By Group "NLP Intelligence"
Background
Objective: Obtain all the Reddit posts relating to Chinese Concept Stocks in the U.S. during the period from June 2020 to June 2022 (to compare the change in sentiment before and after the Chinese company, DiDi’s, delisting event in the U.S.).
Conditions:
Each post must:
- Contain at least one of the keywords (stock names, stock tickers, relevant words)
- Posted within the period 1/6/2020 – 30/6/2022
Method 1: Web page scraping using Selenium
One method to scrape the data is to use the Selenium package with Webdriver. This method makes use of the HTML of the web page and extracts the content using the HTML code or path that corresponds to it.
First, we need to define the website URL for where the content is located. Then, we use the corresponding XPATHs to locate the piece of content we want to extract. This code gets us exactly what we see on the webpage:

The “Date” we extracted above is the difference between the posted date and current date, as that is what is shown on the web page for that post. What we want is the exact date for when the post was posted. If we hover the mouse over the time shown on the post, we can see the exact date of when the post was posted in a pop-up text box:
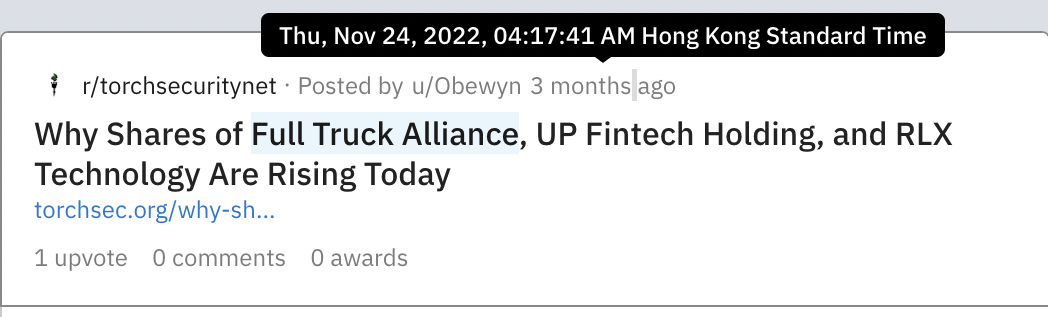
Inside the HTML of the webpage, there is no Selenium locator for the datetime value. The datetime is identified with data-testid, but Selenium does not support the data-testid method.

Hence, we looked for another way to extract the data.
Method 2: Using the Reddit API
Due to the datetime issue, we explored another method to scrape the posts and found that Reddit allow users to create applications that give users access to its API.
To get access to the Reddit API, we had to create an application in the App Preferences of the Reddit website. After successfully creating a new application, we were provided with a Client ID and Client Secret code that allows us the access to the Reddit API.
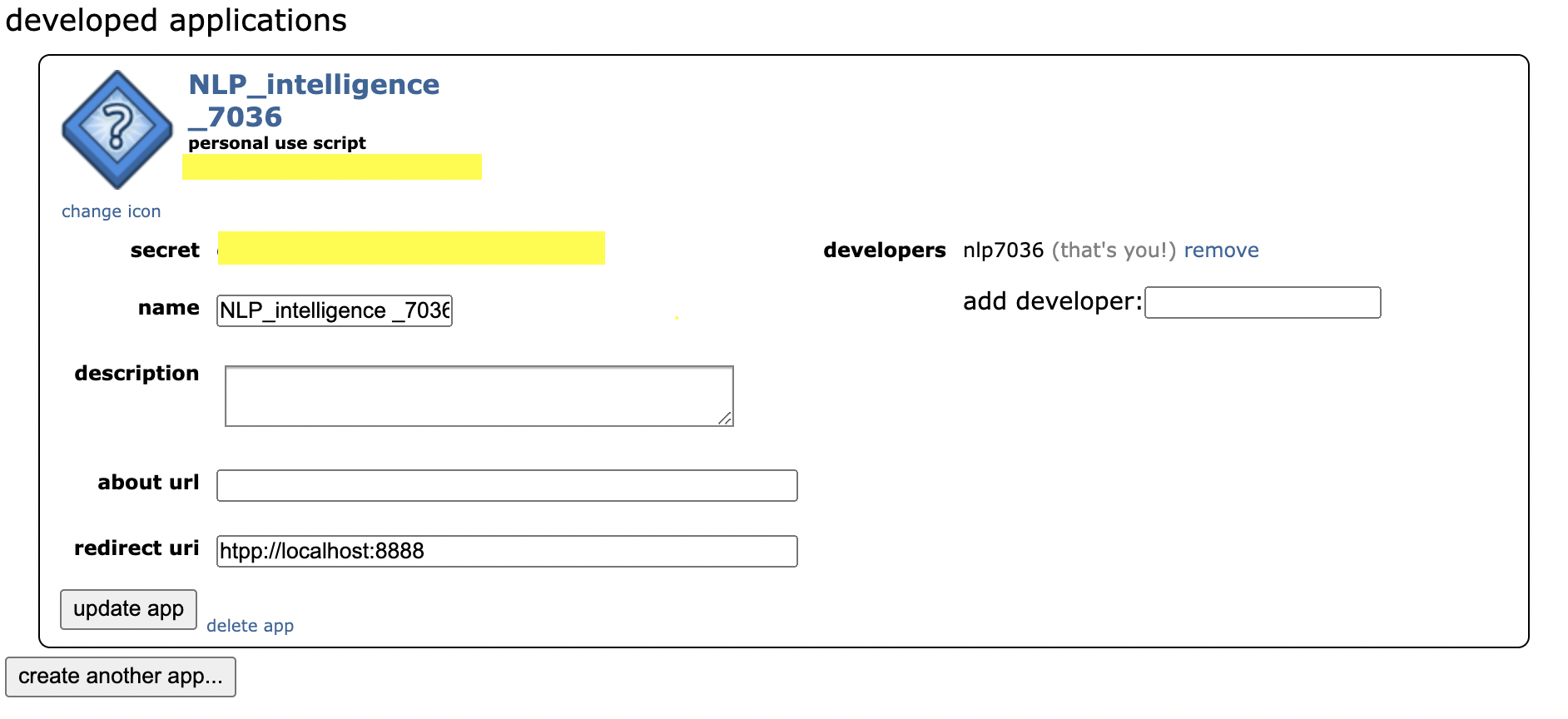
With the access keys to the API, we installed PRAW (Python Reddit API Wrapper), a python package that allows for easy use of the Reddit API. Using the PRAW package, we were able to collect all the posts we needed to a csv file for text processing.
Coding Troubleshoot
We identified 200+ keywords that need to be search on Reddit for relevant posts. The keywords are stored in a list, like the list ‘x’ for the code example shown below. Next, we wanted to create a loop, where each keyword will go into the search all subreddit function, then print the headline and date of the posts found. Hence, we proceeded to writing a while loop outside the for loop that prints the result of each post. The purpose of the while loop is to loop through the keywords, or list ‘x’ in the code example shown below. Essentially, the function of all.search(keyword), the keyword argument will be the items in list ‘x’. The code is shown below:
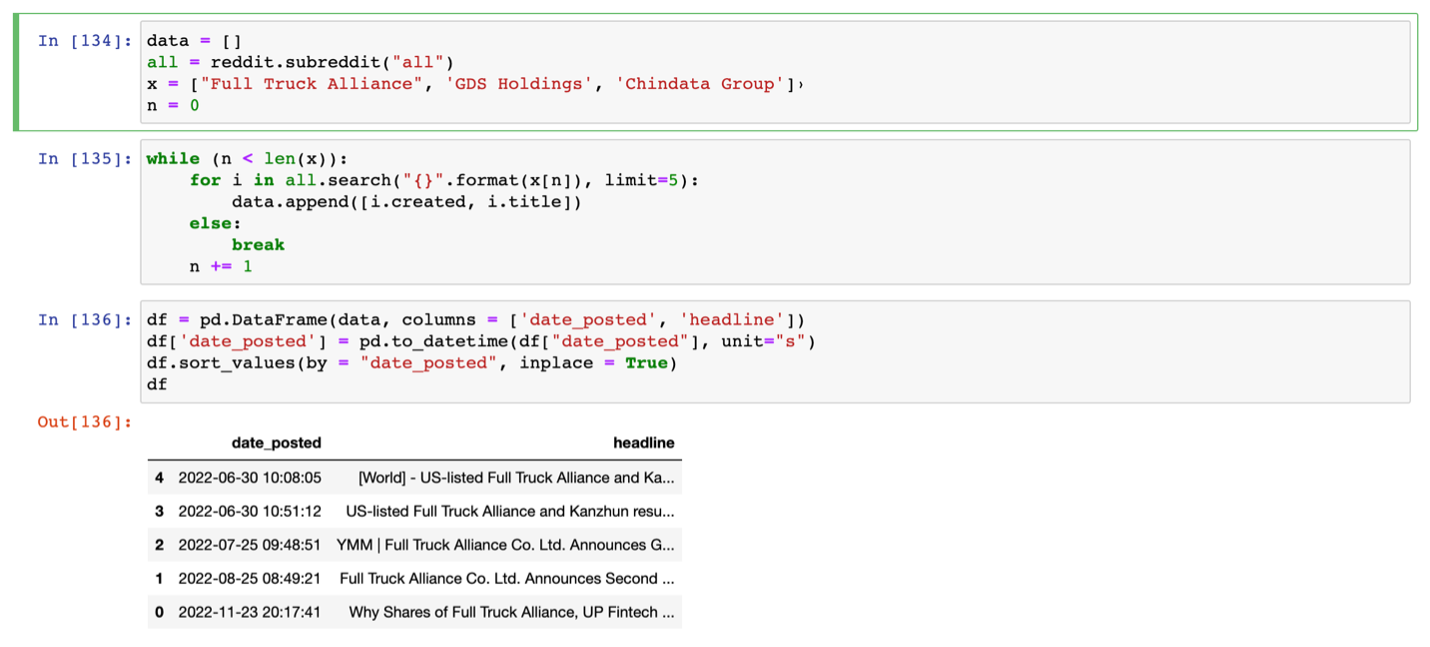
The output of this code showed that the while loop did not run through each of the items in list ‘x’ and output 5 posts from each keyword as we had expected. Instead, it only output the 5 posts from the first item of list ‘x’.
After some work trying to debug, we realized that our outer loop was the issue. Once we changed the while loop to another for loop, we were able to get the correct output. The correct code is shown below:
