By Group "Alpha Seeker"
Why Topic Modeling?
In predicting the market with news data, many people would tend to calculate the sentiment score, such as the subjectivity score, of each document to construct a time series index for prediction. However, an important question is: what does it mean if the subjectivity score is high?
In fact, even within the same broad category, different news articles with high sentiment score can imply drastically different information. For example, Article A reported a new-found oil field and Article B reported the environmental harms of fossil fuels. If both of the articles have high sentiment scores, Article A could mean that people were happy about finding a new source of oil and Article B could mean that people were celebrating the success of reducing the fossil fuel usage. While both of the articles have high sentiment, they might signal market movements in different directions. Therefore, it is necessary to understand different topics within a news dataset first.
Latent Derelichet Allocation
Latent Derelichet Allocation (LDA) is a Bayesian probabilistic unsupervised learning model which can estimate the probability distribution of a document belonging to different topics and the probability distribution of a word belonging to different topics, given predefined number of topics. The performance of the model can be evaluated by subjective human judgement and the perplexity score. Here we mainly fine-tuned the model through subjective evaluations.
For a given document, LDA model gives the probability distribution of the document belonging to each topic:
The input of the LDA model is word vectors based on each document. Here we try two different ways of forming word vectors: Bag of Words and TF-IDF. While Bag of Words model simply counts the words, TF-IDF is a weighting model that gives more weight to words that show up frequently but only in a few documents.
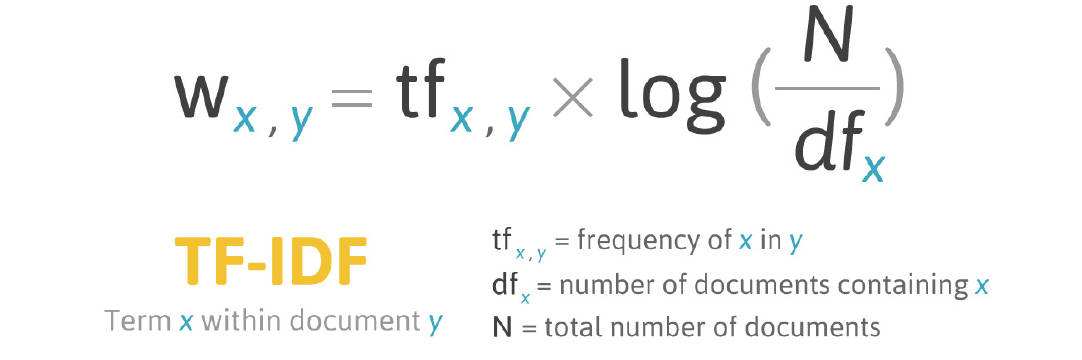
Implement LDA model
1. Load News Data
The news data here are all the historical articles from The Guardian from 2010-2022. After scraping the news from the website, we filtered out energy related news using a word2vec model. Specifically we picked news related to some keyword.
Here, we merged the title and text of the data and formed a series whereas each row represents one article. As we have discussed, this simple filter is not enough to filter the themes of articles, which is why we need LDA.
2. Vectorize Data with [Sklean] Package:
Here, we implement both the BoW and TFIDF vectorizer. We uses 2-gram for both model, which is to include 2-word phrases in the word vectors.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
#term counts with BoW model
sources = [f"post{i}" for i in range(len(newdata))]
cv = CountVectorizer(stop_words = 'english', min_df = 0.05, ngram_range = (1,2))
corpus_cv = cv.fit_transform(newdata)
feats = cv.get_feature_names()
corpus_array = corpus_cv.toarray()
df = pd.DataFrame(corpus_array, columns = feats, index = sources)
# tf-idf counts
tfidf = TfidfVectorizer(stop_words = 'english', min_df = 0.05, ngram_range = (1,2))
corpus_tfidf = tfidf.fit_transform(newdata)
feats_tfidf = tfidf.get_feature_names()
corpus_array_tfidf = corpus_tfidf.toarray()
df_tfidf = pd.DataFrame(corpus_array_tfidf, columns = feats_tfidf, index = sources)
3. Construct the LDA Model
Here we picke the number of topics to be 10, and the maximum number of iterations to be 100.
from sklearn.decomposition import LatentDirichletAllocation
# Perform LDA
lda = LatentDirichletAllocation(n_components = 10, max_iter = 100, learning_method = 'online', batch_size=700,
learning_offset = 50.,n_jobs=6,
random_state = 2)
lda.fit(corpus_cv)
4. Plot the topics:
# define top words plotting function for topic modeling
def plot_top_words(model, feature_names, n_top_words, title):
fig, axes = plt.subplots(2,5, figsize=(30, 15), sharex=True)
axes = axes.flatten()
for topic_idx, topic in enumerate(model.components_):
top_features_ind = topic.argsort()[:-n_top_words - 1:-1]
top_features = [feature_names[i] for i in top_features_ind]
weights = topic[top_features_ind]
ax = axes[topic_idx]
ax.barh(top_features, weights, height=0.7)
ax.set_title(f'Topic {topic_idx + 1}',
fontdict={'fontsize':30})
ax.invert_yaxis()
ax.tick_params(axis='both', which='major', labelsize=20)
for i in 'top right left'.split():
ax.spines[i].set_visible(False)
fig.suptitle(title, fontsize=40)
plt.subplots_adjust(top=0.9, bottom=0.05, wspace=0.90, hspace=0.3)
plt.show()
#plotting
feature_names = cv.get_feature_names()
plot_top_words(lda, feats, 10, 'Topics in LDA model')
Results
Here, we present the topics generated by LDA with TF-IDF and BoW:
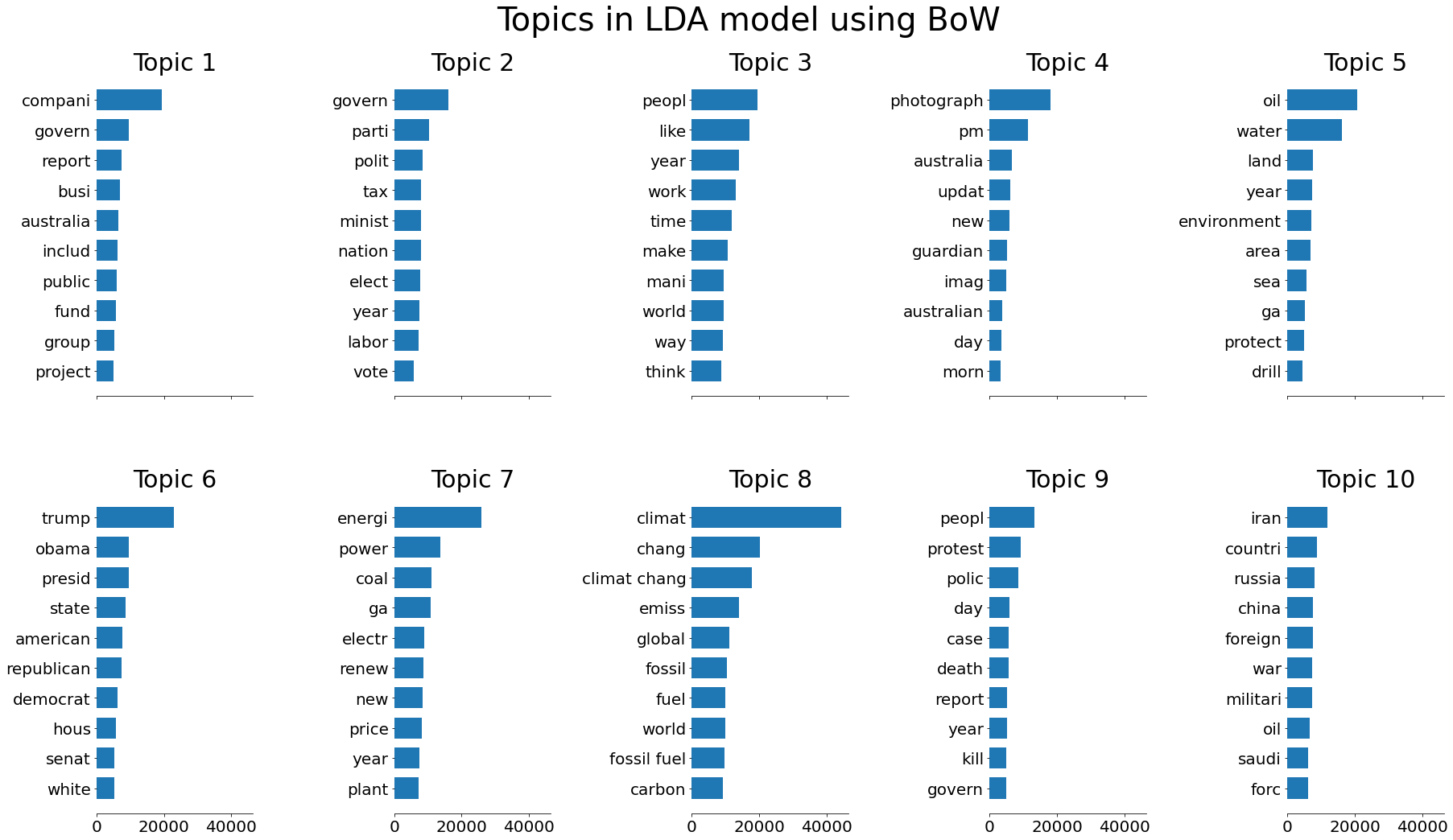
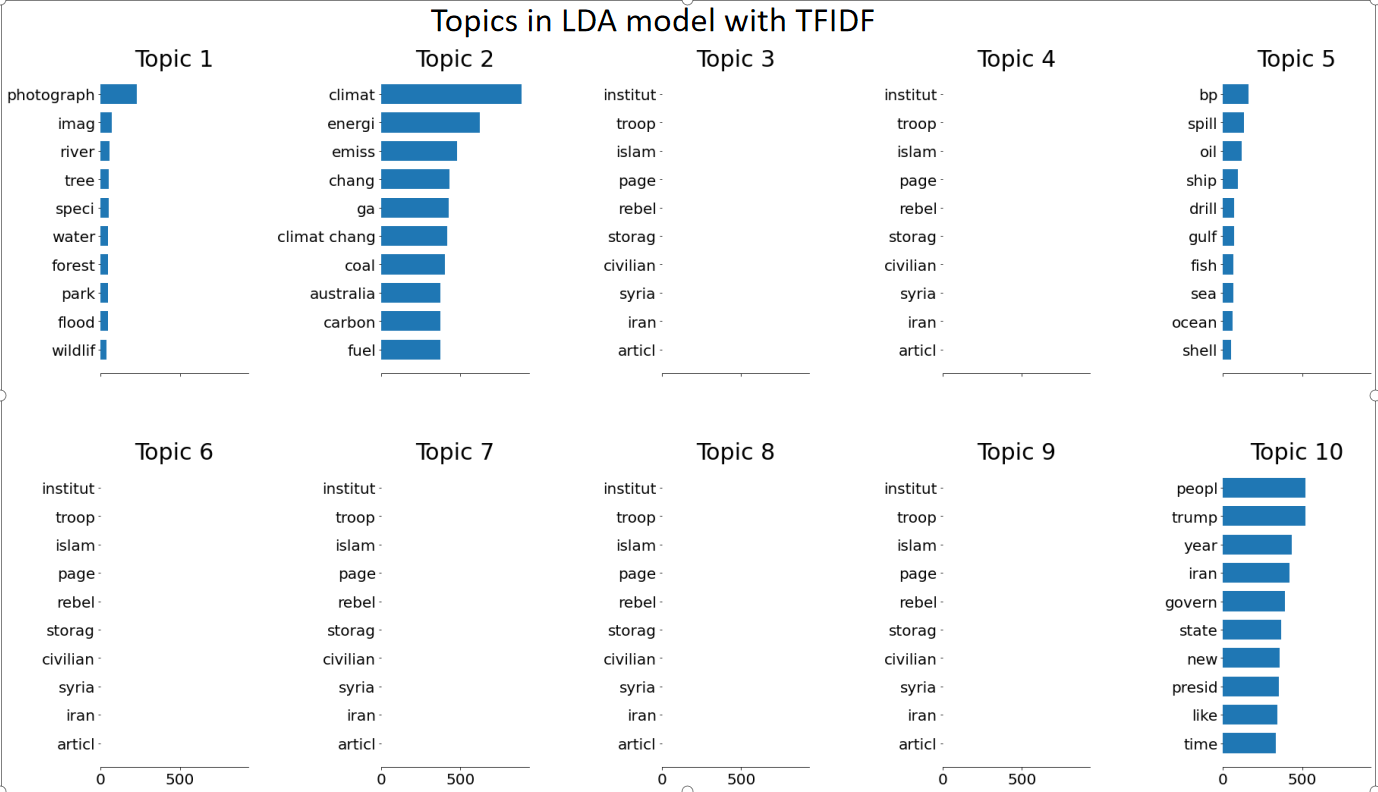
It is obvious that the TFIDF version works poorly. This might be due to the fact that the Derelichet distribution in LDA is based on the counts of words.
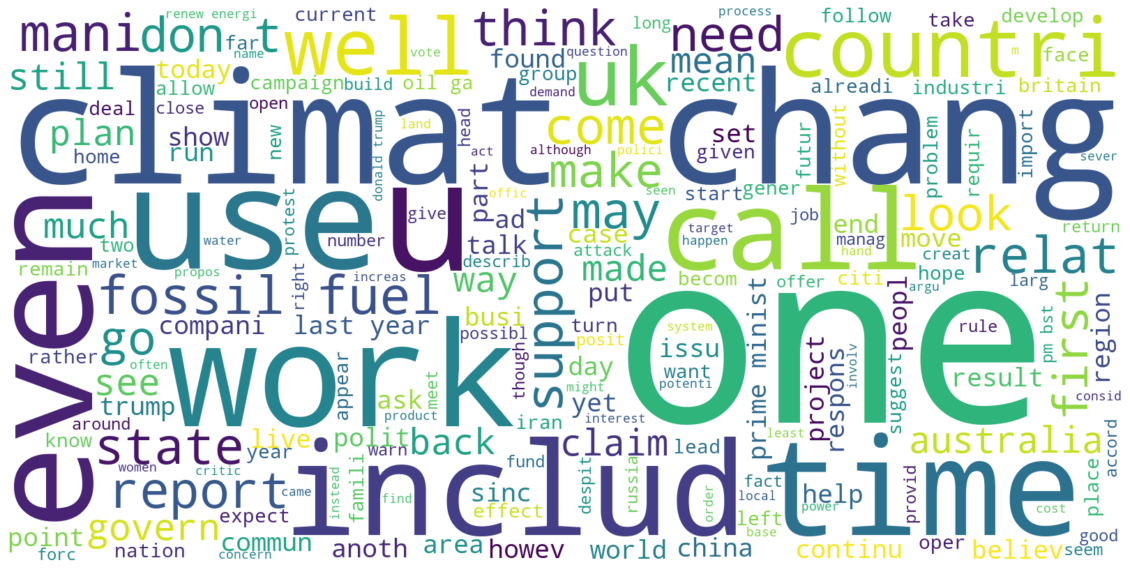
Then we can conclude that BoW is the appropriate word vector model that fits well in the LDA model. To examine if the LDA model can actually decompose topics from our original Guardian news dataset, we made word clouds to compare.
Firstly, we generate the word cloud of the entire news dataset:
Then, we generate the word cloud of Topic 10 after using LDA model:
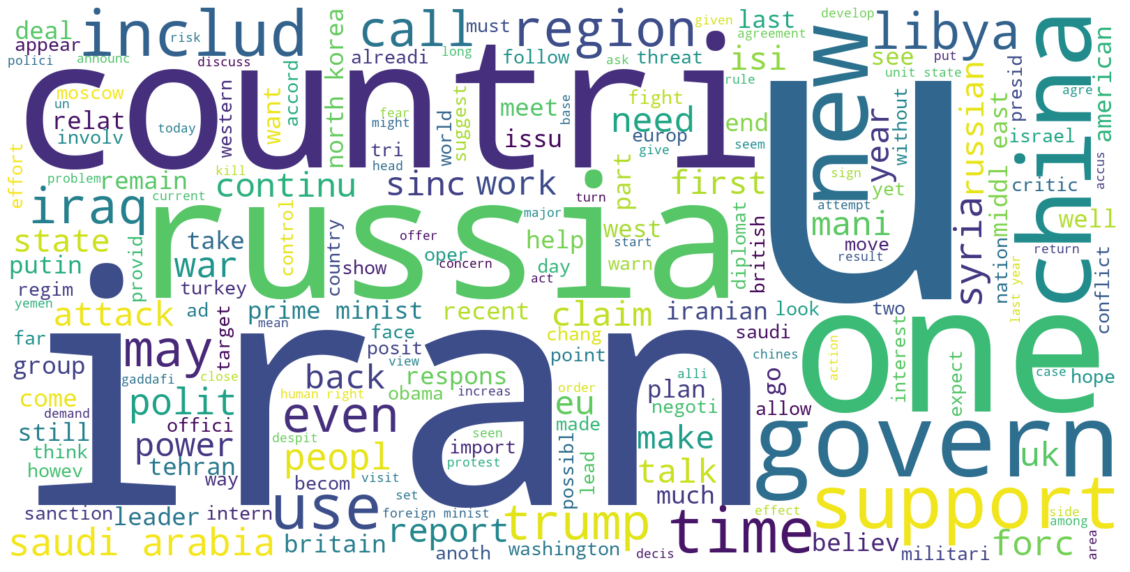
Clearly we can see that the countries popular in geopolitical discussions such as Iran, Russia, China, and Libya can be easily found on the second word cloud. There is significant consistency among the words on the cloud. On the contrary, the first word cloud has not particular theme. Therefore, we conclude that LDA truly works in decomposing news into different topics.
Conclusion
In this blog, we have shown that, by using LDA model, one can cluster news articles into different groups with specific topics. The consistency within groups would make it easier for people to interpret the meaning of features such as sentiment scores of the news articles. Additionally, this can help improving the predicting power of the indexs generated from news data in terms of trading strategies.
We are aware of the fact that we used all the news data in training the LDA model. If we are to construct a trading strategy based on this topic assignment, we would be using future data. Therefore, in further analysis, we suggest training the LDA model with a training dataset and using the trained model to assign topics to a testing dataset.