Main Contributer for this blog: Jason Li
Web Scraping Review
Based on a little web scraping experience in the past in other courses and projects, we believe web scraping is a bit like a data exploration task, which is to locate patterns in the tags of the information we need and try to put everything into a loop. For this time, we still need to locate such patterns, with a lot more other factors/issues to be considered.
Compared to our previous experience in web scraping, web scraping on Factiva is a much less static task. For starters, we can not directly access the Factiva platform with a hyperlink, otherwise we would be redirected to a login page which we do not have the credentials to login. Thus, we have to start from the HKU library page step-by-step, login through the library page with our HKU library credentials to finally enter the familiar query page.

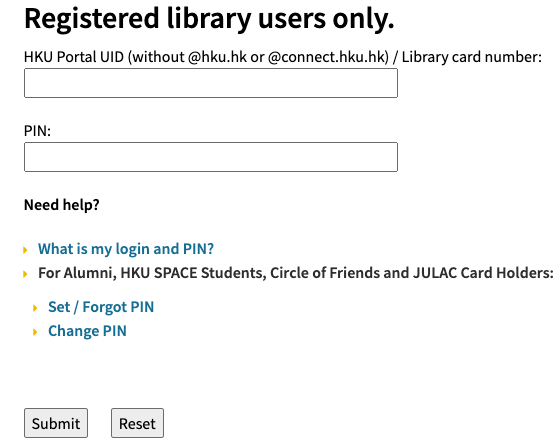
Enter the Page
Upon entering this page, there are plenty of options to be toggled or adjusted to query the relevant articles that we would like, which took us quite a while as there are various types of actions to be done:
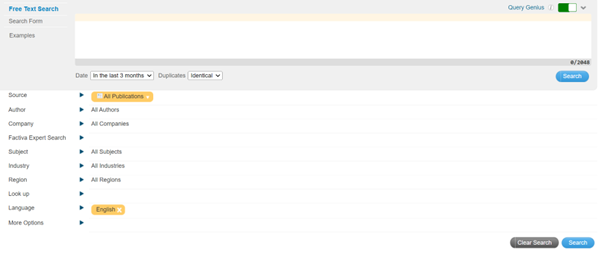
- Free Text Input


- Dropdown menu selection

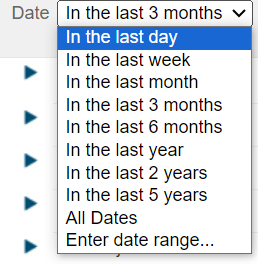
- Search and select

Small Bugs to pay attention to
1
There are plenty of hiccups throughout the process of interacting with this query page. Sometimes the pages took too long to load, causing timeout exceptions and sometimes we accidentally intervened with my mouse and the search bar does not return an option for us to select. On very rare occasions, the page is not properly loaded and is displayed in a html format or the html tags mysteriously change slightly to throw us a curveball. Considering we would like to scrape articles from each month across 10 years, this process has to be repeated 120 times and the myriad of errors has been rather frustrating. However, this is part of web scraping, trial-and-error to ensure the robustness of the code.

2
The search result page is rather standard with a clear ‘row-by-row’ structure. Considering the limitations of the HKU license, it would be preferred to not use automation software to download these articles directly. To work around this, the program clicks into these articles one by one and scrapes the headlines and the bodies of these articles, then goes back to the previous search result page. However, these articles come in different structures and formats, with different numbers of paragraphs, and sometimes with photos or tables in between. Unfortunately, we have attempted different methods to no avail, which can only leave the task of cleaning these texts to the preprocessing afterwards.

3
Looping through these articles presents some issues as well. For instance, the server would return a gateway error, which is rare but rather unfixable. On the other hand, it is quite common that during the process of going back to the search result page, the page would somehow go all the way back to the query page. The tricky part is that the query is partially deleted i.e. data sources reset and the html tags would differ slightly, which takes extra effort to handle and not disrupt the scraping. Eventually, the run took about 8-9 hours to complete.

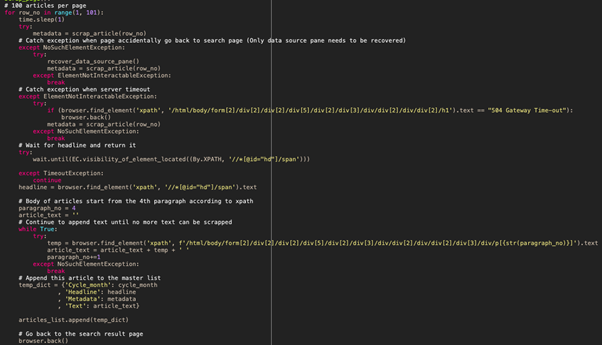
Final remark from the main contributor of this part
After completing the task, we find web scraping a rather unglamorous, slightly frustrating but rewarding experience, more so compared to my previous encounters with web scraping. In reports or presentations, data collection is often briefly skimmed through, but is certainly a crucial part of any project.