By Group 4
Sentiment Analysis is used to analyse the emotion of the text. In other words, it is the process of detecting a positive or negative emotion of a text. Scoring is an important part of our sentiment analysis model. This post will discuss in detail how sentiment scoring works in StockTwits by VADER.
What is VADER?
VADER (Valence Aware Dictionary and sEntiment Reasoner) is a lexicon and rule-based sentiment analysis tool that is specifically attuned to sentiments expressed in social media. It is used for sentiment analysis of text which has both the polarities i.e. positive/negative. VADER is used to quantify how much of positive or negative emotion the text has and also the intensity of emotion.
VADER is a dictionary that assigns a predetermined emotional score between -4 (most extreme negative) and 4 (most extreme positive) for each trait (which can be a word, acronym, or emoji). VADER is able to detect the intensity and polar aspects of emotion and combine it with powerful modifiers such as negation, contraction, conjunction, reinforcement, adverb of degree, capitalization, punctuation, and slang to calculate the score of the input text. VADER generates a composite score that summarizes the emotional intensity of the input text. By adding the scores of each feature in the dictionary, adjusting according to the rules, and normalizing between -1 (the most extreme negative) and +1 (the most extreme positive). The document describes the composite score as a "standardized weighted composite score". In addition, POS, NEG, NEU scores represent the proportion of text that belongs to each category
Let’s start analysing the sentiment using VADER.
First, install VADER by using the command line:
pip install vaderSentiment
then,
from nltk.sentiment.vader import SentimentIntensityAnalyzer
# Instantiate SIA class
analyser = SentimentIntensityAnalyzer()
sentiment_score = []
for twit in df['comment'].astype(str):
sentiment_score.append(analyser.polarity_scores(twit))
Here, SentimentIntensityAnalyzer() is an object and polarity_scores is a method which will give us scores of the following categories: * Positive * Negative * Neutral * Compound The compound score is the sum of positive, negative & neutral scores which is then normalized between -1(most extreme negative) and +1 (most extreme positive). The more Compound score closer to +1, the higher the positivity of the text.
#@title Extract Sentiment Score Elements
sentiment_prop_negative = []
sentiment_prop_positive = []
sentiment_prop_neutral = []
sentiment_score_compound = []
for item in sentiment_score:
sentiment_prop_negative.append(item['neg'])
sentiment_prop_positive.append(item['pos'])
sentiment_prop_neutral.append(item['neu'])
sentiment_score_compound.append(item['compound'])
# Append to twits DataFrame
df['sentiment_prop_negative'] = sentiment_prop_negative
df['sentiment_prop_positive'] = sentiment_prop_positive
df['sentiment_prop_neutral'] = sentiment_prop_neutral
df['sentiment_score_compound'] = sentiment_score_compound
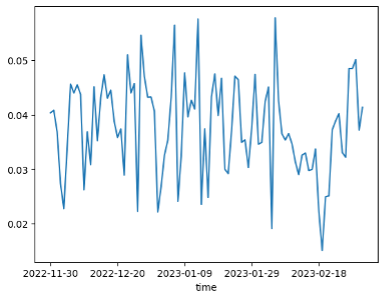
Negative Sentiment Score
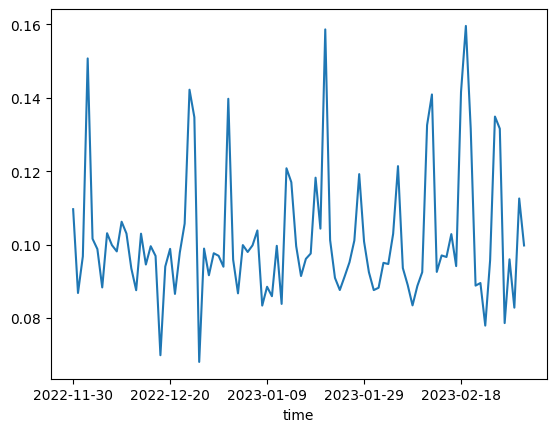
Positive Sentiment Score
Compound Sentiment Score
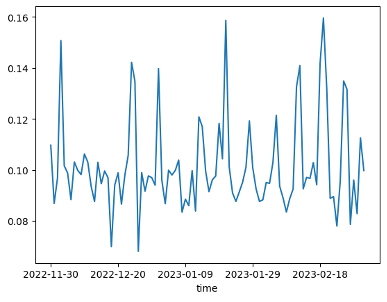
Data sentiment score: negative, positive, compound. After plotting the scores of the negative, positive, and composite scores for each component (we exclude the neutral score), we find that the sentiment score is very noisy and erratic, and the Stocktwits data may simply contain redundant information, some of which can cause the score to rise significantly. However, this is the essence of signal discovery-we only need one piece of significant information. The Stocktwits data seems to be more positive: the average negative score is 0.04, while the average positive score is 0.10.