By Group "Alpha Miner"
Sentiment analysis using textual data
In the world of natural language processing, we need to deal with a lot of digital textual data automatically to ascertain the exact mood from each of sentences or word chunks. Reading the text sentence by sentence is a laborious task. Individuals may not be able to fully recognise the correct emotional tone that the text aims to convey, depending on their knowledge, cultural background, motivation and reading speed.
Based on the knowledge we recently acquired from MFIN 7036 and the MFIN 7034 machine learning courses, we are more curious that if certain machine learning algorithms could predict the precise and accurate sentiment scores based on textual data. Supervised learning may also be helpful in resolving our current issue.
Supervised learning is the algorithm for solving problems when you are presented with a large amount of data with some features and corresponding labels. For instance, regarding the problem of detecting customer credit card defaults, we have the data describing each customer's age, family numbers, job occupation and etc., as well as whether they have defaulted or not. Supervised learning is used to try to find a black-box function mapping from the data features to the corresponding labels: in the example, it aims to find the hidden mapping from each credit card customer’s information to the default probability of each.
However, unlike the default detection from credit card customers’ basic information or housing price prediction based on house characteristics (like areas, number of rooms, material type, area safety score, etc.), in the case of sentiment analysis, the most crucial step is to find the important features that could be obtained from text and can be meaningful to predict the sentiment.
For example, the length of an English word may not be helpful to predict the sentiment. It is also important to consider a way to identify some features from the words, such as words beginning with ‘dis’ or ‘un’ which can reflect a negative mood, for example, unhappy, unsafe, unrealistic, disorder, discordant, and distress. We believe that the stem/root/base of a word may be a good feature notice, however, this needs a lot of clustering for each stem/root/base, to find the common features to predict the sentiment. In our opinions, the algorithm has to be trained from a huge dataset like an Oxford English dictionary, at the very least. Our group needs to consider the reasonability of the dataset, as the current progress for webscraping the Twitter data (even for some simple comments on social platforms) is slow.
Another factor that should be considered is the curse of dimensionality in the machine learning algorithms to predict the sentiment of words. For this, if there are too many features, it is more difficult for the algorithms to learn from the complexity of data and find the law for the data with a lot of useless information (such as word length). Furthermore, if there are very few features, it is equally difficult for the algorithm as it cannot, for example, find the common features of positive words.
Therefore, the important data feature is the baseline to build a model based on the machine learning algorithm. As aforementioned, this machine learning algorithm is attempting to find the black-box between the text feature and text sentiment. This begs the question: is there any package that has been trained numerous times that successfully finds the black-box function?
Useful tools for implementing sentiment analysis in python
Let’s move on the journey on the successful python packages built by others that may help in predicting sentiments, flair and afinn are useful packages worth introducing here.
Afinn
As regards the Afinn package, it is easy to install and implement, from which sentiment scores can be positive or negative integers.
Examples using the package are shown below:
from afinn import Afinn
afinn = Afinn()
afinn.score('Hi I love') # will return a score of 3.0
afinn.score('I am upset') # will return a score of -2.0
afinn.score('I am very excited about the great stock') # will return a score of 6.0
afinn.score('Great! It takes you three hours to figure out 1+1=2.') # will return a score of 3.0
flair
In terms of the flair package, it took three hours to install and implement on a laptop, which seemed from experience to be a fairly long installation time. It was hoped that this package would be much easier to use. The flair package was able to obtain the sentiment result of negative/positive and the corresponding probability.
The flair package was able to generate the sentiment result of negative/positive and the corresponding probability.
import flair
mod = flair.models.TextClassifier.load('en-sentiment')
s1 = flair.data.Sentence('You great')
s2 = flair.data.Sentence('You bad')
s3 = flair.data.Sentence('You hate')
s4 = flair.data.Sentence('You suck You good You hate')
s5 = flair.data.Sentence('Great! It takes you three hours to figure out 1+1=2.')
mod.predict(s1)
mod.predict(s2)
mod.predict(s3)
mod.predict(s4)
mod.predict(s5)
s1.labels[0].score, s1.labels[0].value
s2.labels[0].score, s2.labels[0].value
s3.labels[0].score, s3.labels[0].value
s4.labels[0].score, s4.labels[0].value
s5.labels[0].score, s5.labels[0].value

One limitation of the sentiment packages is that they are not sufficiently intelligent to analyse sarcasm correctly. This may bring some noise when it comes to analysing the sentiment of textual data.
To obtain a more precise sentence sentiment score, the regular expression package may be used first to pre-process the data. For instance, some useless information in the textual data that could affect the package predictability, such as url web links, ticker symbol of stocks (for instance, $AAPL), punctuation (like ,.:!?), extra spaces, uppercases (which could all be converted to lowercase).
Example code snippets are provided below:
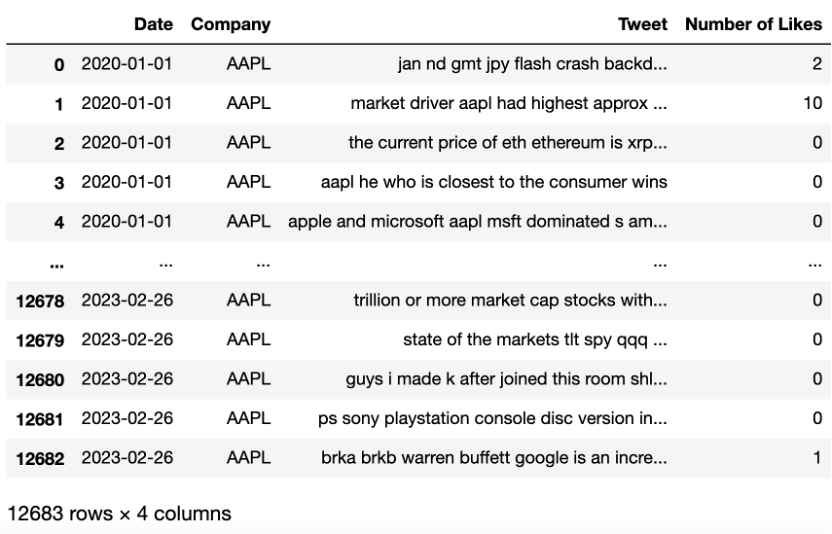
df = df[['Date','Company','Tweet','Number of Likes']]
df['Tweet'] = df['Tweet'].str.lower()
df
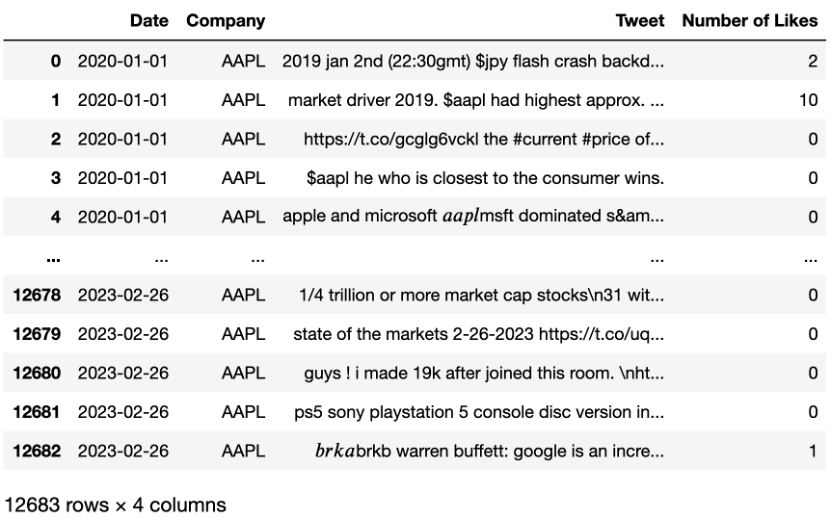
import re
tweet = []
for i in range(df.shape[0]):
t = re.sub(r"http\S+", "",df.iloc[i]['Tweet'])
t = re.sub(r"\s+"," ",t)
tweet.append(t)
df['Tweet'] = pd.Series(tweet)
df['Tweet'].replace("[^a-zA-Z]", " ", regex=True, inplace=True)
df