron's, we use the package of selenium to minimic real human's operations such as clicking and inputing keywords. There are basically three steps.
Step 1. Search for the relevant data
We first send the precificied stock ticker to the website and click on the search button.
def getRelevant(self, name):
"""search relevant data"""
for _ in range(3):
try:
inputBox = self.driver.find_element(By.CLASS_NAME, \
'BarronsTheme--barrons-search-input--3dKl-YZJ')
inputBox.clear()
inputBox.send_keys(name)
break
except StaleElementReferenceException:
sleep(5)
# self.driver.refresh()
sleep(2)
action = ActionChains(self.driver)
action.move_by_offset(600, 100).click().perform()
Search = self.driver.find_element(By.CLASS_NAME, \
'BarronsTheme--search-submit--3CYhQXSw')
Search.click()
Step 2. Scrape data
The main problem we meet when scraping data is each time after we scrape 20 pages of data, the “404 error” will appear. This is actually a very common issue people may encounter when webscraping, and it is because we have opened this website too frequently. A typical solution is to let program sleep (stop operating) for 3 minutes when “404” appear.
while True:
try:
try:
contents = self.driver.find_elements(By.XPATH, '//article')
# waits 15 seconds and then refreshes the page if no result matching \
# the specified XPath expression '//article' is found.
if len(contents) == 0:
sleep(15)
self.driver.refresh()
continue
for info in contents:
content = {}
# title
content['title'] = info.find_element(By.XPATH, ".//h4").text
#print(content['title'])
# content
try:
content['content'] = info.find_element(By.CLASS_NAME, \
'BarronsTheme--summary--3UHA7uDx').text
except NoSuchElementException:
content['content'] = ''
# date
try:
content['date'] = info.find_element(By.CLASS_NAME, \
'BarronsTheme--timestamp--1QcAFHpF').text
except NoSuchElementException:
content['date'] = ''
self.content.append(content)
break
except StaleElementReferenceException:
sleep(1)
print('try to find element data')
except TimeoutException:
sleep(10)
self.driver.refresh()
print('Try reloading')
# wait 3 minutes when 404 error is returned
except:
sleep(180)
self.driver.refresh()
sleep(1)
Step 3. Turn to the next page
We try turning to next page three times. If we fail, it means this is the last page and this function will end.
try:
count = 0
# try three times
for _ in range(3):
count += 1
if count == 3:
break
# if still fails, this is already the last page
try:
page = self.wait.until(EC.element_to_be_clickable((By.LINK_TEXT, \
'NEXT PAGE')))
js = "window.scrollTo(0, document.body.scrollHeight)"
self.driver.execute_script(js)
self.driver.execute_script("arguments[0].click();", page)
break
except StaleElementReferenceException:
sleep(1)
print('try to find element click')
except TimeoutException:
sleep(5)
self.driver.refresh()
print('Try reloading')
except NoSuchElementException:
break
Here is an example output of the raw data we got from Barron.

3. Data mining on Twitter
The Twitter API is a set of programmatic tools that can be used to learn from and engage with the convention on Twitter.
The Tools and Libraries link on Twitter Developer Platform
3.1 tweepy: for accessesing the official Twitter API.
1) installation
The easiest way to install the latest version from PyPI is by using pip:
pip install tweepy
2) OAuth
Twitter requires all requests to use OAuth for authentication. The Document of Authentication
Tweepy supports the OAuth 1.0a User Context, OAuth 2.0 Bearer Token (App-Only), and OAuth 2.0 Authorization Code Flow with PKCE (User Context) authentication methods.
import tweepy
#initialize bearer token and
#initialize api by bearer instance
auth = tweepy.OAuth2BearerHandler("Bearer Token here")
api = tweepy.API(auth)
3) tweepy.API
class tweepy.API(auth=None, *, cache=None, host='api.twitter.com', parser=None, proxy=None, retry_count=0, retry_delay=0, retry_errors=None, timeout=60, upload_host='upload.twitter.com', user_agent=None, wait_on_rate_limit=False)
#instance
api = tweepy.API(auth)
| Parameters | Description |
|---|---|
| auth | The authentication handler to be used |
| cache | The cache to query if a GET method is used |
| host | The general REST API host server URL |
| parser | The Parser instance to use for parsing the response from Twitter; |
| defaults to an instance of ModelParser | |
| proxy | The full url to an HTTPS proxy to use for connecting to Twitter |
| timeout | The maximum amount of time to wait for a response from Twitter |
| upload_host | The URL of the upload server |
4) Twitter API Method
API.search_tweets
Returns a collection of relevant Tweets matching a specified query. Twitter’s standard search API only “searches against a sampling of recent Tweets published in the past 7 days.” If you’re specifying an ID range beyond the past 7 days or there are no results from the past 7 days, then no results will be returned.
| Twitter API v1.1 Endpoint | API Method |
|---|---|
| Search Tweets | |
| GET search/tweets | API.search_tweets() |
3.2 Snscrape: for accessing the unofficial API.
Snscrape is a prevalent webscraping tool which is widely used to scrape content from popular social media sites including Facebook, Instagram, and others in addition to Twitter. Snscrape does not require Twitter credentials (API key) to access it. There's also no limit to the number of tweets you can fetch. Although snscrape does not support some sophiscated queries related to the extra features and granularity provided exclusively by Tweepy such as geolocations, we find it is sufficiently poweful and faster than Tweepy to complete our task of data collection from Twitter.
1) Installation
pip3 install git+https://github.com/JustAnotherArchivist/snscrape.git
2) Tweets retrieve
Although it is commonly suggested that the most straightforward way to use snscrape is through its command-line interface (CLI) commands which is well documented, our group find Python Wrapper more intuitive to use. On a related note, we also find some resources with detailed instructions on how to use CLI with Python, which might be helpful for people who are not so comfortable with working directly in the terminal (like us) but still wish to make full use of the well developed CLI command documents.
To retrieve tweets for a specific user, we can do the following:
import snscrape.modules.twitter as sntwitter
import pandas as pd
# Created a list to append all tweet attributes(data)
attributes_container = []
# Using TwitterSearchScraper to scrape data and append tweets to list
for i,tweet in enumerate(sntwitter.TwitterSearchScraper('from:specified_username').get_items()):
if i>100:
break
attributes_container.append([tweet.date, tweet.likeCount, tweet.sourceLabel, tweet.content])
# Creating a dataframe from the tweets list above
tweets_df = pd.DataFrame(attributes_container, columns=["Date Created", "Number of Likes", "Source of Tweet", "Tweets"])