By Group "Semantic Analysts," written by Prateek Kher
Background
Data Scientist Beware! This blog post may seem a bit boring, filled with mostly textual information, no pictures and code, but there is a reason behind it, text which may seem boring for a layman, may have a lot hidden underneath it (why don’t you try to conduct semantic analysis of this article and see for the results yourself!). I want to give a brief introduction to our project, and dive into the code and pictures in the coming few blogs.
I am Prateek Kher, from group Semantic Analysts, and we have decided to complete our project on Financial Fraud Detection Using Text Analytics and Natural Language Processing. Before we straight away dive into the coding aspect of it, I want to specify why we decided to choose this specific topic.
Coming from a mixed background of Finance and Tech, I personally thought that the current industry practices of fraud detection, though evolving at a very high speed, have room for improvement. I strongly believe in technology playing a huge role in finance in the future too, and seeing the impact of Web3 in the world of finance, I thought it best to leverage the use of modern technologies and skills in order to detect fraud! Being a FinTech major, I believed this was a perfect opportunity for me to leverage my skills and interest in the field of technology and finance, therefore I decided to go forward with the idea of selecting the topic of detecting fraud using text analytics and natural language processing.
I strongly believe in creating value leveraging modern technology in the world, and I believe this is a good opportunity for me to bring about a change in the way fraud is detected.
What are we doing?
Our group primarily, wants to focus on detecting fraud using a text analytic approach. What does that mean? We know traditionally detecting fraudulent companies has been a cumbersome task, filled with tons of numbers, and purely quantitative analysis, going through paperwork, and just analysing numbers! We thought this a good opportunity to leverage the skills, and try detecting fraud using the qualitative data available (through other sources), and try a text-mining approach! We know that financial statements are a depiction of a company's financial situation. Fraudulent financial statements not only cause huge losses to potential stakeholders, but they also weaken investor confidence in the capital market. To uncover probable fraud, current auditing techniques rely mainly on quantitative measurements such as financial ratios. However, there is a scarcity of study and analysis on using textual analysis to detect financial fraud. Furthermore, underlying information such as auditor's comments or notes is largely ignored in quantitative financial statement examination. As a result, our project proposes many text mining algorithms for processing the textual information found in financial statements in the hopes of detecting fraud.
Therefore, in this project, we aim to detect fraudulent companies by analysing the MD&A sections of this companies from their 10-k filings. We aim to extract the data using a state-of-the-art SEC API, which contains both, query API, and extractor API, and then further process the HTML content to convert it into raw text which will help us analyse the data. We will be using SEC EDGAR database, coupled with a database released by University of California Berkeley, which contains details of companies which have been issued an AAER.
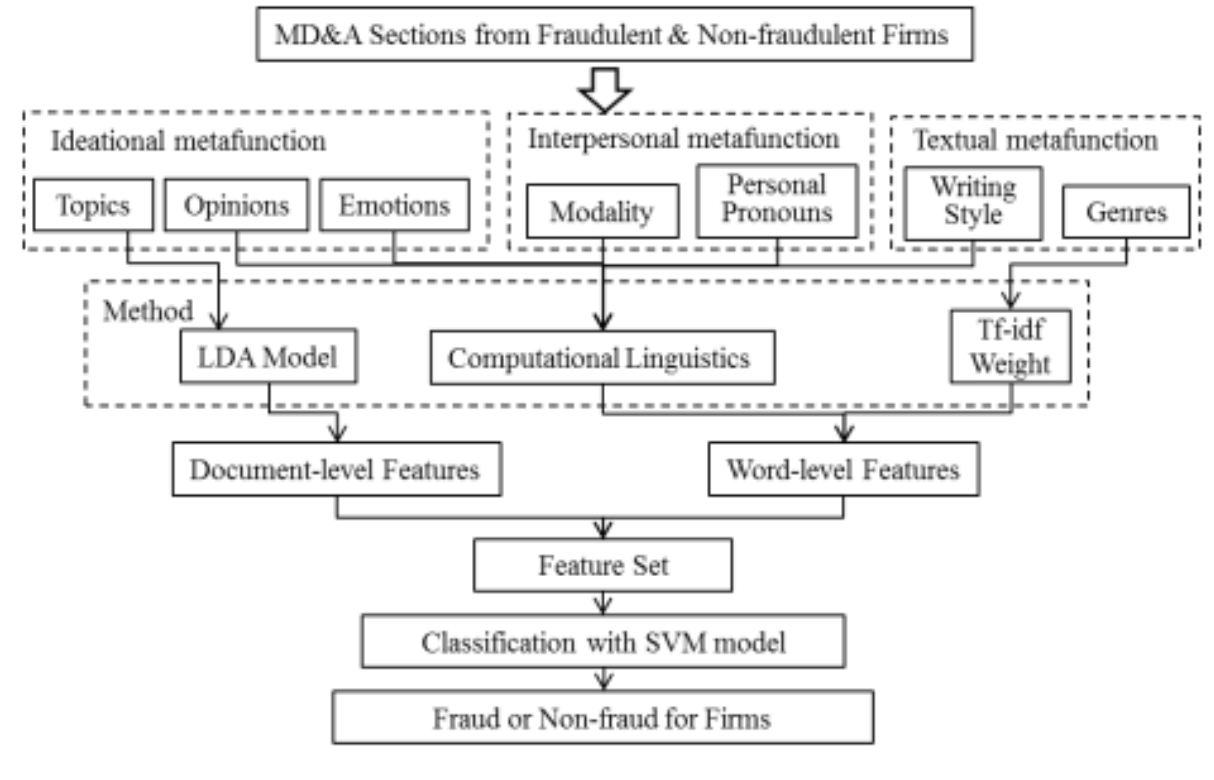
This will help us retrieve all the relevant data, and move to the process of data cleaning, exploratory data analysis, and visualisation. Before we started the project, we knew we will encounter all sorts of problems, ranging from gathering quality and trusted data, to cleaning and analysing the large dataset. In the analysis, we will run some machine learning models like Naive Bayes, Support Vector Machine, and Logistic Regression, which will make use of feature extraction techniques such as SFL, LDA, Bag of Words, TF-IDF, etc. I will talk about all such issues, share my findings, and also the procedure with which I came to the conclusions of the project. Finally, the picture below shows a brief model of what our group aims to achieve. It contains a simple flow chart depicting what we want to do! More details to follow in more blog posts!