By Group "SenseText"
We have currently finished text processing and transformation. Our texts are from the items in 10-K. The volume of the words is huge, and the processing is time-consuming. While struggling with bugs, we learned a lot from them and would like to share our experience with the whole class.
Data collection
We collected 2,965 10-K files. The Business Description, Risk Factors and Management Discussion and Analysis (MD&A) parts were stored as paragraphs in each grid of a dataframe.
Text Preprocessing
Then, we moved on to remove redundant information in the text and construct a Bag of Words based on the preprocessed information. Our basic workflow is
- Drop symbols, numbers, and single characters
- Remove stop words
- Convert words to lowercases
- Tokenize words and lemmatize according to tags
- Select words to form corpus
During our work, we have encountered the following problems.
Problem 1: Part of Speech Tagging and Lemmatization
Initially, we tried to lemmatize the raw strings first and then perform part of speech tagging. But this method could give us many unlemmatized words as the image shows:
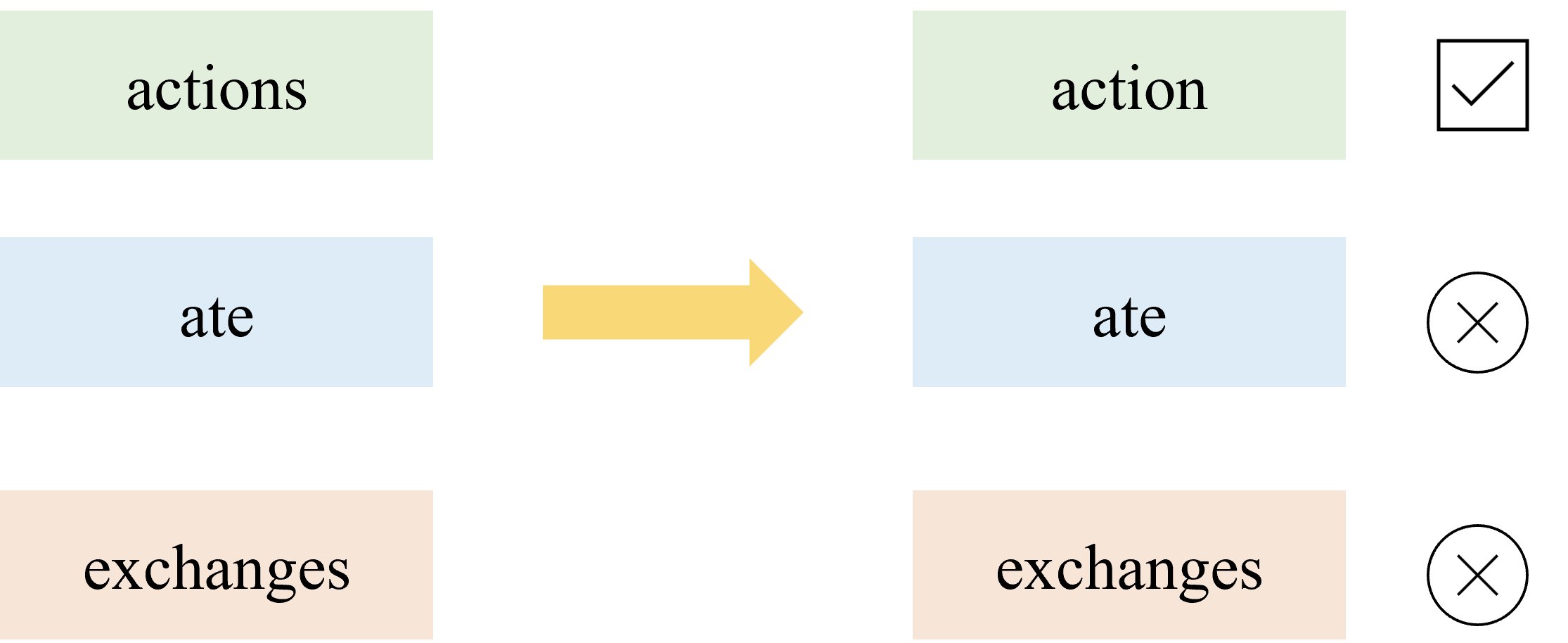
After taking a closer look at the results, we found that most of the unlemmatized words are verbs.
Then, we realized that the default setting of WordNetLemmatizer.lemmatize() is 'N'.
Hence, we wrote a function called lemma to pos tag the words in raw strings before lemmatization.
To keep subsequent analysis simpler, we only returned verb, noun, adjectives, adverbs, and foreign words.
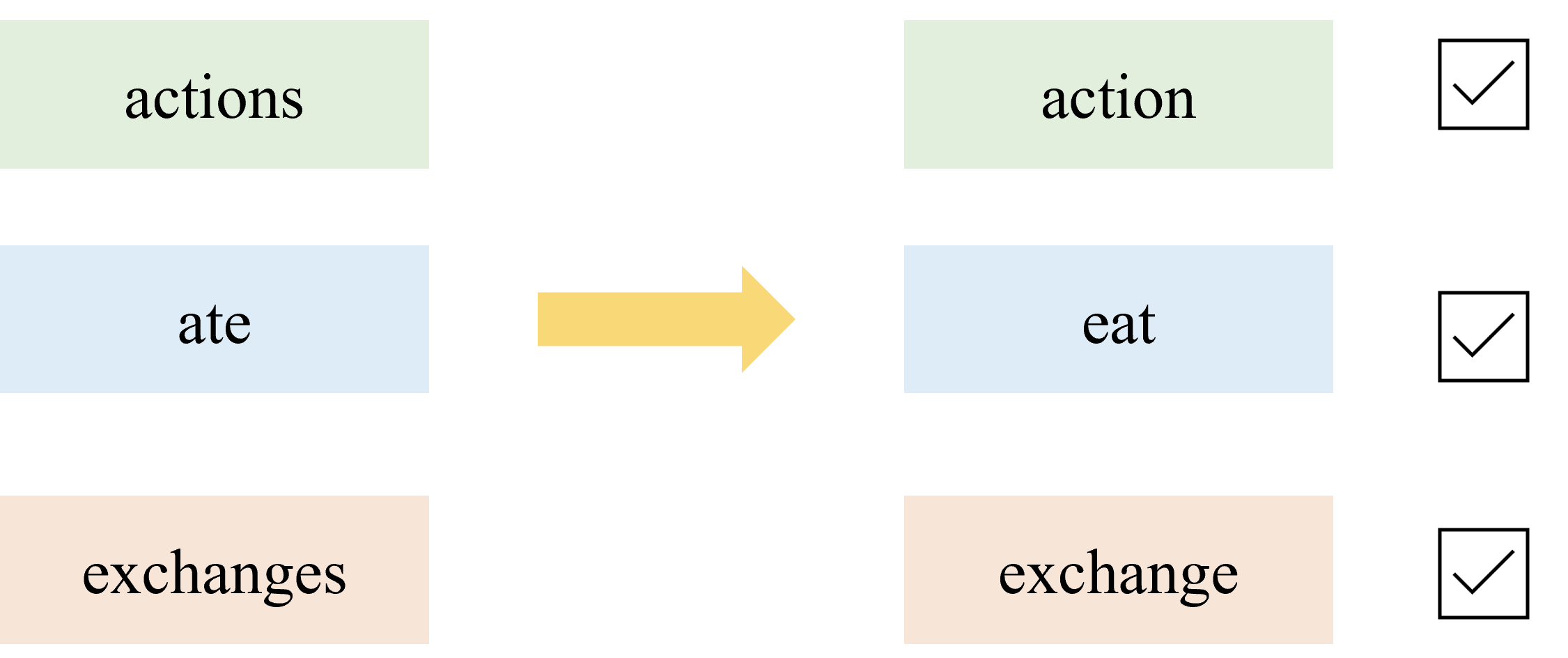
Below are our functions.
from nltk.stem import WordNetLemmatizer
# Return tag of words
wnl = WordNetLemmatizer()
def get_wordnet_pos(tag):
if tag.startswith('J'):
return wordnet.ADJ
elif tag.startswith('V'):
return wordnet.VERB
elif tag.startswith('N'):
return wordnet.NOUN
elif tag.startswith('R'):
return wordnet.ADV
elif tag.startswith('F'):
return wordnet.FW
else:
return None
# Lemmatize
def lemma(target_list):
lem_words = []
for i in range(len(target_list)):
if get_wordnet_pos(pos_tag([target_list[i]])[0][1]) == None:
continue
else:
print(i)
tem = wnl.lemmatize(target_list[i],
get_wordnet_pos(pos_tag([target_list[i]])[0][1]))
lem_words.append(tem)
return lem_words
After investigating the output, we decided to narrow our target parts of speech to nouns, verbs, and adverbs. For the business description item, we think nouns are the most significant since they describe the product/service. For the risk factor item, we think verbs and adverbs should also be included since they may describe the degree of risks and the company's responses.
Based on this logic, the codes for pos_tag and lemmatization were modified:
# Get word class and finish Lemmatization
from nltk import pos_tag
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet
wnl = WordNetLemmatizer()
def b_get_wordnet_pos(tag):
if tag.startswith('N'):
return wordnet.NOUN
else:
return None
def rf_get_wordnet_pos(tag):
if tag.startswith('N'):
return wordnet.NOUN
elif tag.startswith('V'):
return wordnet.VERB
elif tag.startswith('R'):
return wordnet.ADV
else:
return None
def lemma(target_b_list, target_rf_list):
lem_b_words = []
lem_rf_words = []
for word in target_b_list:
if b_get_wordnet_pos(pos_tag([word])[0][1]) == None:
continue
else:
tem = wnl.lemmatize(word,
b_get_wordnet_pos(pos_tag([word])[0][1]))
lem_b_words.append(tem)
for word in target_rf_list:
if rf_get_wordnet_pos(pos_tag([word])[0][1]) == None:
continue
else:
tem = wnl.lemmatize(word,
rf_get_wordnet_pos(pos_tag([word])[0][1]))
lem_rf_words.append(tem)
return lem_b_words, lem_rf_words
lem_words = lemma(lower_b_words, lower_rf_words)
Problem 2: Word Selection
The returned list of words is fairly large in size. We cannot keep all the words because
- It could cause the problem of excessive dimension.
- Some words with high frequency appeared in almost all 10-K files and have no special meaning.
Ideally, we need to slice the list and keep 500-1,000 relatively unique words that could reflect main ideas in the text for each item. By taking a closer look at the words in the returned lists, we decided to keep the words with term frequency between 1,200 and 20,000. The codes are as follows:
# Count the apparence frequency of all the noun
from collections import Counter
b_words_freq = Counter(lem_words[0])
rf_words_freq = Counter(lem_words[1])
def remove_key(d):
for key in list(d.keys()):
if (key.isalpha() == False) or (len(key)<2):
d.pop(key)
if (d[key] > 20000) or (d[key] <1200 ):
del a[k]
remove_key(b_words_freq)
remove_key(rf_words_freq)
At last, we get 630 nouns in the business description bag and 993 words in the risk factor bag.
Problem 3: Data Structure
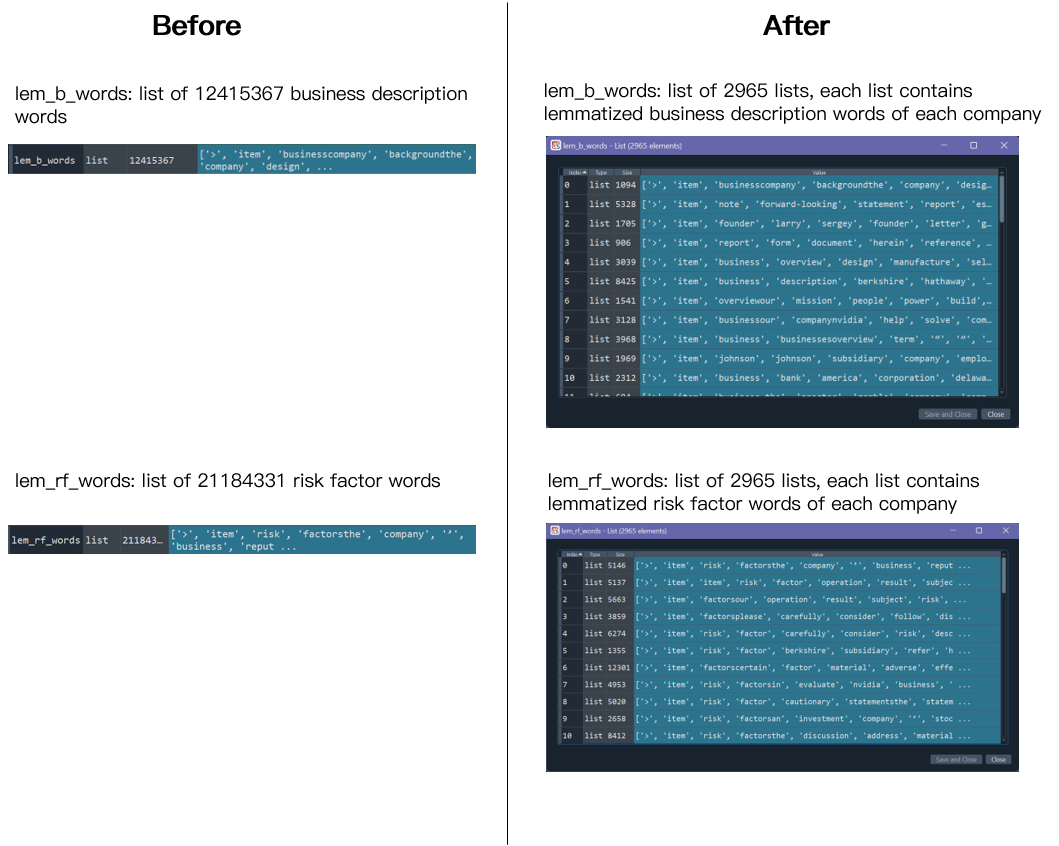
At the very beginning, we directly stored all the cleaned words of
each item in the same list. As a result, we got two lists of
words. When performing data transformation, we had to re-perform
pos_tag and lemmatize each word, which caused redundancy and was
very time-consuming. Thus, we modified the codes to save the
lemmatized words as two lists of lists.
Problem 4: List Reference and Copy
This problem is a minor one. It is caused by the confusion in object
reference. A list stores a set of references (or paths) to the objects
in computer memory. For example, list A in the picture below points to
the numbers 1, 2, 3 in memory. If we simply copy list A to list B
using the operator =, list B will only copy the object references,
i.e., B points to the same numbers in memory as A.
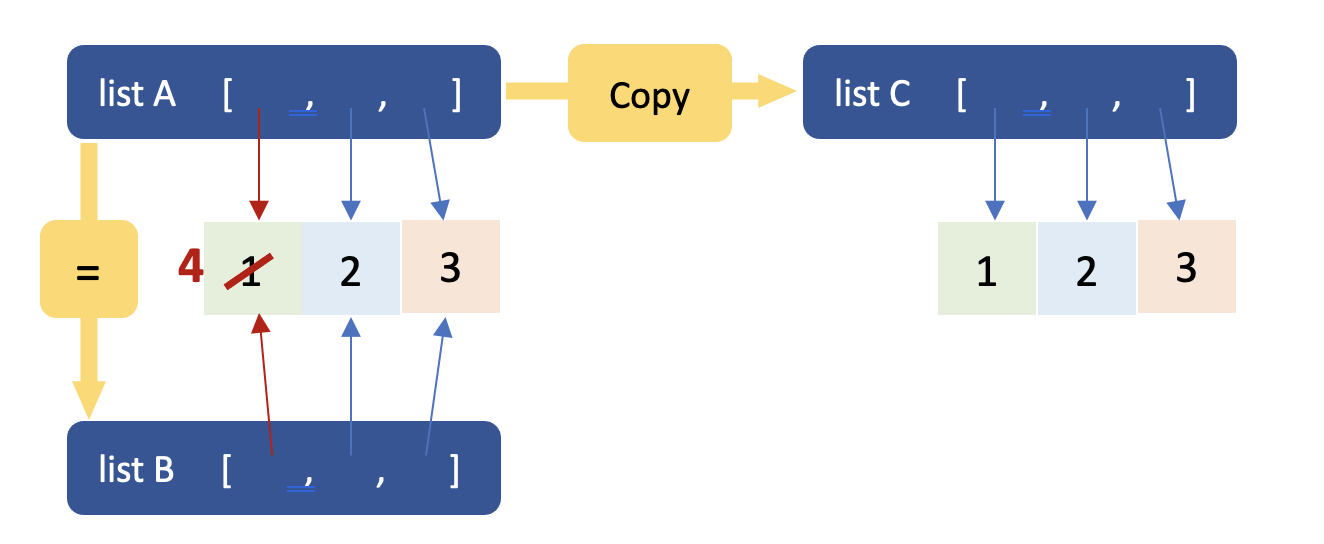
Hence, if we modify number 1 following the reference in A, we will
also change the first element in B. To copy A without the reference,
we can use the .copy method.
In the context of text cleaning, if we want to remove some words from a list, it is better to use a copy of the list as the iterable. Otherwise, the iteration and deletion would happen at the same time and create some trouble. The codes below demonstrate the issue.
# Create a list A
A = ['Alliteration','Example','Peter','Piper','picked','a','peck','of','pickled','peppers']
# Remove all words starting with P/p
for i in A:
if i.lower().startswith('p'):
A.remove(i)
print(A) # ['Alliteration', 'Example', 'Piper', 'a', 'of', 'peppers']
# 'Piper' & 'peppers' are still there because iteration and deletion happen at the same time.
# Once 'Peter' is deleted, 'Piper' takes the 3rd position.
# However, the iterator has already checked the 3rd position. So it skips 'Piper.'
# To see this, let's print each i
A = ['Alliteration','Example','Peter','Piper','picked','a','peck','of','pickled','peppers']
# Remove all words starting with P/p
for i in A:
print(i)
if i.lower().startswith('p'):
A.remove(i)
# Alliteration
# Example
# Peter
# picked
# peck
# pickled
## No 'Piper' & 'peppers'
# To solve this, we iterate through a copy of A
A = ['Alliteration','Example','Peter','Piper','picked','a','peck','of','pickled','peppers']
for i in A.copy(): # copy A
if i.lower().startswith('p'):
A.remove(i)
print(A) # ['Alliteration', 'Example', 'a', 'of']