Second Reflection - Depthseeker
Hey, crypto enthusiasts and data nerds! As we near the finish line of our project analyzing crypto market sentiment from Discord messages, it's time to pause and reflect on a journey that's been equally thrilling and humbling.
The Stopword Saga: When Removing Words Removes Meaning (by Barbie and Anson)
One technical challenge, in particular, turned into a defining moment for our team: the surprising role of stopwords in sentiment analysis using FinBERT.
It's 2 AM, empty energy drink cans everywhere, and Anson's staring at bizarre sentiment results. Bullish Bitcoin messages like "BTC is a great investment" were tagged bearish. After frantic debugging, we found the issue: our preprocessing pipeline. For word clouds, we removed stopwords like "not" and "very," which highlighted key terms well. But by feeding this cleaned data to FinBERT, we unwittingly sabotaged the model's ability to understand meaning.
FinBERT, a BERT-based model fine-tuned on financial texts. It doesn't just count "happy" or "sad" words. It leverages an attention mechanism to interpret the contextual relationships between words. This makes it incredibly powerful for financial texts, where nuance is everything. Consider these two Discord messages we encountered:
"BTC is definitely a good investment right now" (+1: Positive)
"BTC is definitely not a good investment right now" (-1: Negative)
By removing the word "not", both messages look deceptively similar—positive, even. That tiny stopword flips the entire sentiment! Our aggressive preprocessing, designed to streamline word clouds, was stripping away the context FinBERT needed to do its job. By removing stopwords, we turned "not a bad investment" into "bad investment," completely inverting the intended meaning.
This realization was a turning point. We couldn't treat all text processing as a one-size-fits-all task. Instead, we designed two distinct preprocessing pipelines:
Word Frequency Analysis Pipeline: Here, we kept our stopword removal. Stripping out "not," "very," and other common words helped us generate clean, insightful word clouds highlighting the most frequent and relevant crypto terms. This pipeline was all about reducing noise to spotlight trends.
Sentiment Analysis Pipeline: For FinBERT, we preserved the sentence structure, including every stopword. This ensured the model could capture the contextual relationships critical for accurate sentiment classification. No more accidental flips from bullish to bearish!
This methodological pivot, though seemingly small, dramatically improved our sentiment analysis accuracy. It was a humbling reminder that in NLP, especially for financial texts, the tiniest details—like a single word—can make or break your results.
Model Selection: calculate daily sentiment – 1: positive, 0: neutral, -1: negative (by Woody)
FinBERT vs finbert-tone
FinBERT is a BERT model pre-trained on financial communication texts, while the Finbert-tone model is a fine-tuned version of FinBERT, trained on 10,000 manually annotated sentences (labeled as positive, neutral, or negative) from analyst reports. We initially used the FinBERT model from https://huggingface.co/ProsusAI/finbert to analyze the sentiment of the cryptocurrency-related conversations we collected. The following graph displays the daily average sentiment score, which consistently fluctuates around -0.85, indicating an extremely bearish sentiment. This result is surprising, as we expected individual cryptocurrency investors to exhibit a neutral or bullish average sentiment.
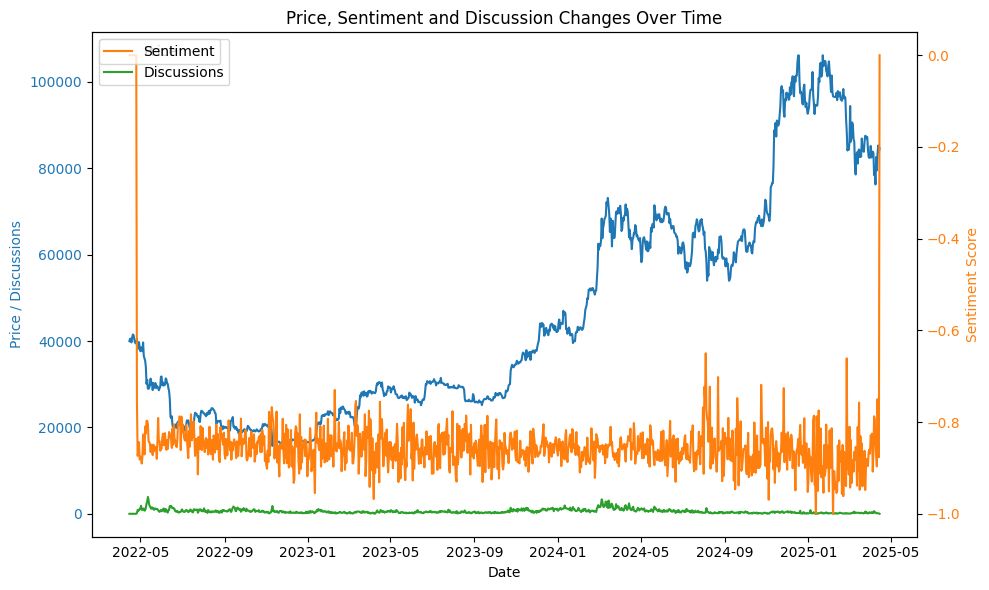
After analyzing the dataset, we identified two primary reasons for the unexpectedly bearish sentiment scores from the initial FinBERT model:
Discussions on Discord often include informal language and swear words.
A bot in the Discord channel frequently detects and flags suspicious scam messages.
These findings were confirmed by the presence of words like "sh*t" and "scam" in the word cloud generated from the data.
We then evaluated the FinBERT-tone model from https://huggingface.co/yiyanghkust/finbert-tone to analyze the sentiment of the collected cryptocurrency-related conversations. As shown in the following graph, the daily average sentiment score fluctuates between 0 and 0.1, indicating a predominantly neutral sentiment. This aligns with our expectations, as individual investors often engage in neutral discussions, including casual chatter, greetings, and noise. Additionally, using the FinBERT-tone model, we observed a moderate positive correlation (0.4785) between BTC prices and daily sentiment scores.
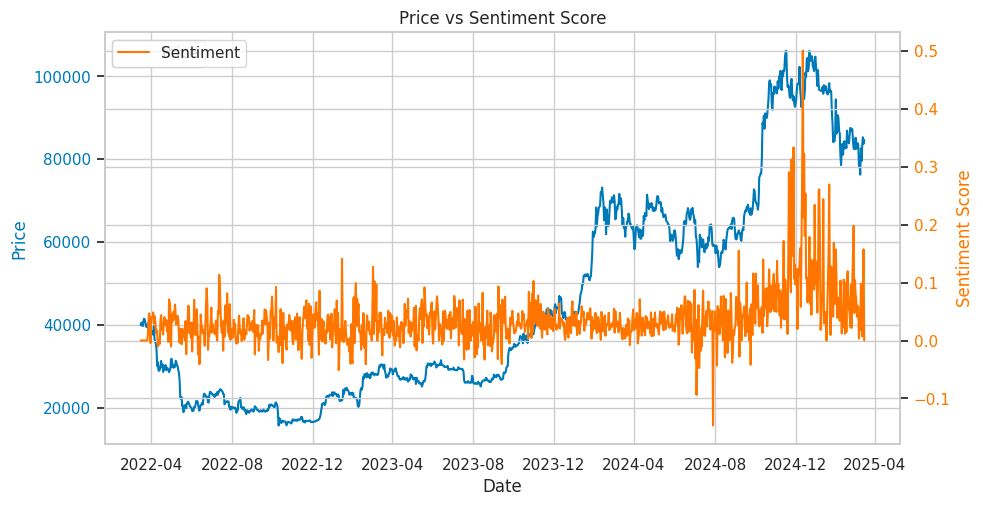
Given that the FinBERT-tone model provides more meaningful sentiment interpretations and demonstrates superior performance in financial tone analysis, we decided to adopt it for subsequent analyses.
Correlation Matrix: Unpacking Relationships
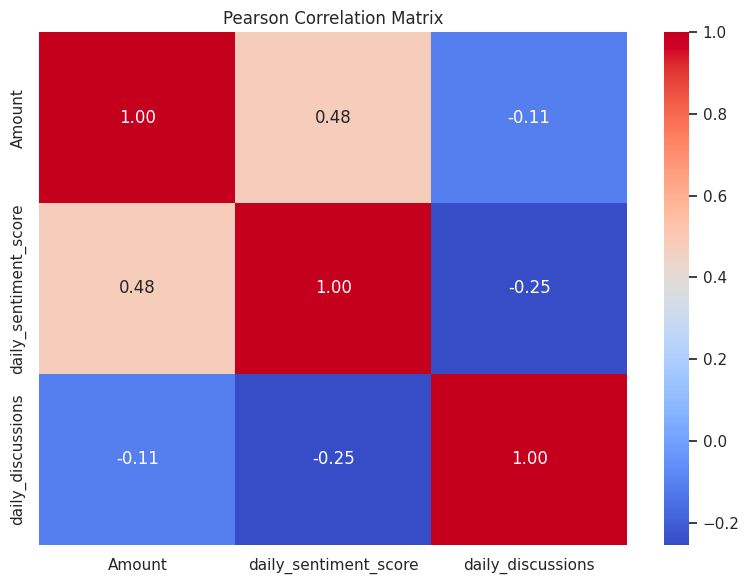
The correlation matrix examined three variables: “Amount” (Daily BTC/USD price), “daily_sentiment_score” (average of sentiment score daily), and “daily_discussions” (conversation volume daily). Key findings:
Medium-Positive Correlation: “Amount” and “daily_sentiment_score” showed a correlation coefficient of 0.48, indicating a potential correlated relationship between daily sentiment and price of Bitcoin.
Weak Correlations: “daily_discussions” had a weak-negative correlation with both “Amount” (-0.11) and “daily_sentiment_score” (-0.25). This suggests the discussion volume is unlikely to be correlated with BTC/USD nor daily sentiment.
LSTM Analysis: making price predictions (by Woody, Barbie, Anson)
LSTM Price Prediction (Historical Price only): Capturing Historical Trends
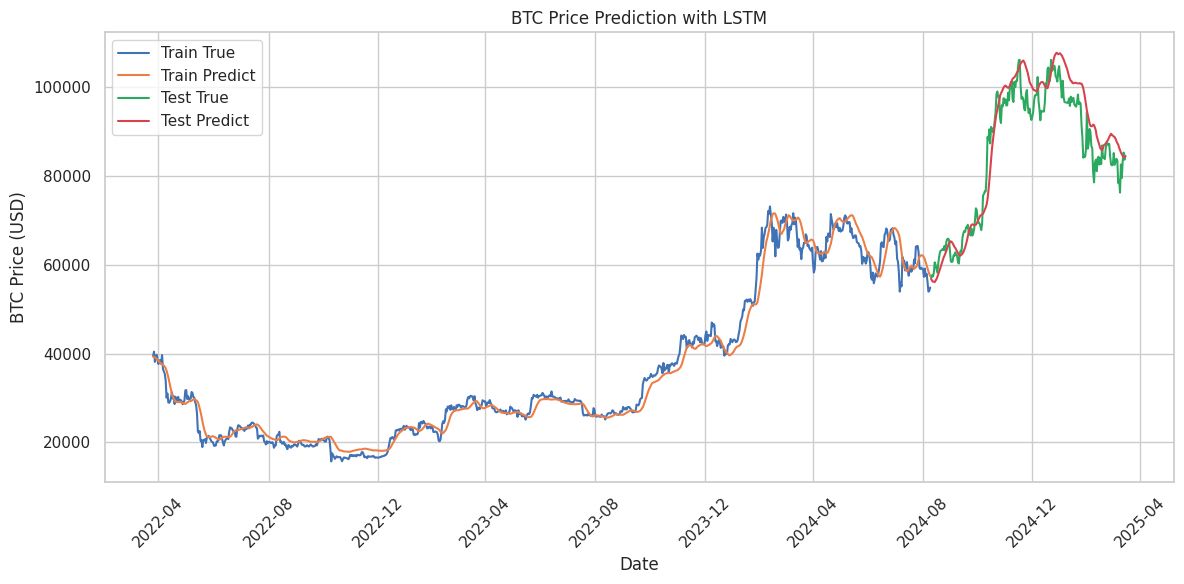
The LSTM prediction graph split BTC price predictions into training and testing phases:
Training Accuracy: The model closely followed historical price patterns. (Test_MAPE: 8.75%)
Testing Performance: It tracked true values reasonably well but struggled with sharp peaks, like the 2024 surge, underestimating price jumps.
The LSTM model effectively captures historical trends, but upon closer inspection, it exhibits a lagging effect in its predicted price movements. The model tends to predict today’s price based heavily on the closing price of the previous trading day. This observation highlights that predictive models require more than just historical data to achieve robust performance.
Enhanced LSTM (Historical Price + Sentiment + Discussion): Sharpening Predictions
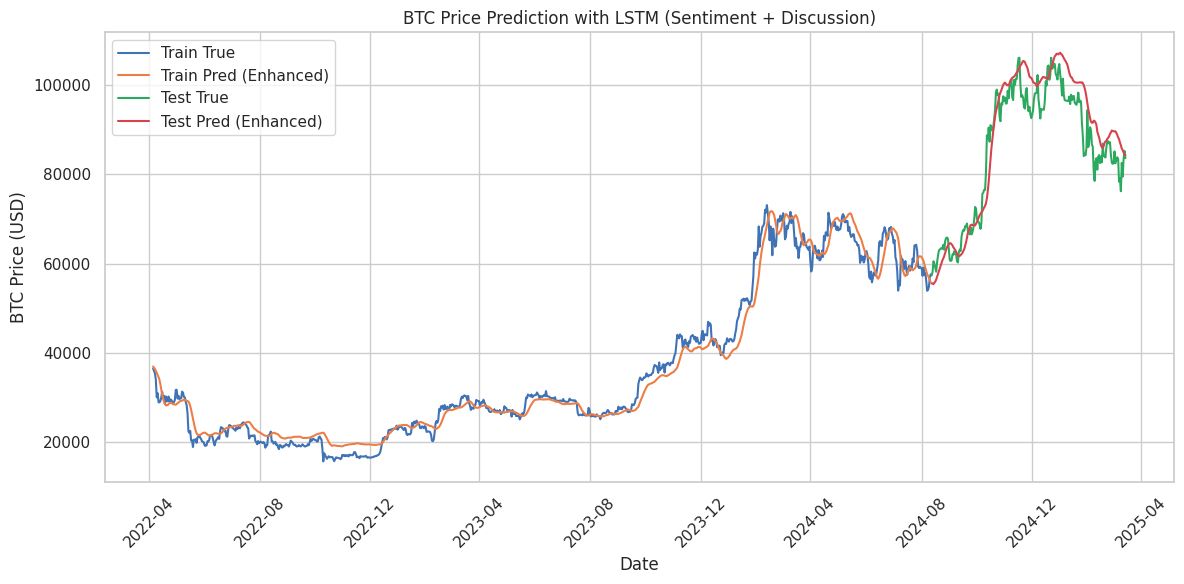
Incorporating sentiment and discussion volume improved predictions:
Slightly Improved Alignment: The enhanced model captured trends better, though it still underestimated peaks and troughs. (Test_MAPE: 5.09%)
Sentiment and Discussion Impact: These features added valuable context for price prediction.
This analysis confirmed our hypothesis that incorporating sentiment and discussion data enhances predictive power (reduced test MAPE). However, upon closer examination of the predicted price movements, the model still exhibits a lagging effect.
Broader Lessons and Reflections
The modest correlations and improved LSTM performance demonstrated that while sentiment and discussion metrics add value, they aren't definitive predictors—cryptocurrency volatility frequently results from external factors such as news events or regulatory changes.
Through debugging sessions, we learned to challenge assumptions, enhance preprocessing techniques, and combine multiple data streams. The improved LSTM results highlighted the effectiveness of integrating sentiment and discussion metrics, though persistent prediction gaps reminded us of cryptocurrency's inherent unpredictability. As we conclude this blog series, we recognize that exploring real-time external data to supplement our models would be the next logical step in seeking better foresight in this volatile market. More comprehensive insights from our research will be included in our final report.