Introduction
In our first blog post, we will provide an introduction to our project and offer some insights into our preliminary data collection process.
The aim of our project is to discover the relationship between ESG (Environmental, social, and governance) news coverage and the volatility of companies. We aim to look at different sources, such as major news providers or social media like Twitter, focusing on ESG-related keywords to conduct sentiment analysis to see whether the frequency of mentions affects the volatility of companies. For example, companies that have a higher frequency of negative ESG-related news may portray higher price volatility in the market. Ultimately, we aim to see the level of significance of ESG news in stock prices.
We came up with this idea because of the growing acknowledgment of ESG factors in business and investment decisions today, and the impact of news on shaping investors’ behaviour in the market. Recently, there has been a surge of news on governance issues of Kakao Corp., one of the prominent growth stocks in Korea. Allegations of stock price manipulation and embezzlement have surfaced, leading to an immediate decline in Kakao's stock price. This example has sparked our motivation to delve deeper into the connection between ESG sentiment scores and their influence on investors and eventually, stock prices.
Literature Review
Here are some articles we referenced.
The Effect of ESG performance on the stock market during the COVID-19 Pandemic — Evidence from Japan
The methodology section of the article details the use of a firm fixed effects panel model to examine the impact of ESG (environmental, social, and governance) on the returns, volatility, and liquidity of the stocks of more than 300 listed companies in Japan. The study utilizes ESG scores from FTSE Russell and Standard & Poor's to fully assess ESG performance. The article provided us with a methodology on how to establish the link between ESG performance and company stock performance.
Trading Sentiment: NLP & Sentiment Scoring the Spot Copper Market
The main objective of the article is to analyze the sentiment behind each tweet and its correlation with the spot price of copper over the past five years from historical tweets posted by financial news publishers on Twitter by using natural language processing. Techniques include data acquisition using GetOldTweets3, Exploratory Data Analysis (EDA), text preprocessing using Stopwords, tokenization, n-grams, Stemming & lemmatization, using GenSim and NLTK PyLDAvis, through Latent Dirichlet Allocation (LDA) model to analyze the data, and sentiment scoring using VADER. The article provides us with information regarding how to extract the data and how to preprocess the text. It also reminds us about the importance of data validation, as data may be lost or valuable data may not be included in the preprocessing process due to improper use of methods.
ESG performance, herding behavior and stock market returns: evidence from Europe
This research explores the dynamics between ESG performance, investor herding, and stock market outcomes in Europe, analyzing data from large-cap companies across six nations from 2010 to 2020. It assesses how ESG scores and financial metrics like market size, price-to-book value, and the Sharpe ratio influence stock behaviour. The study leverages panel data methodology and sources its ESG information from the Refinitiv Eikon database, offering insights into the financial effects of ESG practices and collective investment patterns in the European markets.
The study discusses a framework that employs artificial intelligence for the analysis of ESG data, underscoring its pivotal role in making well-informed investment decisions, particularly highlighted by the COVID-19 crisis. It explores the application of machine learning and deep learning algorithms to enhance the precision in forecasting companies' ESG performance indicators, such as focusing on governance and social datasets through NLP algorithms. Through various experiments and methods, the research focuses on improving the predictability of ESG scores and the importance of safeguarding ESG data against potential security threats.
Data Collection
To perform an analysis of the relationship between ESG news and stock volatility, raw news data is required. We demonstrated a test on news data collection via web scraping.
We tried to scrape the news heading from FinViz (a stock screening website). First, we download the HTML for the specific stock and get the news table via requests and BeautifulSoup.
def get_news_table(symbol):
url = f'https://finviz.com/quote.ashx?t={symbol}'
headers = {'User-Agent': 'my-app'}
response = requests.get(url, timeout=3, headers=headers)
html = BeautifulSoup(response.text, 'lxml')
news_table = html.find(id='news-table')
return news_table
Then, we parse it into a data frame with three columns [‘heading’, ‘datetime’, ‘source’].
def parse_news_table(table):
if table is None:
return None
def map_date(time):
pattern = r'[A-Z][a-z]+-\d+-\d+'
result = re.match(pattern,time)
if result is None:
return np.nan
else:
return result[0]
def map_time(time):
pattern = r'\d+:\d+[A-Z]M'
result = re.search(pattern,time)
if result is None:
return np.nan
else:
return result[0]
def map_source(heading):
pattern = r'\(.*\)$'
result = re.search(pattern,heading)
if result is None:
return np.nan
else:
return result[0].replace('(','').replace(')','')
def map_heading(r):
heading = r['heading']
source = r['source']
return heading.replace(f' ({source})','')
df = pd.read_html(str(table))[0]
df.columns = ['time','heading']
df['date'] = df.time.map(map_date).ffill()
df['time'] = df.time.map(map_time)
df['datetime'] = pd.DatetimeIndex(df.date + ' ' + df.time)
df['source'] = df.heading.map(map_source)
df['heading'] = df.apply(map_heading,axis=1)
The format of the output DataFrame is shown below.
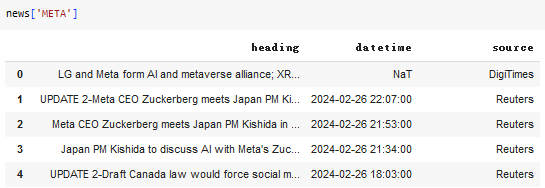
With a for loop, we can scrap the news headings stock-by-stock and save them into a dict indicated with the stock symbol.
symbols = ['AAPL','MSFT','AMZN','GOOGL','META','NFLX','TSLA']
news = dict()
for symbol in symbols:
table = get_news_table(symbol)
df = parse_news_table(table)
news[symbol] = df
This method allows us to collect data from nearly all well-structured HTML such as SeekingAlpha, Yahoo!News, etc. Yet, this will yield too much unnecessary information for the purpose of collecting ESG news, since it scrapes all available news presented on the website without any filtering. One possible solution may be clustering the news data by topic and letting the machine learning algorithms decide what ESG news is, but the work will require a fair amount of time and resources. Therefore, it may be better to filter the ESG news before collecting the data. For example, we may use the search engine or existing libraries to filter the news. In turn, this means we need to use some predefined ESG keywords to perform the search.
Reflection
In our project, we faced significant data collection and analysis challenges. One of the main issues is the sheer volume of data available on news sites and social media platforms related to ESG topics mentioned about companies. The sheer volume of information poses potential problems for data collection, storage, processing, and analysis, so we must improve our data collection methods and focus on the most relevant information. Additionally, changes in social media platforms (e.g., Twitter changed to the X) created problems with data access and the potential for outdated or incomplete datasets. These updates require us to make timely adjustments to our data collection strategy to ensure continued access to up-to-date, comprehensive data. In reflecting on these challenges, we recognize the need to be flexible and innovative in our approach to data collection and analysis, which has allowed us to effectively overcome these barriers.
Currently, we have identified another challenge that we need to address, which is how to determine if a news article or social media text contains ESG-related content. This is important to ensure that the data we collect for the program is useful. In the previous literature review, one of the studies used the FTSE Russell's ESG Scores and data model, which gives us a well-established catalogue of keywords. For example, for the environment component in ESG, we can look for keywords like “Biodiversity,” “Climate Change,” and “Pollution & Resources.” We are working towards writing code for this section step by step.