By Group 4
StockTwits is a social network for investors and traders to share ideas and commentary in real-time. In this task, we want to webscrape the comments for the top 100 stocks in the healthcare industry in the S&P 500 index in the past three months. Since the comments are dynamic, we use Selenium to webscrape the comments. This post shows the main code first and then address some issues that may arise when using Selenium to webscrape dynamic website.
Import libraries
import pandas as pd
import requests
import re
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import openpyxl
import multiprocessing
Get the list of symbols
symbol_data = pd.read_csv('D:\STUDY\hku fintech\M4 7036 Text Analytics and Natural Language Processing in Finance and Fintech\healthcare_top100.csv')
symbol_list = list(symbol_data['symbol'])
name_List = list(symbol_data['name'])
data_path='D:\STUDY\hku fintech\M4 7036 Text Analytics and Natural Language Processing in Finance and Fintech\data4.xlsx'
Write to Excel
We store the data in an excel file in the following format:
| Symbol | Time | Comment |
|---|---|---|
| A | 2021-11-30 23:59:59 | This is a comment |
We use openpyxl to write the data to an excel file.
def write_excel(path,value,list_title):
index=len(value)
workbook=openpyxl.load_workbook(path)
sheet=workbook['Sheet1']
for i in range(index):
sheet.append([list_title,value[i][0],value[i][1]])
workbook.save(path)
Main Process
The main process is to get the comments for each symbol. The url of the website is https://stocktwits.com/symbol/{symbol}, where {symbol} is the symbol of the stock. We use Selenium to webscrape the website. For each symbol, we get the time and the text of the comment. Then we store the data in a list and write the data to an excel file. Then we move to the next symbol until all the symbols are processed. If the time of the comment is later than the time we want, we stop the process. The code is shown below.
def process(symbol):
driver_path = r'D:\\STUDY\\selenium\\chromedriver.exe' # path to the chromedriver
option = webdriver.ChromeOptions() # create a ChromeOptions object
option.add_experimental_option("detach", True) # make the browser stay open
option.add_experimental_option('excludeSwitches', ['enable-logging']) # disable the warning
s = Service(driver_path) # create a Service object
browser = webdriver.Chrome(service=s,options=option) # create a Chrome object
browser.implicitly_wait(20)
index = 0
#for symbol in symbol_list[:3]:
url = f'https://stocktwits.com/symbol/{symbol}' # url of the website
browser.get(url)
time.sleep(1)
text_list = list()
a = 1 # count the number of comments retrieved in one page
i = 1 # count the number of comments retrieved in total
while True:
text1=list() # store the text of the comment
try: # find the time of the comment by XPATH
time_text = browser.find_element(By.XPATH,f'/html/body/div[2]/div/div[2]/div[2]/div[3]/div/div/div/div[3]/div/div/div[2]/div/div/div/div[6]/div[2]/div[1]/div/article[{i}]/div/div[1]/a/time').text
print(time_text)
except:
try: # if the element is not found, try the other possible XPATH
time_text = browser.find_element(By.XPATH,f'/html/body/div[2]/div/div[2]/div[2]/div[3]/div/div/div/div[3]/div/div/div[2]/div/div/div/div[6]/div[3]/div[1]/div/article[{i}]/div/div[1]/a/time').text
print(time_text)
except: # if the element is not found, print the index of the comment
print('time_text',i)
text1.append(time_text)
if time_text.startswith('Nov'): # if the comment is posted in November, stop the loop
print(i)
break
try: # find the text of the comment by XPATH
text = browser.find_element(By.XPATH,f'/html/body/div[2]/div/div[2]/div[2]/div[3]/div/div/div/div[3]/div/div/div[2]/div/div/div/div[6]/div[2]/div[1]/div/article[{i}]/div/div[3]/div[1]/div/div').text
text1.append(text)
text_list.append(text1)
except:
try: # if the element is not found, try the other possible XPATH
text = browser.find_element(By.XPATH,f'/html/body/div[2]/div/div[2]/div[2]/div[3]/div/div/div/div[3]/div/div/div[2]/div/div/div/div[6]/div[3]/div[1]/div/article[{i}]/div/div[3]/div[1]/div/div').text
text1.append(text)
text_list.append(text)
except: # if the element is not found, print the index of the comment
print('article',i)
i += 1
a += 1
if a == 15: # To load more comments, every 15 comments, scroll down the page
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(0.1)
a = 1
write_excel(data_path,text_list,symbol) # write the data to an excel file
browser.close() # close the browser
Main function and time cost of the program
We use multiprocessing to run the program in parallel to speed up the process. The code is shown below.
def main():
pool=multiprocessing.Pool(processes=5)
for item in ['MRNA']: #symbol_list:
pool.apply_async(process,(item,))
pool.close()
pool.join()
#print(text_list)
#dict_result[symbol_list[index]] = text_list
if __name__=='__main__': # run the program
start=time.time()
main()
end=time.time()
print(end-start)
Note for Selenium
Detach the browser and disable the warning
The browser will be closed automatically after the program is finished. To keep the browser open, we need to detach the browser. Also, warning messages will be displayed when the browser is detached. To make the result readable, we need to disable the warning.
option = webdriver.ChromeOptions() #create a ChromeOptions object
option.add_experimental_option("detach", True) # make the browser stay open
option.add_experimental_option('excludeSwitches', ['enable-logging']) # disable the warning
Dynamic loading
For dynamic website, the comments are loaded dynamically, which means that the comments are loaded when the page is scrolled down. Selenium provides a method to scroll down the page. The maximum number of comments that can be loaded in one page is around 20. We use a counter to count the number of comments retrieved in one page. When the counter reaches 15, we scroll down the page to load more comments. In this way, we can retrieve all the comments in the page.
if a == 15: # Scroll down the page to load more comments every 15 comments
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(1)
a = 1 # reset the counter
Prevent blocking
Some websites use anti-scraping techniques to prevent webscraping. For StockTwits, we need to add a delay between each request. Otherwise, the website will block our requests. We use browser.implicitly_wait() and time module to add a delay between each request.
browser.implicitly_wait(20) # wait for 20 seconds
or
time.sleep(1)
Find the element
In Selenium.By module, there are several ways to find the element. In this task, we find the element by XPATH. In the browser, we can right-click the element and select "Copy XPATH" to get the XPATH of the element.
We can use the following code to find the element.
time_text = browser.find_element(By.XPATH,f'/html/body/div[2]/div/div[2]/div[2]/div[3]/div/div/div/div[3]/div/div/div[2]/div/div/div/div[6]/div[2]/div[1]/div/article[{i}]/div/div[1]/a/time').text
In this task, the XPATH of the element is dynamic. Therefore, we use try-except to find the element by different XPATH. If the element is not found, we print the index of the comment.
text1=list() # store the text of the comment
try: # find the time of the comment by XPATH
time_text = browser.find_element(By.XPATH,f'/html/body/div[2]/div/div[2]/div[2]/div[3]/div/div/div/div[3]/div/div/div[2]/div/div/div/div[6]/div[2]/div[1]/div/article[{i}]/div/div[1]/a/time').text
except:
try: # if the element is not found, try the other possible XPATH
time_text = browser.find_element(By.XPATH,f'/html/body/div[2]/div/div[2]/div[2]/div[3]/div/div/div/div[3]/div/div/div[2]/div/div/div/div[6]/div[3]/div[1]/div/article[{i}]/div/div[1]/a/time').text
except: # if the element is not found, print the index of the comment
print('time_text',i)
text1.append(time_text)
Result
The head of the data is shown below.
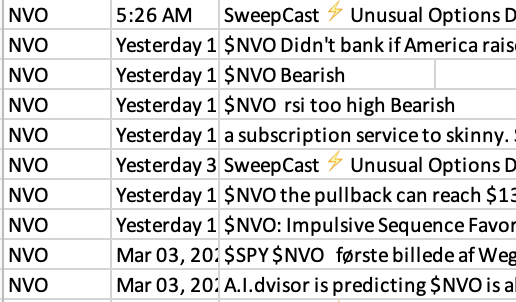
Conclusion
For dynamic website, several issues may arise when using Selenium to webscrape the website. The above code can be used to solve these problems.
The next step is to clean the data and do some analysis. Thanks for reading!