By Group "Supernatural"
In this blog, we do the text processing for readability and simplicity for all the tweets we collect and conduct analysis and regression on financial data.
Text processing and sentiment analysis
Firstly, the object of tweets collected is dtype. When they are saved as string, the text would start with b’, so it should be removed.
Besides it, there are a lot of useless information for analysis, such as users’ names and hyperlinks, we also removed them. Secondly, a problem encountered is the error code generated during encoding, and these codes are Unicode (like \x9e), which should be transformed into ASCII to read.
For the punctuations’ Unicode, we turn them into ASCII by the conversion table, but for the other Unicode like emoji, etc.., they are removed because of less information.
The code we use is as follows:
# remove all the hyperlinks in the tweets
def remove_link(text):
cleaned_text = re.sub(r"(http\|http?\://|https?\://|www)\S+", "", text)
cleaned_text = " ".join(cleaned_text.split())
return cleaned_text
data['Text'] = data['Text'].apply(lambda x: remove_link(x))
# remove all the emojis and other symbols like the form '\xce' etc.
def remove_emoji(text):
cleaned_text = re.sub(r'(\\x[A-Fa-f0-9]{2})+', " ", text)
cleaned_text = " ".join(cleaned_text.split())
return cleaned_text
data['Text'] = data['Text'].apply(lambda x: remove_emoji(x))
Take a random tweet as an example, the comparison between original tweet and processed tweet is shown below:
Original tweet:
b'A $750k settlement for Rio Tinto Ltd who just announced a profit of $29.2billion. Geez ASIC - you got them shaking in their boots \xf0\x9f\xa4\xa6\xe2\x80\x8d\xe2\x99\x80\xef\xb8\x8f https://t.co/DLcPNV5Glt'
processed tweet:
A $750k settlement for Rio Tinto Ltd who just announced a profit of $29.2billion. Geez ASIC - you got them shaking in their boots
After Text processing, given the cleaned text, we use the module ‘TextBlob’ to analyze tweets’ sentiment, and obtain the subjectivity and polarity of tweet.
The results are divided into different groups by date. And we calculate the mean of all the groups’ sentiment score, and it would show the public opinion on Twitter to the company Rio Tinto during one day.
Finally, what we do is analyzing words in tweets, and we decide to use BoW to get token frequencies, like what we learn in the lecture. And we introduce the module ‘WordCloud’ to virtualize the most frequent words. The figure is shown below:
Analysis and regression on financial data
We first run regressions between return and polarity but there shows no clear pattern. It is understandable that comments from twitter are just a minor affect on the stock price and what matters are those economic factors.
The classic Fama-French model then came into our mind and we then adjust our project goal to identify if the combination of sentiment analysis would promote the performance of Fama-French 3 Factor Model.
To conduct regression on FF 3 Factor model, some other data need to be collected:
The first is market return and we use Total market of index of Industrial Industry to represent it since Rio Tinto is an ore miner.
SMB is calculated as aggregate small companies’ market return less aggregate large companies’ market return. We collect historical data including SmallCap 600 and S&P500 Industrial as representation of the two data.
For HML, there’s no clear index specific to this area, so 5 low book-to-market ratio companies and 5 high companies are selected manually to calculate HML for each day. This could be a limitation and is clearly shown in later regression analysis.
The regression results of models with and without the two sentiment scores are shown below.
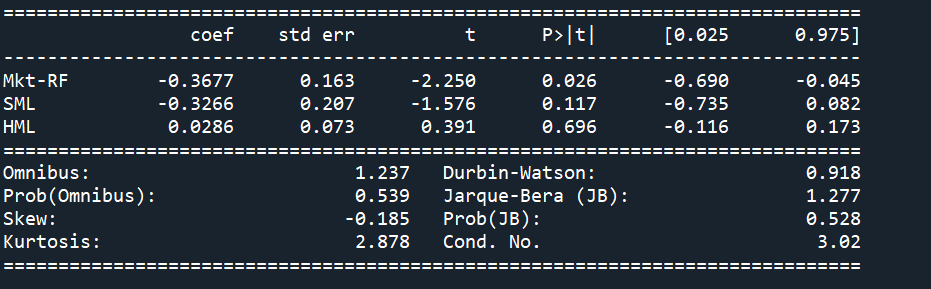
Fama - Frenach 3 – Factor Model:
Fama - French 3 - Factor + ( Polarity + Subjectivity ) Model:
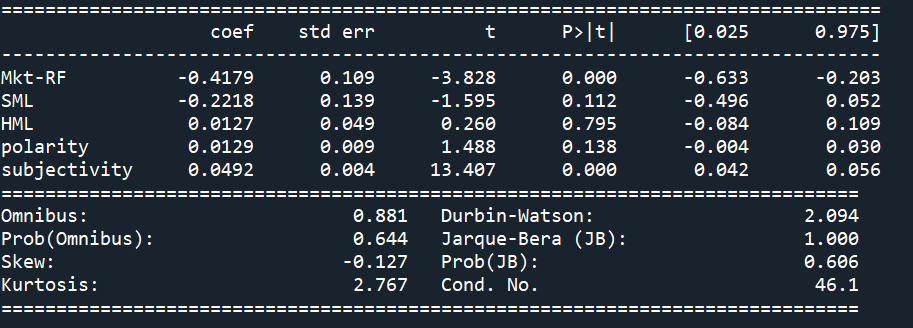
The OLS summary shows that both polarity and subjectivity are significant given the absolute values of their t-value is large enough. Also from the summary, the HML is moderately insignificant which may due to the defects of our data selection.
The data was split into train and test by 80% to 20% and the out of sample MSE for the two models are around 0.0004736 and 0.0002455 respectively, so we are confident to conclude that the sentiment analysis scores do help improve the performance of Fama-French 3 Factor Model.