By Group "NLP_0"
This blog describes the problems and adjustments we made during preprocessing.
From Annual Reports to Nouns List
1.Ideas and Goals
After collecting the text of the annual reports of all U.S. public companies from the SEC Edgar Website, the raw text data needs to be processed. The purpose of this step is to transform the text in the "Item 1 business" section of the raw annual report text into a list of nouns that does not contain geographical and temporal nouns. The main packages used are spacy and nltk.
2.Core Function : getn (cik,year)
The function getn (cik,year), as the main function to achieve the result , has the following processing steps.
(1) Automatically select the required text
Only the "Item 1 Business" part of the text needs to be analyzed, some of the text material has subsequent item 1a and item 1b parts that do not need to be analyzed. This is achieved by the following code.
- Slice and dice the text into lists by sentence, converting all characters to lowercase
- Iterate through the sentence until the string 'item 1a' is found in the sentence, and if 'item 1a' is not found, look for the string 'item 1b' (taking into account that Some text does not have 1a but only part 1b
- Once the string 'item 1a' is found, the ordinal number of this sentence is returned and all previous texts are selected for analysis, and if neither keyword is found, the full text is selected.
text = f.readlines()
for i in text:
#i = str(i)
if 'item 1a' in i.lower():
a_index = text.index(i)
bus_list = text[:a_index]
print('find item 1a')
break
elif 'item 1b' in i.lower():
b_index = text.index(i)
bus_list = text[:b_index]
print('can not find item 1a find 1b')
break
else:
bus_list = text
if bus_list == text:
print('only have business')
(2) Identify the entities to be removed
Use the spacy package to extract all entities in the text and store the location entities and time entities labeled 'GPE' and 'DATE' in drop_list.
drop_list = []
doc = nlp(con_str)
for word in list(doc.ents):
#print(str(word), str(word.label_))
if str(word.label_) == 'GPE' or str(word.label_) == 'DATE':
drop_list.append(str(word))
(3) Generate a list of target nouns
Read the text, remove all the strings in drop_list by the replace method corresponding to the strings, and obtain the text that does not contain the time and place entities. Analyze each word, get the attributes of each word of the text by word.pos_, keep the words with the attributes PROPN and NOUN, and remove some of the nonsense characters observed by sampling check.
for word in list(doc_):
if (str(word.pos_) == 'PROPN' or str(word.pos_) == 'NOUN') and str(word) != '%' and str(word) != '10-Q' and ('(' not in str(word)) and str(word) not in ['one','two','three','four','five'] and str(word) != 'ITEM' and str(word) != 'BUSINESS' and ('www' not in str(word)) :
n_list.append(str(word))
(4) Outputting a list of nouns
An annual report outputs a list of nouns.
3.Overall processing logic
Each company corresponds to a cik folder in which the text of annual reports from 2010-2021 is stored according to a uniform format.
Through cik_list = os.listdir(path) to generate a list of cik corresponding to the folder name under the path, traverse the folder to extract the contents of each annual report to getn (cik,year) function, the output noun list.
ik_list = os.listdir(path)
print(len(cik_list))
#cik_list = cik_list[:5]
num = 0
for a in cik_list:
cik_dic ={}
mda = {}
business = {}
txt_path = path +"\\"+a
#print(txt_path)
if len(os.listdir(txt_path)) == 0:
print(a +"folder is empty")
else:
print(a +"folder is not empty")
txt_list = os.listdir(txt_path)
for b in txt_list:
cik_value = b[5:15]
year_value = b[16:20]
type_value = b[25:][:-4]
#print(year_value)
if type_value == 'business':
if year_value == '2010':
list_b = getn(cik_value, year_value)
n_2010[cik_value] = list_b
if year_value == '2011':
list_b = getn(cik_value, year_value)
n_2011[cik_value] = list_b
if year_value == '2012':
list_b = getn(cik_value, year_value)
n_2012[cik_value] = list_b
4.Result format and storage method
Store the list of nouns in the form of dictionary, key value is cik, value is the list of nouns, each year corresponds to a dictionary. Store the dictionaries as pickle files.
name_list = ['n_2010','n_2011','n_2012','n_2013','n_2014','n_2015','n_2016','n_2017','n_2018','n_2019','n_2020','n_2021']
res_list = [n_2010,n_2011,n_2012,n_2013,n_2014,n_2015,n_2016,n_2017,n_2018,n_2019,n_2020,n_2021]
for i in range(len(name_list)):
with open(name_list[i]+'.txt', 'wb') as file:
pickle.dump(res_list[i], file)
Dictionary format:
{'0000001750': ['General', 'AAR', 'CORP', '.', 'subsidiaries', 'herein', 'AAR', 'Company', 'context', 'AAR', 'provider', 'products', 'services', 'aviation', 'government', 'defense', 'markets', 'plan', 'strategy', 'class', 'aviation', 'services', 'business', 'segments', 'Aviation', 'Services', 'Expeditionary', ...],'0000001800':['GENERAL', 'DEVELOPMENT', 'Laboratories', 'corporation', 'business', 'discovery', 'development', 'manufacture', 'sale', 'line', 'health', 'care', 'products',...]...}
Turning Nouns List into BoW Matrix
As the first stage of data cleaning is mostly about overcoming the volume and disarray in the raw data, we find it necessary to continue refining nouns list during vectorization.
- Here is a random check of nouns from initial stage. Some problems that will affect later analyses are
-
- duplicate words: as we will create a binary BoW matrix, how many times a word appears is not useful
- inconsistent formats: all capital, initial capital, capital followed by numbers were used to identify Nouns and Proper Nouns, but formats do not convey extra information for later analyses
- weird symbols(likely residual html entities): they simply add noises
- split words and repetition of section title "Item 1 Business": they serve a signposting role, but we decide to discard them to focus on actual contents

So we define a customized tokenizer as a parameter in sklearn.feature_extraction.text.CountVectorizer,
along with restrictions on across-document word frequency (max_df and min_df) to get BoW matrix.
# clean nouns and create BoW matrix
def custom_tokenizer(doc):
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
import enchant
stop_words = stopwords.words('english')
stop_words.extend(['item', 'general', 'business', 'overview'])
wnl = WordNetLemmatizer()
en_dict = enchant.Dict('en_US')
tokens = word_tokenize(doc)
tokens = [t for t in tokens if t not in stop_words]
tokens = [t for t in tokens if not t.isnumeric()]
tokens = [t for t in tokens if t.lower().isalpha()]
tokens_pn = [t for t in tokens if (t.isupper()) or (t.istitle())]
tokens_cn = [wnl.lemmatize(t,pos='n') for t in tokens if en_dict.check(t)]
tokens = list(set(tokens_pn).union(set(tokens_cn)))
return tokens
from sklearn.feature_extraction.text import CountVectorizer
v = CountVectorizer(tokenizer=custom_tokenizer, max_df=0.50, min_df=0.01) #unique words
word_matrix = v.fit_transform(ciks_doc).toarray() #should have shape(len(cik), len(word_list))
word_list = v.get_feature_names_out().tolist()
print(f"Word matrix has shape: {word_matrix.shape}")
print(f'Number of companies: {len(ciks)}, number of words: {len(word_list)}')
First check if our word format problems have been addressed:

This image shows that, on the surface, all words appear to be unique, consistently-formatted nouns (some very short words stand out, like "z", "ab", but they may come from proper nouns abbreviations, so we keep them).
Next we further check word quality by its meaningfulness. As the matrix consists of each company's product nouns, we can use this as a dictionary, and look up certain companies by its product/service keywords. For example, we choose "software", "computer", and "program" to find CIKs of companies that broadly fit into internet, computer manufacturing, etc. businesses. We link CIKs to our Compustat company name list and industry classification variables to get details.
# check keywords: software, computer, program
for keyword in ['software', 'computer', 'program']:
if keyword in word_list:
print(f'{keyword} in word_list, index is {word_list.index(keyword)}')
else:
print(f'{keyword} not in word_list.')
# software, computer are in word_list, index 3388, 746
mask = word_matrix[:, [3388, 746]] != 0
comp_ciks = pd.Series(ciks)[np.any(mask, axis=1)].tolist()
# load pre-compiled company name list for look-up
df = pd.read_csv('company_name_cik.csv')
df = df.dropna()
df = df.drop_duplicates()
df[['cik', 'sic', 'naics']] = df[['cik', 'sic', 'naics']].astype('int').astype('str')
df['cik'] = df['cik'].apply(lambda x: x.rjust(10, '0'))
print(df[df.cik.isin(comp_ciks)])
Partial results are shown in this image:
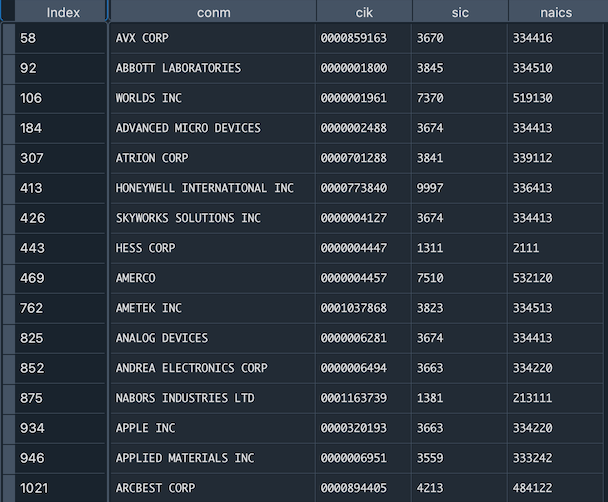
According to Yahoo Finance, the third company, Worlds Inc., is in Technology sector, software-application industry, which dovetails our expectation; another company, ATRION Corp., is in Healthcare sector, medical instruments and suppliers industry (see corresponding page on Yahoo Finance), which shows relatively weak link to our idea of technology firms. A further dive into the original 10-K text shows that ATRION is focused on developing medical devices, some of them are software-based. Also, the company itself is in the process of updating its own Enterprise Resource Planning and software systems. Overall, it seems fair to include ATRION as a technology firm. Other companies down the list also seem related to Internet, Technology and Software, albeit requiring some disambiguation, indicating that our company product dictionary is reasonably accurate. With this, we consider the matrix ready for later clustering and similarity calculation.
Extract Competition Mentions from MD&A Section, and Preserve Meaning
As we intend to use management's discussion of competition as an alternative competition measure, we explicitly count competition words, i.e., "competition", "competitor", "compete", "competitive", and divide the count by MD&A section length to increase comparability. However, this measure suffers from at least two problems: firstly, it is quite limited in range, as most are below 0.1; secondly, it assumes that competition intensity comes from repetition of the keyword 'competition', which potentially misses out adjectives describing competition intensity, e.g., 'significant competition', and the general context.
- To improve on this measure, we add two elements:
-
- incorporate sentiment score of competition sentences using
nltk.sentiment.vader - incorporate synonyms for lemmatized "competition" words using
nltk.corpus.wordnet
- incorporate sentiment score of competition sentences using
The codes used for these tasks are simple, and we only include a snippet here for the sake of being complete.
# para level
for para in doc_paras:
# sentence level
doc_sents = sent_tokenize(para)
# keep sentences that have compet_syns
for sent in doc_sents:
compet_words = [word for word in word_tokenize(sent)
if wnl.lemmatize(word) in compet_syns]
# if mention compet, calculate sentence sentiment
if compet_words:
print(sent)
print(compet_words)
doc_mentions.extend(compet_words)
sentiment = sid.polarity_scores(sent)
print(sentiment)
doc_sentiments.append(sentiment['compound'])
# compound score of 0 means the sentence is neutral
# append at doc level
compet_mentions.append(doc_mentions)
compet_sentiments.append(doc_sentiments)
What we find quite interesting is the nuance after adding these steps, although they do not improve the data range and still capture limited meaning.
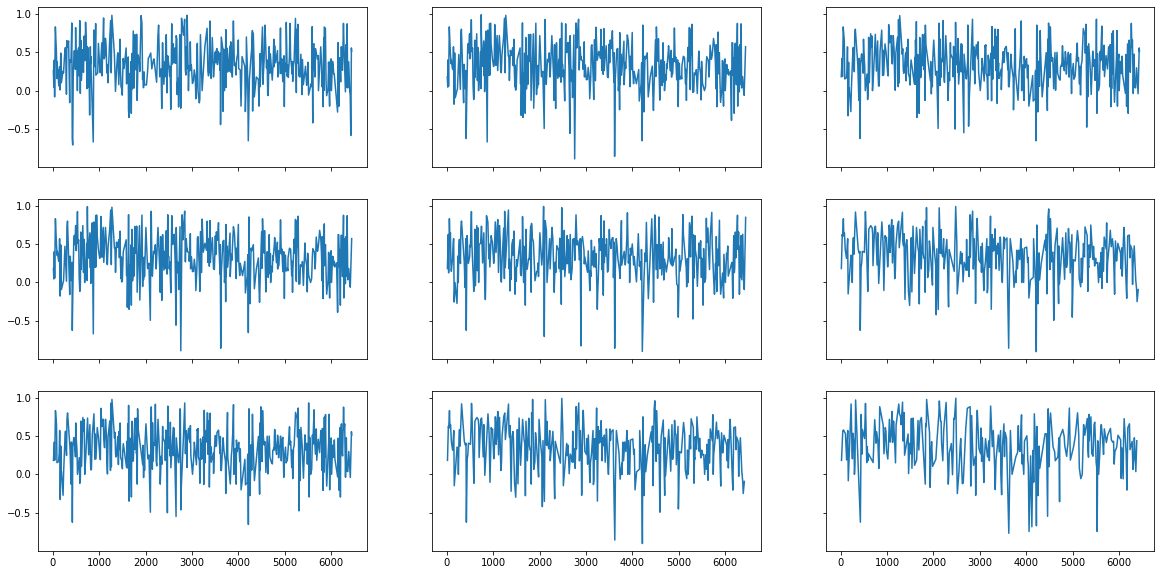
For the first step, we only keep the compound sentiment score, which is between -1 and 1, with 0 being completely neutral. The results are still mostly small numbers around 0, but positive scores prevail. This reveals that management's attitudes toward competition, or more precisely, assessments of competition mentioned in MD&A, are not necessarily negative. In fact, in the majority of the years in our sample (2010 to 2021), sentences including companies' competition mentions are mostly scored to be positive. The graph shows nine years (2012 to 2020), and the shared y axis makes it easy to see that most data is above 0. This may show that management are slightly biased to make good impressions.
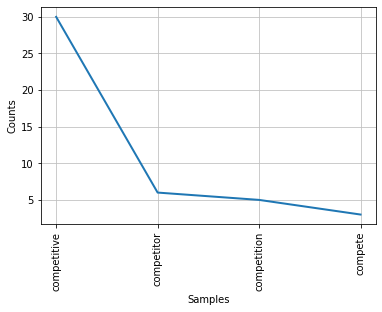
For the second step, although we are able to expand search to more words (i.e., "rival", "contender", "vie"), the result seems to show that management strongly prefer to use "compet-" words. The following two plots show the vocabulary and its frequency from 2011 to 2021 for two randomly-chosen companies.