By Group "N95 Limited Partner"
#Group objective
Our group project is 'Stock price prediction and trading strategy creation based on company disclosures'. Our goal is to create a tool that can collect text data from company disclosure and analyze the impact of company disclosures on stock prices. We try using NLP to analysis text data from company disclosure. Then we will try multiple deep learning algorithms to find out the potential relationship between company disclosure and change of stock price , and we will compare their performance on the same data. The whole process of our project is dividied into 5 steps which are data collection, data cleansing and preprocessing, data labelling, model construction and comparison and investment strategy and backtesting.
#NLP third Blog
This is the third blog of N95 Limited Partner. In the third blog, we would like to share our experience in Textblob, Nltk polarity and FinBert with preprocess. We faced many challenges when doing this part, but we overcame them.
Data preprocessing
We start with data pre-processing. We try to make our data more meaningfull and applicable.
Problem-01: How do we turn text into usable data?
Solution: Annual company disclosures of 31 firms on SEC official website are be scrapped by taking advantages of webdriver and seperate each disclosure into 4 section, business, risk factors, management discussion and disclosure market risk. Then to make the analysis as meaningful as possible, operations below are token: - Lowercase the sentences - Change "’t" to "not" - Remove "@name" - Remove punctuation - Remove numbers - Remove some special characters - Remove stop words except "not" and "can" - Remove elements lower than 8 words
import nltk
# download stopwords
nltk.download("stopwords")
from nltk.corpus import stopwords
def text_preprocessing(s):
"""
- Lowercase the sentence
- Change "'t" to "not"
- Remove "@name"
- Remove punctuations
- Remove numbers
- Remove some special characters
- Remove stop words except "not" and "can"
- Remove elements lower than 5 words
"""
s = s.lower()
# Change 't to 'not'
s = re.sub(r"\'t", " not", s)
# Remove @name
s = re.sub(r'(@.*?)[\s]', ' ', s)
# Isolate and remove punctuations
s = re.sub(r'[^\w\s]', '', s)
# Remove numbers
s = ''.join([i for i in s if not i.isdigit()])
# Remove some special characters
s = re.sub(r'([\|•«])', ' ', s)
# Remove stopwords except 'not' and 'can'
s = " ".join([word+"\n" for word in s.split("\n") if word not in stopwords.words("english") or word in ["not","can"]])
# Remove elements lower than 8 words
s = " ".join(sentence.strip()+"\n" for sentence in s.split("\n") if len(sentence.split())>8)
return s
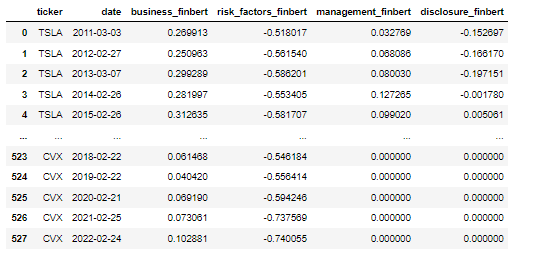
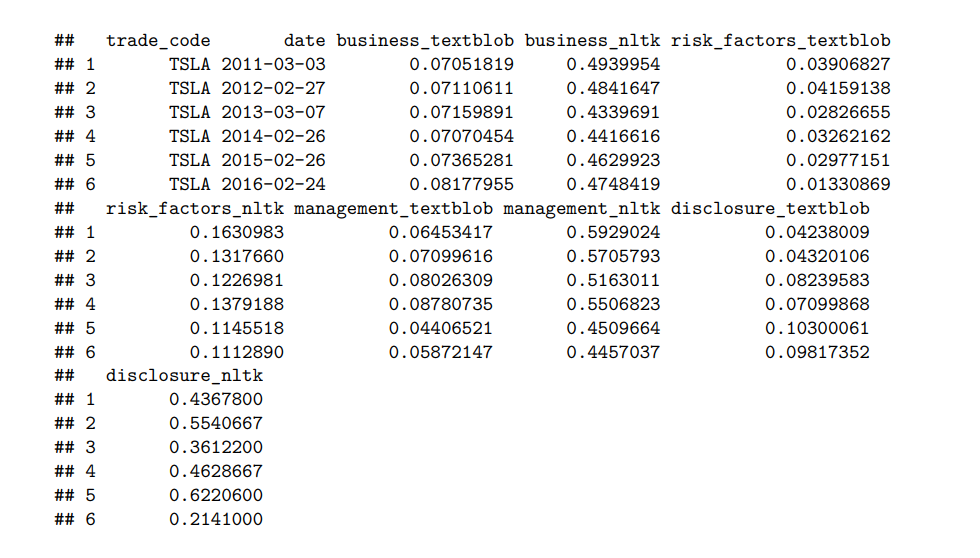
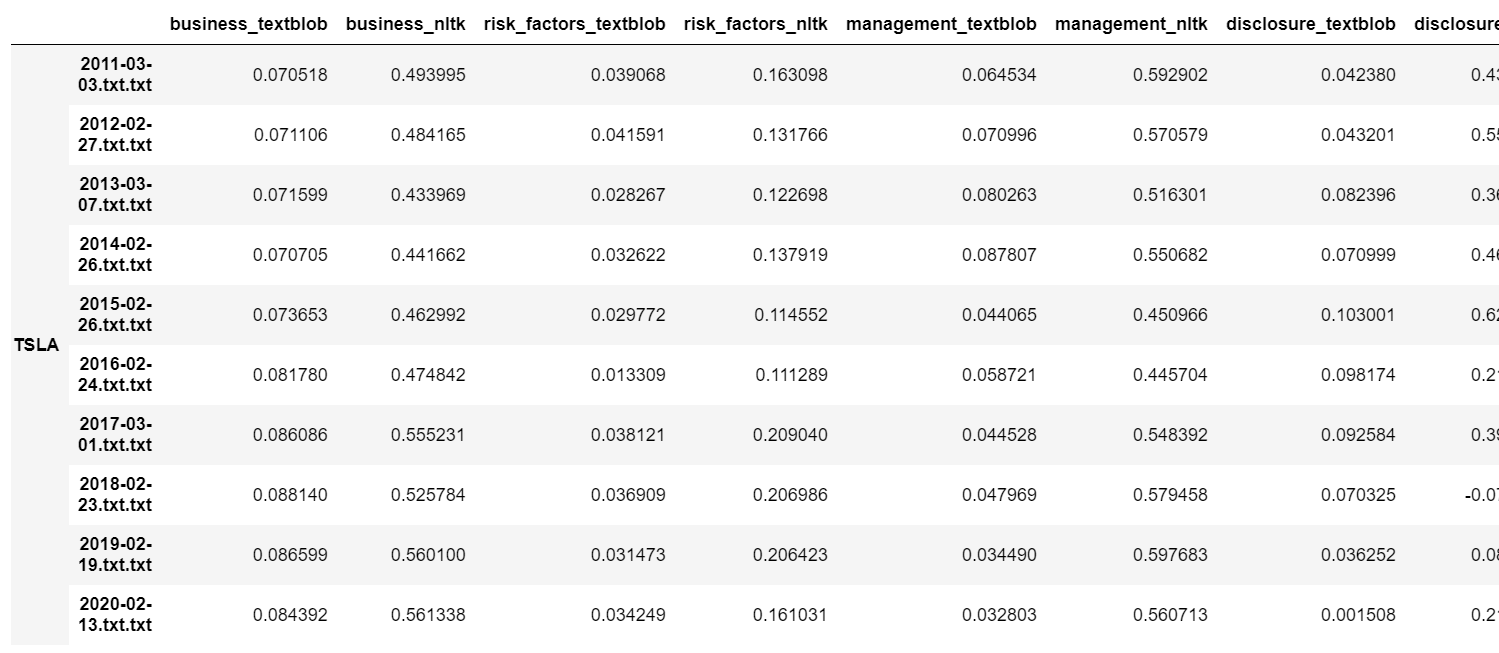
After data pre-processing, NLTK and TextBlob are used to do the sentiment analysis, and return polarity scores. Table below is the first 7 rows of data, which is Tesla’s data, after all the cleaning and pre-processing jobs are done. (Here disclosure in the coloum name implies disclosure market risk.
from textblob import TextBlob
from nltk.sentiment.vader import SentimentIntensityAnalyzer
nltk.download('vader_lexicon')
sent_engine = SentimentIntensityAnalyzer()
def get_blob_sentiment(sentence):
result = TextBlob(sentence).sentiment
return result.polarity
def get_nltk_sentiment(sentence):
result = sent_engine.polarity_scores(sentence)
return result['compound']
Next, we do sentiment analysis step by step.
result_dict = {}
for ticker in tickers:
result_dict[ticker] = {}
business_path = f"data/{ticker}/business"
risk_path = f"data/{ticker}/risk factors"
management_path = f"data/{ticker}/management discussion"
disclosure_path = f"data/{ticker}/disclosure market risk"
for file in os.listdir(business_path):
result_dict[ticker][file] = {}
if file.endswith(".txt"):
file_path = f"{business_path}/{file}"
with open(file_path, encoding="utf8") as f:
example_text = f.read()
processed_text = text_preprocessing(example_text)
pharases = processed_text.split("\n")
total_textblob = 0
total_nltk = 0
num = len(pharases)
for phrase in pharases:
phrase_blob_polarity = get_blob_sentiment(phrase)
total_textblob += phrase_blob_polarity
phrase_nltk_polarity = get_nltk_sentiment(phrase)
total_nltk += phrase_nltk_polarity
average_textblob = total_textblob/num
average_nltk = total_nltk/num
result_dict[ticker][file]["business_textblob"] = average_textblob
result_dict[ticker][file]["business_nltk"] = average_nltk
for file in os.listdir(risk_path):
if file.endswith(".txt"):
file_path = f"{risk_path}/{file}"
with open(file_path, encoding="utf8") as f:
example_text = f.read()
processed_text = text_preprocessing(example_text)
pharases = processed_text.split("\n")
total_textblob = 0
total_nltk = 0
num = len(pharases)
for phrase in pharases:
phrase_blob_polarity = get_blob_sentiment(phrase)
total_textblob += phrase_blob_polarity
phrase_nltk_polarity = get_nltk_sentiment(phrase)
total_nltk += phrase_nltk_polarity
average_textblob = total_textblob/num
average_nltk = total_nltk/num
result_dict[ticker][file]["risk_factors_textblob"] = average_textblob
result_dict[ticker][file]["risk_factors_nltk"] = average_nltk
for file in os.listdir(management_path):
if file.endswith(".txt"):
file_path = f"{management_path}/{file}"
with open(file_path, encoding="utf8") as f:
example_text = f.read()
processed_text = text_preprocessing(example_text)
pharases = processed_text.split("\n")
total_textblob = 0
total_nltk = 0
num = len(pharases)
for phrase in pharases:
phrase_blob_polarity = get_blob_sentiment(phrase)
total_textblob += phrase_blob_polarity
phrase_nltk_polarity = get_nltk_sentiment(phrase)
total_nltk += phrase_nltk_polarity
average_textblob = total_textblob/num
average_nltk = total_nltk/num
result_dict[ticker][file]["management_textblob"] = average_textblob
result_dict[ticker][file]["management_nltk"] = average_nltk
for file in os.listdir(disclosure_path):
if file.endswith(".txt"):
file_path = f"{disclosure_path}/{file}"
with open(file_path, encoding="utf8") as f:
example_text = f.read()
processed_text = text_preprocessing(example_text)
pharases = processed_text.split("\n")
total_textblob = 0
total_nltk = 0
num = len(pharases)
for phrase in pharases:
phrase_blob_polarity = get_blob_sentiment(phrase)
total_textblob += phrase_blob_polarity
phrase_nltk_polarity = get_nltk_sentiment(phrase)
total_nltk += phrase_nltk_polarity
average_textblob = total_textblob/num
average_nltk = total_nltk/num
result_dict[ticker][file]["disclosure_textblob"] = average_textblob
result_dict[ticker][file]["disclosure_nltk"] = average_nltk
result_dict = {}
for ticker in tickers:
result_dict[ticker] = {}
business_path = f"data/{ticker}/business"
risk_path = f"data/{ticker}/risk factors"
management_path = f"data/{ticker}/management discussion"
disclosure_path = f"data/{ticker}/disclosure market risk"
for file in os.listdir(business_path):
result_dict[ticker][file] = {}
if file.endswith(".txt"):
file_path = f"{business_path}/{file}"
with open(file_path, encoding="utf8") as f:
example_text = f.read()
processed_text = text_preprocessing(example_text)
sentences = processed_text.split("\n")
try:
nlp = pipeline("sentiment-analysis",model=finbert,tokenizer=tokenizer)
results = nlp(sentences)
total = 0
num = len(results)
for result in results:
if result["label"] == "negative":
total += result["score"]*-1
elif result["label"] == "positive":
total += result["score"]
else:
continue
average = total/num
result_dict[ticker][file]["business_finbert"] = average
except:
result_dict[ticker][file]["business_finbert"] = 0
for file in os.listdir(risk_path):
if file.endswith(".txt"):
file_path = f"{risk_path}/{file}"
with open(file_path, encoding="utf8") as f:
example_text = f.read()
processed_text = text_preprocessing(example_text)
sentences = processed_text.split("\n")
try:
nlp = pipeline("sentiment-analysis",model=finbert,tokenizer=tokenizer)
results = nlp(sentences)
total = 0
num = len(results)
for result in results:
if result["label"] == "negative":
total += result["score"]*-1
elif result["label"] == "positive":
total += result["score"]
else:
continue
average = total/num
result_dict[ticker][file]["risk_factors_finbert"] = average
except:
result_dict[ticker][file]["risk_factors_finbert"] = 0
for file in os.listdir(management_path):
if file.endswith(".txt"):
file_path = f"{management_path}/{file}"
with open(file_path, encoding="utf8") as f:
example_text = f.read()
processed_text = text_preprocessing(example_text)
sentences = processed_text.split("\n")
try:
nlp = pipeline("sentiment-analysis",model=finbert,tokenizer=tokenizer)
results = nlp(sentences)
total = 0
num = len(results)
for result in results:
if result["label"] == "negative":
total += result["score"]*-1
elif result["label"] == "positive":
total += result["score"]
else:
continue
average = total/num
result_dict[ticker][file]["management_finbert"] = average
except:
result_dict[ticker][file]["management_finbert"] = 0
for file in os.listdir(disclosure_path):
if file.endswith(".txt"):
file_path = f"{disclosure_path}/{file}"
with open(file_path, encoding="utf8") as f:
example_text = f.read()
processed_text = text_preprocessing(example_text)
sentences = processed_text.split("\n")
try:
nlp = pipeline("sentiment-analysis",model=finbert,tokenizer=tokenizer)
results = nlp(sentences)
total = 0
num = len(results)
for result in results:
if result["label"] == "negative":
total += result["score"]*-1
elif result["label"] == "positive":
total += result["score"]
else:
continue
average = total/num
result_dict[ticker][file]["disclosure_finbert"] = average
except:
result_dict[ticker][file]["disclosure_finbert"] = 0
Finally, we fill in the dataframe with the sentiment factors we get from the analysis process.
total_result = pd.DataFrame.from_dict({(i,j): result_dict[i][j]
for i in result_dict.keys()
for j in result_dict[i].keys()},
orient='index')
Output of Textblob and Nltk polarity with preprocess
Output of FinBert with preprocess