By Group "Simplicity," written by Pail HUNG Pui Kit
Project Introduction
Here at Group Simplicity, we are working together to investigate the correlation between the sentiment expressed on Reddit's r/wallstreetbets community and stock market performance. Given the enormous scope of the posts, we will restrict ourselves to only look at posts after certain market shocks to evaluate whether market shocks would affect the correlation. We will look at the submission data's title, content, and the most popular comment. Additionally, we will be identifying the stock mentioned in the post, running VADER sentiment analysis on it, and then visualizing the correlation.
Project Overview
Step 1: Data Sourcing Reddit Posts by Pail
Step 2: Cleaning Data and Identifying Stock by Hang
Step 3: Performing Sentiment Analysis by Dev
Step 4: Visualizing Correlation and Prediction by Sean
Other colleagues will make an introduction in their respective blogs.
Author Introduction
Pail, Hung Pui Kit, a second-year Economics and Finance student, in charge of the data collecting and storage portion of our group project.
Step 1 : Decide the workflow and search for codes
This project begins with scraping Reddit's data, therefore making the first step figuring out how to scrape the raw data, arranging it in a tabular data frame, and exporting it as a .csv file for further processing by other colleagues.
The first step of scraping data from Reddit's API using the PRAW library is done with the following basic code:
import praw
import pandas as pd
reddit = praw.Reddit(
client_id="my client id",
client_secret="my client secret",
user_agent="my user agent"
)
subreddit = reddit.subreddit("wallstreetbets")
# Create an empty list
posts = []
for submission in subreddit.hot(limit=None):
# Output: the submission's title
print(submission.title)
# Output: the submission's score
print(submission.score)
# Output: the submission's ID
print(submission.id)
# Output: the submission's URL
print(submission.url)
# Add the aforementioned attributes into the list
posts.append([submission.title, submission.score,
submission.id, submission.url])
posts_df = pd.DataFrame(posts,columns=[‘title’, ‘score’, ‘id’, ‘url’])
With these few lines, I have successfully done the following tasks:
- Gain access to Reddit Post Data via API
- Scrape the relevant attributes of the posts
However, there are certain limitations, such as the fact that I can only gather the most popular entries, with a limit of roughly 300 submissions, which is insufficient to construct a data pool for further research.
Step 2: Find ways to collect posts within a specific time range
The next part has the following code:
# Assuming you have a praw.Reddit instance bound to the variable `reddit`
# "39zje0" is simply the submission ID of a particular post
submission = reddit.submission("39zje0")
print(submission.title)
I can find the required submissions using the submission ID, so looking for a way to scrape the submission ID first in a certain timeframe should be the next step. Because using the PRAW library alone was not enough to acquire data, I spent some hours browsing. I found that the PSAW library, another library which uses the PushShift API, is specifically used for locating IDs within a certain timerange.
That's exactly what I needed, so I referred to its documentation and obtained the following:
import praw
from psaw import PushshiftAPI
import datetime as dt
reddit = praw.Reddit(...)
api = PushshiftAPI(reddit)
# scrape from when
start_epoch=int(dt.datetime(2017, 1, 1).timestamp())
list(api.search_submissions(after=start_epoch,
subreddit='politics',
filter=['url','author', 'title', 'subreddit'], # scrape which columns
limit=10)) # scrape how many posts
From the above reference, we can observe the existence of the timerange variables, which can help specify the required start and end points of scraping. The "filter" variable enables one to specify what attributes of the posts one wants to scrape, but since I only want the submission ID, I can get rid of it. However, there is one minor issue that I came across which is when limit='None'. It tells the code to scrape all the posts without any limits. The code will run slowly and sometimes even fail to generate any results, so I modified the code by adding the "score" variable which allows me to only scrape the submission IDs of posts that have more than 1 upvote. The code is as follows:
import praw
from psaw import PushshiftAPI
import datetime as dt
reddit = praw.Reddit(...)
api = PushshiftAPI(reddit)
# scrape from when until when (2021-11-1 to 2021-11-30 in this case)
start_epoch=int(dt.datetime(2021, 11, 1).timestamp())
end_epoch=int(dt.datetime(2021, 11, 30).timestamp())
submissions_generator = api.search_submissions(after=start_epoch,
before=end_epoch,
subreddit='wallstreetbets',
limit= None,
score = ">1"
)
submissions = list(submissions_generator)
With these lines, the submission IDs will be gathered into a list, and I will be able to scrape the details later using the PRAW library.
Progress Done:
-
Ways to collect required submission IDs: Found
-
Ways to scrape submission details found
Step 3: To collect more data: the comments
Aside from the contents of the post, the comments are also significant since it provides a lot of useful text that can assist my colleagues. When evaluating individual posts, we discovered that the most popular comment can often be in the form of an image.
Returning to the PRAW documentation, the following code was discovered:
from praw.models import MoreComments
for top_level_comment in submission.comments:
if isinstance(top_level_comment, MoreComments):
continue
print(top_level_comment.body)
While running this you will most likely encounter the exception
AttributeError: 'MoreComments' object has no attribute 'body'. This submission’s comment forest contains a number ofMoreCommentsobjects. These objects represent the “load more comments”, and “continue this thread” links encountered on the website. While we could ignoreMoreCommentsin our code
It appears that I need to deal with the 'MoreComments' object, which represents sub-comments or comments of a comment, based on this explanation. I am not familiar with it, so based on the example code, I will choose to ignore it if I come across it.
I started to think about the layers of collecting the posts and comments data:
-
I have a lot of submission IDs.
-
I have a lot of comments under each submissions.
I divided the collections into two DataFrames, one for post information and the other for comment details, and then merged them based on submission ID.
Since a post has identical identifiers like the submission ID, submission content, or submission topic (the right dataframe here), but it can also have an unlimited number of comments (the left dataframe), I will need to merge them later by "broadcasting" the post data to merge with the comment data based on the post ID (key column) to keep all the data in the same dataframe. "Broadcasting" is a special type of merging, which ensures that the final DataFrame retains its shape. This is depicted in the figure below.
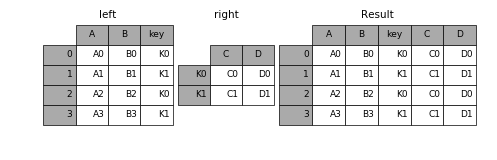
So I wrote the following lines:
# 2. Use the PRAW library to scrape post details
posts = []
count = 0
comments_list = []
for submission_id in submissions:
post = reddit.submission(id=submission_id)
post_items = []
comments_details = []
# Scrape Comments
for top_level_comment in post.comments:
if isinstance(top_level_comment, MoreComments):
comments_list.append(['no id',
'no author',
-100,
'no comment',
post.id])
continue
comments_list.append(['no id',
'no author',
-100,
'no comment',
post.id])
comments_list.append([top_level_comment.id,
top_level_comment.author,
top_level_comment.score,
top_level_comment.body,
post.id])
# Scrape other post details
post_items.extend([post.id, post.created_utc, post.author, post.score,
post.num_crossposts, post.num_comments, post.upvote_ratio,
post.title, post.selftext, post.url, post.permalink])
posts.append(post_items)
count += 1
# Transform post details to a main DataFrame
posts = pd.DataFrame(posts, columns=['id', 'time', 'author', 'upvotes',
'num_crossposts', 'num_comments', 'upvote_ratio',
'title', 'content', 'url', 'permalink'])
# Transform comments details to another DataFrame
comments_df = pd.DataFrame(comments_list, columns=['comment_id',
'comment_author',
'comment_upvote',
'comment_content',
'id'])
# Transfer Unix Time format to standard datetime format
posts['date'] = pd.to_datetime(posts['time'], utc=True, unit='s')
posts.pop('time')
# A new column to indicate whether the post maybe contains media by comparing URL and permalink
posts['no_media']=posts['url'].str.contains('/r/wallstreetbets',regex=False)
# Merge comments and main post details DataFrame
posts = posts.merge(comments_df, how='left', on='id')
# Reindex the DataFrame
posts = posts.reindex(columns=['id', 'date', 'author', 'upvotes', 'no_media',
'num_crossposts', 'num_comments', 'upvote_ratio',
'comment_id','comment_author','comment_upvote','comment_content',
'title', 'content', 'url', 'permalink'])
To avoid errors, I added a 'fake' entry to the comment DataFrame for every post, regardless of whether 'MoreComments' displays or not. The 'fake' entries may be readily removed afterwards due to their identical characteristics.
Up to here, the data scraping process is nearly done, with the following tasks completed:
-
Collect the required submission IDs
-
Use the IDs to scrape post details
-
Use the IDs to scrape the comments details
-
Merge the two dataframes
Step 5: Export and Data Pre-processing
Now that I have scraped all of the posts inside a specified timeframe, it is time to export the dataframe to a .csv file and distribute it to my colleagues. There will be two versions available: one with all the data and one with only the posts with more than 5 upvotes and the highest upvoted comments.
Also, in order to simplify the handling of files, I set the export name to be linked to the timeframe I collected.
base_path = '*the export folder path*'
# Export to CSV File
export_name = 'Reddit WSB Data with all comments ' + from_date + ' to ' + to_date + '.csv'
print('Export name: ', export_name)
posts.to_csv(os.path.join(base_path, export_name), index=False)
print('export complete')
# Modify the file
export_name = 'Reddit WSB Data with all comments ' + from_date + ' to ' + to_date + '.csv'
posts = pd.read_csv(base_path + os.sep + export_name)
posts_mod['upvotes'] = posts_mod['upvotes'].astype(int)
# Keep comments with highest upvote only
posts_mod['comment_upvote'] = posts_mod['comment_upvote'].fillna(-100).astype(int)
posts_mod = posts_mod.sort_values(by=['comment_upvote'], ascending=False).reset_index(drop=True)
posts_mod = posts_mod.drop_duplicates(subset=['id'],keep='first')
# Keep posts with upvote >=5
posts_mod = posts_mod[posts_mod['upvotes'] >=5 ]
# Export
posts_mod = posts_mod.sort_values(by=['date'], ascending=True).reset_index(drop=True)
mod_name = 'Reddit WSB Data with most upvote comments ' + from_date + ' to ' + to_date + '.csv'
posts_mod.to_csv(os.path.join(base_path, mod_name), index=False)
Extra Step: Let the code run remotely
Because of the extensive time needed to scrape Reddit submissions owing to Reddit's API connection limit, I installed a docker image on another machine so that the program could be executed remotely. Also, I wrote a function 'time report()' to determine how much time has passed. Furthermore, in my scripts, the essential variables that need to be altered when the codes are run locally and remotely are clearly visible and modifiable.
start_time = dt.datetime.now()
def time_report():
current_time = dt.datetime.now()
print('Time spent now: ', current_time - start_time)
return
# Key Variables #
base_path = '*the export folder path*'
start_scrape = dt.datetime(2021, 1, 1)
end_scrape = dt.datetime(2021, 12, 31)
One more thing: metadata on writing a pelican post
Title: Project Introduction and Step 1: Data Collecting and Storage
Date: 2022-03-29 10:20
Category: Progress Report
In order for pelican to recognize this markdown file, the metadata should begin on the first line of the markdown file. I spent quite a lot of time doing a trial and error process to identify this issue.
Final: Feelings and Further Improvements
The slow API that extracts the post ID was basically my biggest opponent while I was developing my program. It took me around 8.5 hours to gather 83000 submission IDs, and 2 days and 7 hours to collect all of the data in total. As a result, each time I edited the code and evaluated the produced data, I had to wait a long time.
Returning to the code, it took 90-100 lines to complete the task, which I believe is acceptable. Although my coding style is a little wordy, with transition variables that are only used once, it made it easier for me to understand what I had written after a day, and the nature of scraping data does not emphasize the script's operation speed, which was limited by the API already.
Improvements
I did not use the APRAW library, which is the async version of the PRAW library that can scrape the Reddit post details much faster. The reason being that I am not familiar with the async and await functions. In addition, the slowest part, collecting post IDs, is handled by the PSAW library which is dependent on the PRAW library, the APRAW library can only be used in collecting the details of each post, which I believe will result in only a slight improvement in efficiency.
Finally, thank you for reading :>
Link to code can be found here: reddit_data_scraping