By Group "SenseText"
In the previous blog, we shared the problems in text processing. After that, we converted text to numbers. The technical part of this step is quite straight forward, which includes BoW, tf-idf, and sentiment analysis. Nonetheless, we would like to share with you about the importance of code review in coding collaboratively.
Background
We separate the text processing task into two parts. The first part is to select two Bag of Words for the business description and risk factors, which is demonstrated in our last blog. The second part is to convert the two BoWs to quantitative factors for later clustering and valuation. The final output of text processing is shown below.
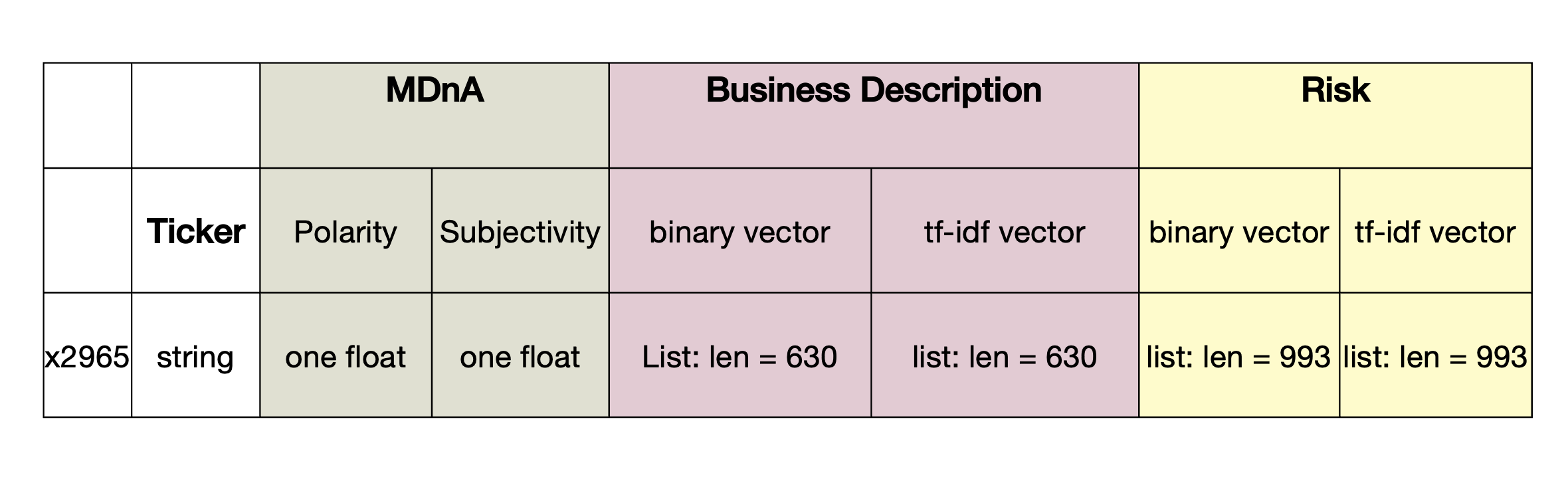
There are 2,965 rows standing for 2,965 companies. Each company has seven parameters as shown.
To save time, we parallel processed the coding for the two parts. Diana and Alice are responsible for the first part and Silvia takes charge of the second part.
Initial Version
We generated two BoWs in the first part without distinguishing each company. In other words, we mixed the tokens from each company up and put them into a single list instead of a list of lists.
Then, to build the binary and tf-idf factors for each company in the second part, the basic data processing, like stop words removal, lowercasing, and lemmatization, were conducted again because we need to distinguish the companies in the final result.
Hence, the second part took both the original factors from 10-K and the two BoWs as the inputs. The workflow of this step is as follows.
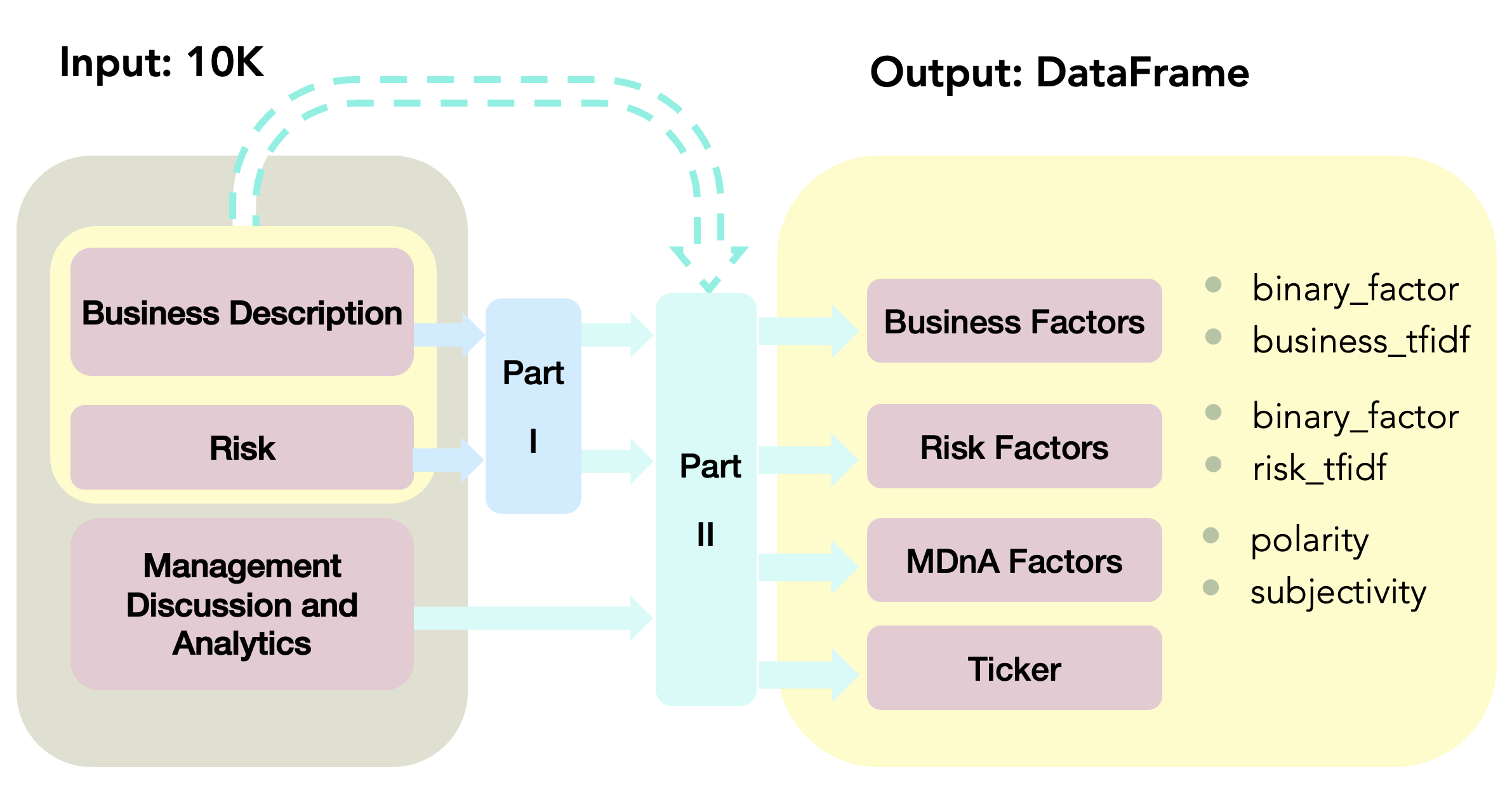
Review
After uploading the two code files to GitHub, we found that the basic data processing was conducted twice, which was quite time-consuming and wasted unnecessary computational power. It indicates that the process represented by the dotted arrow could have been avoided.
Improvement
If we simply change the form of the output of the first part to a list of lists, keeping the word appearance information for each company, the similar processes in the second part can be avoided.
It saved almost eight hours of data processing and clearly improved the efficiency of our codes.
Conclusion
In collaborative coding, we should always communicate with each other and keep each stage of coding consistent. Frequently reviewing the codes is essential.
A more efficient way may be found by just a small change of the codes.