By Group "DeepDiver"
This is part of a whole Program, I skipped the web crawling, Data Cleaning, Word frequency statistics. After those I skipped, I have a certain understanding of the collected text data, but I still want to know what product attributes users rate the products and the pros & cons of Oral-B from the user reviews, and this requires us to perform a quantitative analysis.
Original data structure
This is a data file crawled by a web crawler with some data cleaning. I name it as "df" in the code. The columns are shown as below:
IN[1]:df.columns
Out[1]: Index(['Unnamed: 0', 'title', 'rating', 'content', 'sentence_length'], dtype='object')
A Closer look at the review
Let's first take a closer look at the whole review. Here are three examples of the 1 rating review and 5 rating review: Here is a 1-star rating review:
Review#1: "This toothbrush is used ONCE daily by only ONE person. I've only had it about 2-1/2 months and it no longer holds a charge. Despite charging it daily, it doesn't even stay charged long enough to get thru the full two-minute brushing cycle. It used to only require being charged about every one-two weeks, but now I must charge it daily. When I tried to get customer support, I was told it's past warranty and nothing will be done. I've always used Phillips Sonic toothbrushes and have never had a problem. I thought I'd try Oral-B, but I won't again."
The customer complained about the charge of Oral-B and metion the Phillips he used to use. Because of the Oral-B poor performance on charging, this customer gave a 1-star rating at last.
Here are two 5-star rating reviews:
Review#2: "This is an improvement over the very good earlier model. It really gives a great cleaning and takes up very little room on the bathroom sink counter. I see there is a spot to rate the timer function, but I actually haven't seen it function. I am brushing about 1 1/2 minutes and that might be the problem. I believe they recommended 2 minutes. I find removing the tooth brush from the wand a little hard. My husband and I both use that same unit, but switch toothbrushes, of course, and this is my only real complaint about this system."
Review#3: "Got this for my husband he loves it!"
In Review#2, this customer mentioned that Oral-b has a great cleaning effect and the timer function is also very nice to use, therefore, he (she) gave a 5-star rating.
Compared Review#1 with Review#2, I made an assumption that different customers give their rating according to some special attributes of the Oral-B electric toothbrush such as charge, battery, cleaning effect, or the brand itself.
Another assumption will be, if a customer buys something good and is going to write a review, he may just say something like "I like it, just buy it", which is short and compact, just like Review#3. However, if he does not like this good, and he (she) still wants to write a review, in most cases, he (she) will complain a lot about what's wrong with this product. So the length of the low-rating review is longer than that of the high-rating review. Now, we have a preliminary idea of the variables.
Why do I use logistic regression?
Before answering this question, let's consider what is the difference between a 1-star rating and a 2-star rating review?
Humans are very subjective animals, and even for the same reasons, some will rate a 1-star, others may give a 2-star rating. It is hard to explain what leads to the difference between a rating of 1 and a rating of 2 reviews. The reason for the difference may not be due to the product itself, but due to the customers. But if I use positive and negative reviews as variables, these reviews will be easy to distinguish and all the positive or negative reviews that customers gave are based on the product itself, without subjective factors, which makes the quantitative analysis more economic sense.
Only two dependent variables? Then it is the logistic regression's show time.
How do I set up the variables and dependent variables?
There are many attributes of the electric toothbrush. According to the word frequency and the content of the reviews, I summarized that customers mainly through the following 12 angles to discuss oral-b this product: battery, price, function, noise, power, charging, quality, design, brand, logistics, effect, and user experience. Based on the 12 attributes, the corresponding relevant words (could be ADJ or NOUN) are then manually filtered, and the same word describing multiple attributes is avoided as much as possible, thus reducing the correlation between different variables. 12 Dummy variables are set depending on whether these terms appear in the comments or not.
def dummy_generation(review):
battery_word=['battery','lithium','batteries']
price_word=['price','expensive','cheap','cheaply','money', 'inexpensive','budget','costly']
function_word=['function','functionality','mode','timing','timer','charging light']
sound_word=['sound','loud','louder','squeaky','noise','noisy']
power_word=['power','vibration','rotate','oscillation','powered','spinning']
charge_word=['charger','charge','recharge','recharging', 'rechargeable','volt']
quality_word=['quality','waterproof']
design_word=['design','pretty','color','style','compact','size','looking','heavy','lightweight','weight']
brand_word=['brand','phillip','sonic','sonicare','soniccare','philip' ,'oralb']
dilivery_word=['deliver','delivery','shipping','ship']
effect_word=['clear','cleaner','cleanliness','effective', 'effect']
user_experience_word = ['feel','feels','felt', 'soft','rough','comfortable','uncomfortable','harsh']
if True in list(map(lambda x:x in review ,battery_word)):
battery=1
else:
battery=0
if True in list(map(lambda x:x in review ,price_word)):
price=1
else:
price=0
if True in list(map(lambda x:x in review ,function_word)):
function=1
else:
function=0
if True in list(map(lambda x:x in review ,sound_word)):
sound=1
else:
sound=0
if True in list(map(lambda x:x in review ,power_word)):
power=1
else:
power=0
if True in list(map(lambda x:x in review ,charge_word)):
charge=1
else:
charge=0
if True in list(map(lambda x:x in review ,quality_word)):
quality=1
else:
quality=0
if True in list(map(lambda x:x in review ,design_word)):
design=1
else:
design=0
if True in list(map(lambda x:x in review ,brand_word)):
brand=1
else:
brand=0
if True in list(map(lambda x:x in review ,dilivery_word)):
delivery=1
else:
delivery=0
if True in list(map(lambda x:x in review ,effect_word)):
effect=1
else:
effect=0
if True in list(map(lambda x:x in review ,user_experience_word)):
user_experience=1
else:
user_experience=0
return battery,price,function,sound,power,charge,quality,design,brand,delivery,effect,user_experience
In previous NLP and data cleaning, I already obtained the length of each review, and the code will not be shown here.
For the dependent variables, I took 1-to-3-star rating review as negative review (0) and 4-to-5-star rating review as positive review (1).
import pandas as pd
import numpy as np
import os,spacy,re
from tqdm import tqdm
from collections import defaultdict
from spacy.lang.en.stop_words import STOP_WORDS
from sklearn.linear_model import LogisticRegression
import statsmodels.api as sm
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
from sklearn import preprocessing
nlp=spacy.load("en_core_web_sm")
# Generate dependent variables
for rating in df['rating']:
if rating == 4 or rating == 5:
rating_list.append(1)
elif rating == 3:
rating_list.append(0)
elif rating == 1 or rating == 2:
rating_list.append(0)
# Generate variables
for review in tqdm(df['content']):
review=word_replace(review)
text = nlp(review)
#select token
token_list = []
for token in text:
token_list.append(token.lemma_)
filtered =[]
for word in token_list:
lexeme = nlp.vocab[word]
if lexeme.is_stop == False and lexeme.is_punct == False:
filtered.append(word)
filtered = [re.sub(r"[^A-Za-z@]", "", word) for word in filtered]
filtered = [word for word in filtered if word!='']
dummy_tuple=dummy_generation(filtered)
for wordlist,dummy in zip([battery,price,function,sound,power,charge,quality,design,brand,delivery,effect,user_experience],dummy_tuple):
wordlist.append(dummy)
#Add dummy variables into df
df['rating']=rating_list
df['battery']=battery
df['price']=price
df['function']=function
df['sound']=sound
df['power']=power
df['charge']=charge
df['quality']=quality
df['design']=design
df['brand']=brand
df['delivery']=delivery
df['effect']=effect
df['user_experience'] = user_experience
# Standarlize the length of review
df['std_length']=preprocessing.scale(df['sentence_length'])
After all these, all the preparation of logistic regression is done.
Logistic Regression
Run the regression code shown below:
pools=['battery',
'price',
'function',
'sound',
'power',
'charge',
'quality',
'design',
'brand',
'delivery',
'effect',
'user_experience',
'std_length']
X=df[pools]
y=df['rating']
LR = LogisticRegression(penalty="l1",solver= 'liblinear',class_weight='balanced',tol=0.008,max_iter=100000)
lr_model=LR.fit(X,y)
lr_model1 = sm.Logit(y,sm.add_constant(X)).fit() #used to look summary
print(lr_model1.summary())
predicted_prob = lr_model.predict_proba(X)
predicted_default_prob= predicted_prob[:,1]
fpr, tpr, _ = roc_curve(y, predicted_default_prob)
roc_auc = auc(fpr, tpr)
print('Variables: ', list(X.columns))
print('No. of Variables: ' , len(X.columns))
print('the AUC Value: ' , roc_auc)
Output:
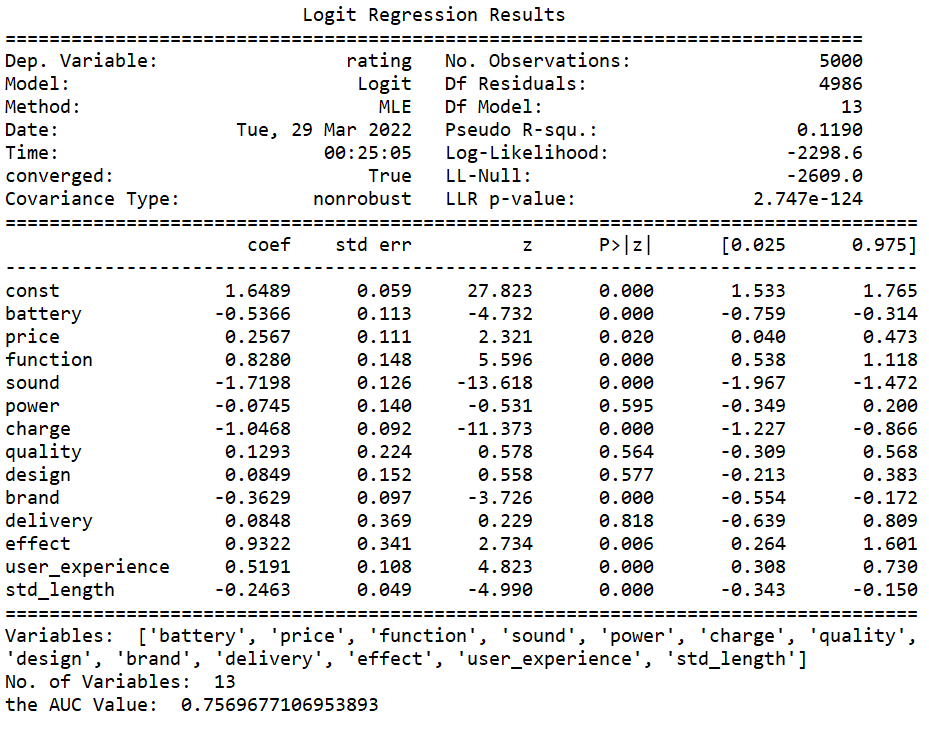
The variables battery, price, function, charge, brand, effect, user experience, and review length are significant under the 95% confidence level. So I concluded that these 7 variables (except the review length) are the most important factors for customers to consider when scoring the product. As for the variables power, quality, design, and delivery, they are not significant in this model, and the reason could be that customers have different perceptions of these product attributes, or they do not make a clear evaluation of the product based on these attributes. One more reason is that I did not find the suitable related words in my previous work.
Delete the non-significant variables and run the regression again, the result is shown below:
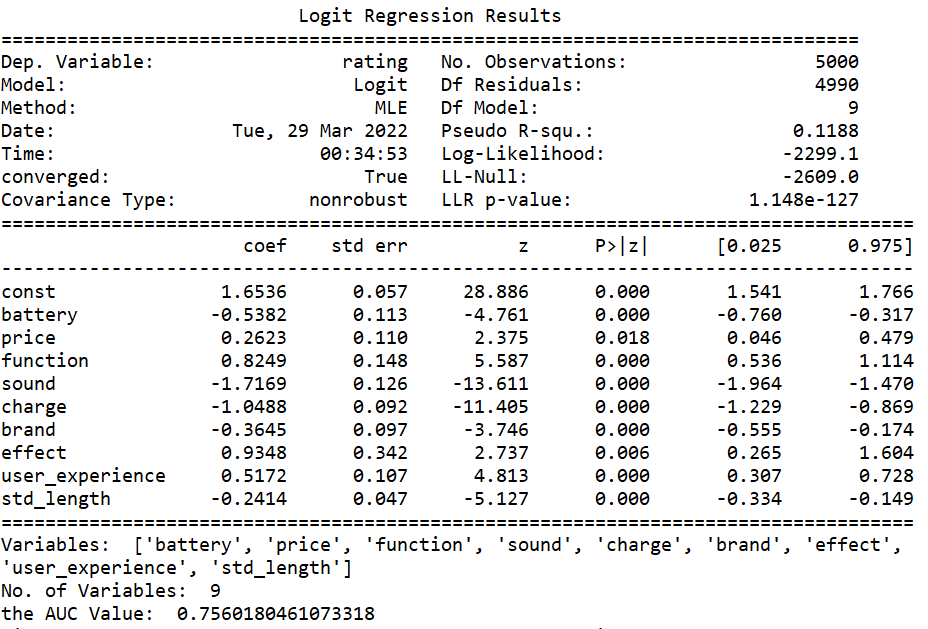
Result visualization and analysis
It is easy to visualize the fit of the model.
def draw_curve(fpr,tpr,roc_auc,save_name):
###make a plot of roc curve
plt.figure(dpi=150)
lw = 2
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title(save_name)
plt.legend(loc="lower right")
plt.savefig(path+os.sep+save_name+'.jpg')
plt.show()
print('Figure was saved to ' + path)
draw_curve(fpr,tpr,roc_auc,'Product Attributes - Scoring Model')
Output:
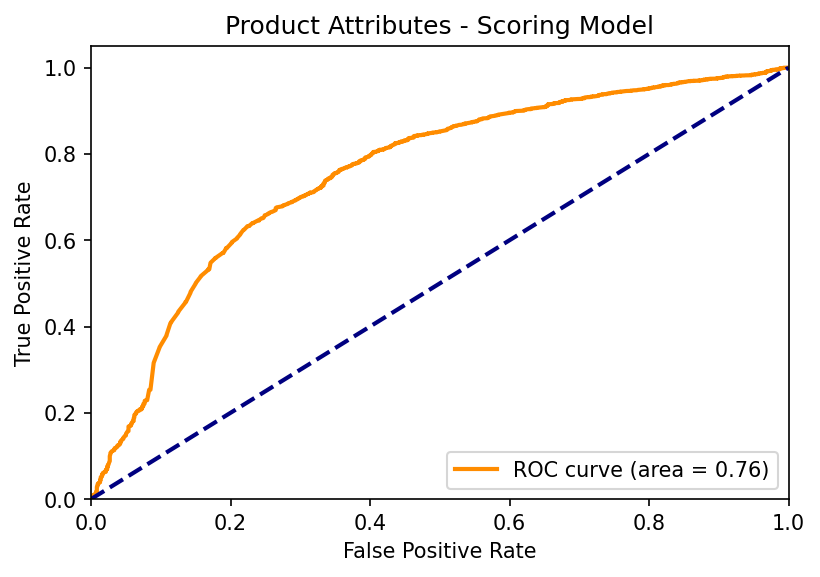
With an AUC value of 0.76, this model fits quite well enough to explain the relationship between variables and dependent variables. I visualize the coefficients of the different variables:
def draw_variablesimportance(save_name="Variances Importances"):
plt.rcParams['axes.unicode_minus']=False
coef_LR = pd.Series(lr_model.coef_[0][:-1].flatten(),index = pools[:-1],name = 'Var')
plt.figure(figsize=(8,4.5),dpi=150)
coef_LR.sort_values().plot(kind='barh')
plt.title("Variances Importances")
plt.savefig(path+os.sep+save_name+'.png')
plt.show()
draw_variablesimpo
Here I use the results of the first regression.
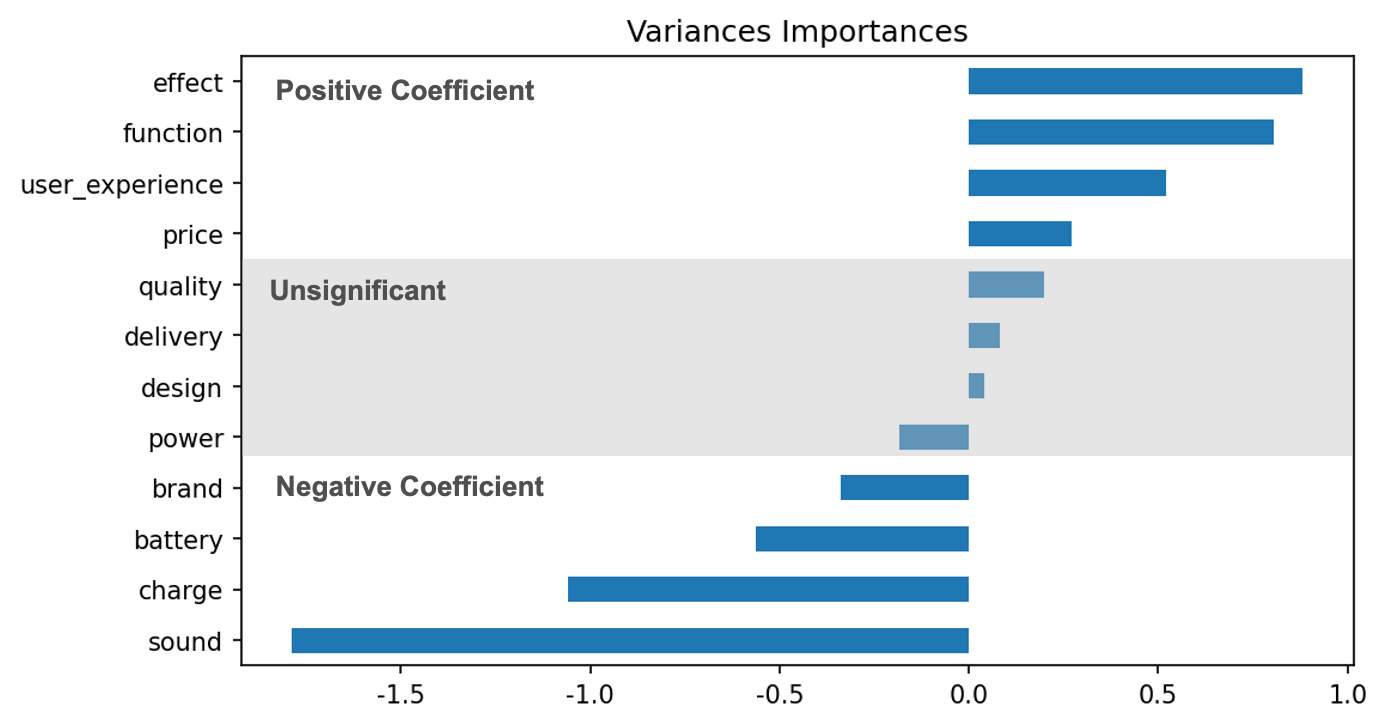
The larger the coefficient, the greater the impact of the variable on the evaluation results. Insignificant variables are in the middle of the diagram, their coefficients are so small that we can ignore them. The coefficients of variables effect, function, user_experience, price are positive, which means that customers think Oral-B products are great due to these attributes. On the contrary, the coefficients of sound, charge, battery, and brand are negative, which means that these attributes drag the product down and reduce customer satisfaction.
With this chart, decision-makers will have a clear understanding of which attributes need to be improved and which attributes need to be maintained. I briefly wrote some of my own insights, and I believe others can gain more insight from this data.
Oral-B should spend more time and money on the research about how to lower the noise made by the toothbrush and how to improve the battery life and charging speed. On the same time, Oral-B should keep the advantage of cleaning effect and nice user experience, and maybe can even slightly rise the goods price since few people can not afford the current price.