By Group "N95 Limited Partner"
#Group objective
Our group project is 'Stock price prediction and trading strategy creation based on company disclosures'. Our goal is to create a tool that can collect text data from company disclosure and analyze the impact of company disclosures on stock prices. We try using NLP to analysis text data from company disclosure. Then we will try multiple deep learning algorithms to find out the potential relationship between company disclosure and change of stock price , and we will compare their performance on the same data. The whole process of our project is dividied into 5 steps which are data collection, data cleansing and preprocessing, data labelling, model construction and comparison and investment strategy and backtesting.
#NLP second Blog
This is the second blog of N95 Limited Partner. In the second blog, we would like to share our experience in the data preprocessing and data labelling. We faced many challenges when doing this part, but we overcame them.
Data labelling
The aim of this project is to create investment strategies, so the stock price movement after company disclosures released. Thus, each disclosure is labeled by its consequent stock price movement. For example, if i-th firm’s price increased from tn to tn+1 then label the closures of i-th firm published at tn as 1 otherwise 0. As for the length of time period, is it not sure how long the closure’s information takes to spread in the market, so different periods are be considered (1 week, 1 month, 3 months, 6 months, 9 months and 12 months).
Problem-01: How do we get the stock price history of those companies?
Checking the companies one by one wastes lots of time.
Solution: We use the python packaege 'Yfinance' to do that. 'Yfinance' is an open-source tool that uses Yahoo's publicly available APIs, and is intended for research and educational purposes.
The following is the sample code of yfinance.
import yfinance as yf
msft = yf.Ticker("MSFT")
# get stock info
msft.info
# get historical market data
hist = msft.history(period="max")
Problem-02: How do we get the label of stock price?
Solution: We estimate the label by comparing the stock price on start date with the stock price on end dtae. We abtain labels of price change in different periods (1 week, 1 month, 3 months, 6 months, 9 months and 12 months).
Output of Data Labelling
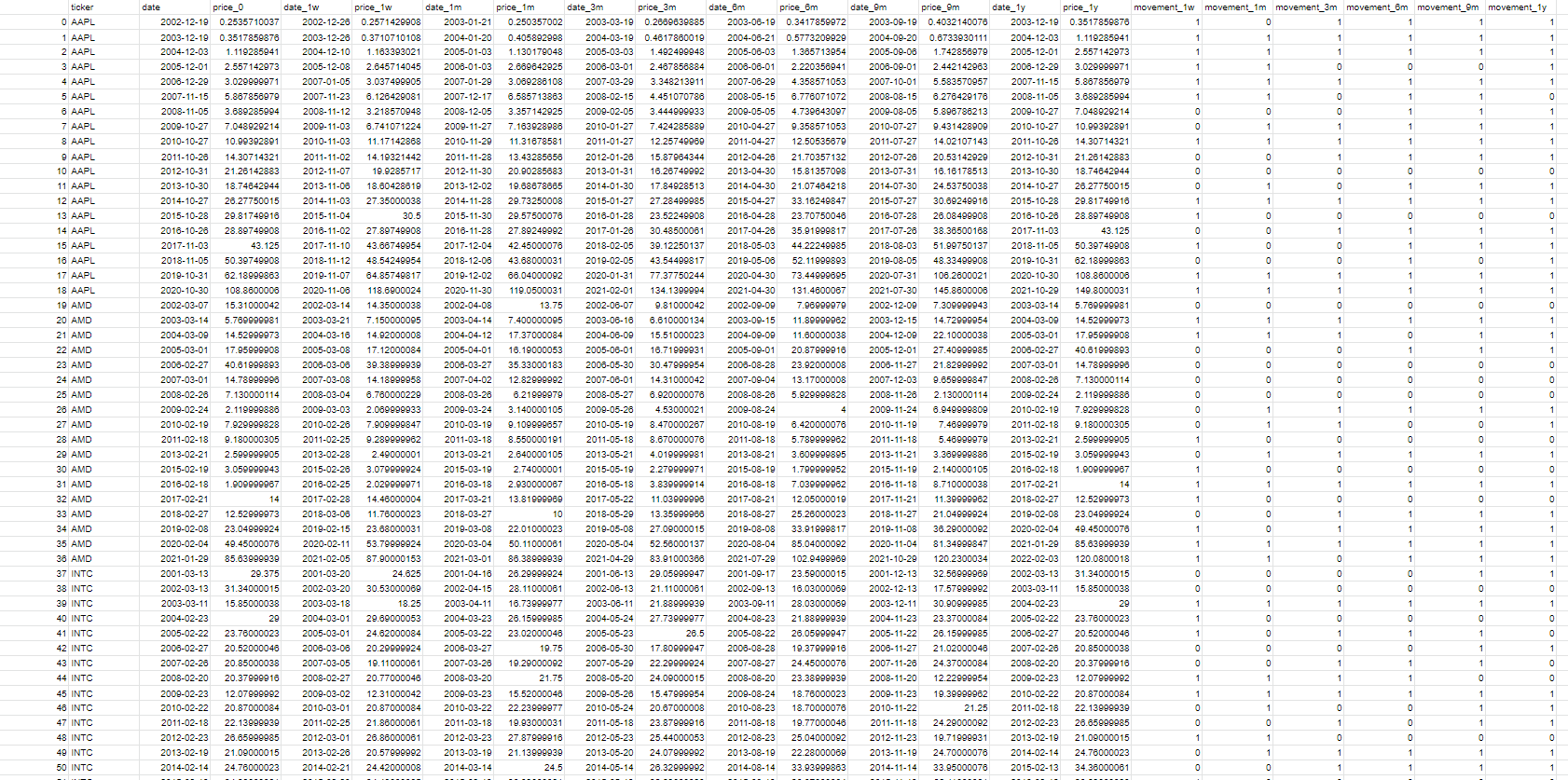
Data preprocessing
In order to facilitate our analysis and calculation, we need to do pre-processing and labelling of the original data obtained previously.
First, we start reading the company list of S&P500 and the company list of our dataset. We pick the first 33 companies as the sample.
tickers = os.listdir('data')
print(tickers)
for ticker in tickers:
ticker = ticker.strip()
print(ticker)
all_companies = pd.read_excel("SP500Companies.xlsx")
all_companies
analyzed_companies = all_companies.iloc[:33]
analyzed_companies
tickers = analyzed_companies["trade_code"]
tickers.drop(index=[15,24],inplace=True)
for ticker in tickers:
ticker = ticker.strip()
print(ticker)
Then we start processing the data.
Problem-03: Since the whole document should have downloaded as body text, documents include noisy parts and so much unnecessary parts.
For that reason, the data cleaning was performed more than one step. The first step is dividing the whole body text into sections Also, unncessary text such as "Table of content link text in every page" was deleted in this step. The main cleaning is performed in another code file. Please take a look at our third blog post for detailed explanation.
Solution:
In addition to problems, the meta text file was created in this step for further vocabulary set use while applying text vectorization.
path = r'C:\Users\baris\OneDrive\Masaüstü\HKU Fintech\MFIN7036-Text Analytics and NLP in Finance and Fintech\Project\data'
meta_text = ""
for ticker in tickers:
complete_path = path + f"/{ticker}"
os.chdir(complete_path)
for file in os.listdir():
if file.endswith(".txt"):
file_path = f"{complete_path}/{file}"
with open(file_path, encoding="utf8") as f:
first_text = f.read()
text = first_text.split("\n")
for index,value in enumerate(text):
if (value.strip().lower().startswith("item 1.")):
business_start = index
if (value.strip().lower().startswith("item 1a.")):
business_end = index
risk_start = index
if (value.strip().lower().startswith("item 1b.")):
risk_end = index
if (value.strip().lower().startswith("item 7.")):
management_start = index
if (value.strip().lower().startswith("item 7a.")):
management_end = index
disclosure_start = index
if (value.strip().lower().startswith("item 8.")):
disclosure_end = index
business_path = complete_path + "/business"
if not os.path.exists(business_path):
os.makedirs(business_path)
business_text = text[business_start:business_end]
complete_business_path = os.path.join(business_path,f'{file}.txt')
with open(complete_business_path,"w",encoding="utf-8") as f:
for item in business_text:
if len(item)>1 and (item !="Table of Contents"):
try:
if (int(item)):
continue
except:
f.write("%s\n" % item )
risk_path = complete_path + "/risk factors"
if not os.path.exists(risk_path):
os.makedirs(risk_path)
risk_text = text[risk_start:risk_end]
complete_risk_path = os.path.join(risk_path,f'{file}.txt')
with open(complete_risk_path,"w",encoding="utf-8") as f:
for item in risk_text:
if len(item)>1 and (item !="Table of Contents"):
try:
if (int(item)):
continue
except:
f.write("%s\n" % item )
management_path = complete_path + "/management discussion"
if not os.path.exists(management_path):
os.makedirs(management_path)
management_text = text[management_start:management_end]
complete_management_path = os.path.join(management_path,f'{file}.txt')
with open(complete_management_path,"w",encoding="utf-8") as f:
for item in management_text:
if len(item)>1 and (item !="Table of Contents"):
try:
if (int(item)):
continue
except:
f.write("%s\n" % item )
disclosure_path = complete_path + "/disclosure market risk"
if not os.path.exists(disclosure_path):
os.makedirs(disclosure_path)
disclosure_text = text[disclosure_start:disclosure_end]
complete_disclosure_path = os.path.join(disclosure_path,f'{file}.txt')
with open(complete_disclosure_path,"w",encoding="utf-8") as f:
for item in disclosure_text:
if len(item)>1 and (item !="Table of Contents"):
try:
if (int(item)):
continue
except:
f.write("%s\n" % item )
all_path = complete_path + "/all"
if not os.path.exists(all_path):
os.makedirs(all_path)
all_text = text[business_start:disclosure_end]
complete_all_path = os.path.join(all_path,f'{file}.txt')
with open(complete_all_path,"w",encoding="utf-8") as f:
for item in all_text:
if len(item)>1 and (item !="Table of Contents"):
try:
if (int(item)):
continue
except:
f.write("%s\n" % item )
meta_text += "%s\n" % item
Output of data preprocessing
Finally we get the mata.text as shown below.
