By Group "NLP_0"
Introduction
Our group want to get product description and management's discussion of all the firms. We are going to use selenium to web-scrape them. The whole process contains three parts: 1. Get the urls 2. Web scraping and locate the part we need 3. Write text to local files
Get the urls
First, let's analyze the structure of 10-K files' urls. Take the 10-K file of Delanco Bancorp, Inc. in 2017 as an example: 'https://www.sec.gov/Archives/edgar/data/0001577603/000143774917011993/dlno20170331_10k.htm' We can easily find that urls are following the structure below: url = 'https://www.sec.gov/Archives/edgar/data/{cik No.}/{acc No.}/{doc name}.htm'
cik No. is the entity’s 10-digit Central Index Key (CIK), including leading zeros.
acc No. is accessionNumber, the unique number given to each new acquisition as it is entered in the sec database.
doc name is primaryDocument, the name of every file given by SEC.
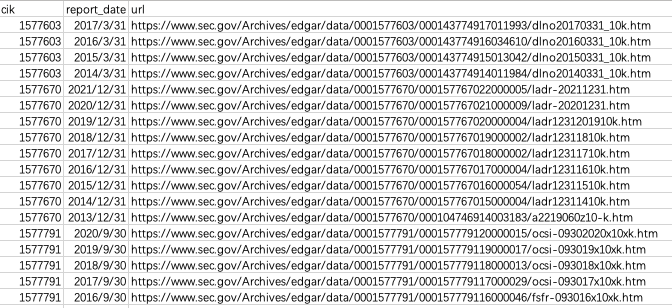
All these information required for urls can be looked up through API provided by SEC. We can also get the report date of each file through API. We now have access to the CIK number, Report date and document urls for every 10-K file, and save them in one csv file, with these three elements in three columns respectively.
Screenshot of csv:
Web scraping and locate the part we need
(1) Web scraping We decide to use selenium to get web content. It is very easy to conduct it once we have all the urls.
The code we use is as follows:
from selenium import webdriver
#from selenium.webdriver.support.wait import WebDriverWait
driver_path = r'/Users/./chromedriver'
browser = webdriver.Chrome(executable_path=driver_path)
browser.get(url) # 'url' is the url of the 10-K file you want
c=browser.find_element_by_xpath('/html/body') # get all the content in the web page
content=c.text # get the text form
(2) Locate the desired part It is relatively annoying when locating the content because these thousands of 10-K files are not always in a uniform format. We need the 'Item 1'(including Item 1A and 1B) and 'Item 7'(including Item 7A) parts. In the vast majority of cases, there will be a uniform format when it comes to this two parts, like subtitles with 'Item 1. Business', so that we can locate them easily. However, sometimes such subtitles are unique and misleading. For example, some firms may combine the 'Item 1' and 'Item 2' and the subtitle may be transformed as 'Item 1&2'. Under such circumstances, the original code may not locate these parts and even reports error. Thus, we decide to include all the exceptions so that we can get all the firms' files. Meanwhile, you should ensure that such modification will not disturb the original function, like you may want to include all the subtitles start with 'item 1', but you may actually locate the 'item 14'.
The code we use is as follows:
browser.get(u2[t])
c=browser.find_element_by_xpath('/html/body')
content=c.text
lst=content.split('\n')
#initialize
fr=0
start1=0
start2=0
end1=0
end2=0
l=len(lst)
#remove 'Table of Contents' in every page
for i in range(l):
a=lst[i].strip().lower().replace(' ','')
if a=='tableofcontents':
lst[i]=''
#locate 'item14' in catalog
for i in range(l):
a=lst[i].lower().replace(' ','')
if a.startswith('item14'):
fr=i
break
#sometimes 'item14' cannot be found
if fr==0 or fr>700:
print('no_found_from:',t)
fr=100
#locate 'item1'
start1=fr
for i in range(fr+1,l):
a=lst[i].lower().replace(' ','')
if a.startswith('item1.') \
or a.startswith('item1and') \
or a.startswith('items1and') \
or a.startswith('items1&') \
or a.startswith('itemi.') \
or a.startswith('item1–b') \
or a.startswith('item1bu') \
or a=='item1':
start1=i
break
# locate 'item2'
end1=start1
for i in range(start1+1,l):
a=lst[i].lower().replace(' ','')
if a.startswith('item2.') \
or a.startswith('item3.') \
or a.startswith('item2p') \
or a.startswith('item2–p') \
or a.startswith('item2-p') \
or a=='item2':
end1=i
break
#extract contents between item1 and item2
bis='\n'.join(lst[start1:end1])
#locate 'item7'
start2=end1
for i in range(end1+1,l):
a=lst[i].lower().replace(' ','')
if a.startswith('item7.') \
or a.startswith('item7m') \
or a.startswith('item7–m') \
or a.startswith('item7-m') \
or a=='item7':
start2=i
break
#locate 'item8'
end2=start2
for i in range(start2+1,l):
a=lst[i].lower().replace(' ','')
if a.startswith('item8.') \
or a.startswith('item8f') \
or a.startswith('item8–f') \
or a.startswith('item8-f') \
or a=='item8':
end2=i
break
#extract contents between item7 and item8
comp='\n'.join(lst[start2:end2])
Write text to local files
We create files for every firm named as their CIK number, and the acquired content is also stored in a separate txt file and saved under the corresponding company file.
Screenshot of file: