By Group "Semantic Analysts," written by Prateek Kher
Introduction
Hello data scientists! This blog post will be my final post in a series of posts regarding my journey of trying to detect fraudulent companies using NLP and Text Analytics. This blog post will not be long, and I will briefly cover the results afterwards.
Post-Cleaning
After cleaning the data, as depicted in previous blog posts, we had to conduct some feature engineering and train the data. As the code below shows, we split the data into training and test by 70 percent and 30 percent respectively.
X = df[['MDA','WPS', 'fog_index', 'other_ref',
'self_ref', 'group_ref', 'emo_pos', 'emo_neg', 'emo_anx', 'emo_anger',
'emo_sad', 'punc_ratio', 'avg_word_len', 'log_length', 'LDA',
'positive', 'negative', 'uncertain', 'litigious', 'strong_modal',
'weak_modal', 'constraining', 'complexity']]
y = df["isFraud"]
x_train, x_test, y_train, y_test = train_test_split(X, y, stratify=y,test_size=0.3, random_state = 42)
We conducted feature engineering using SFL, Bag of Words, Word2Vec, etc. so that the data that we will parse into our models is comprehensive. We found that largely Word2Vec does not improve accuracy, and we should stick to Bag of Words and TF-IDF.
Models Used
For starters, we used various models in order to train our dataset. We used Linear Support Vector Machine, Logistic Regression and Naive Bayes.
After passing the data to the models, we received the following results.
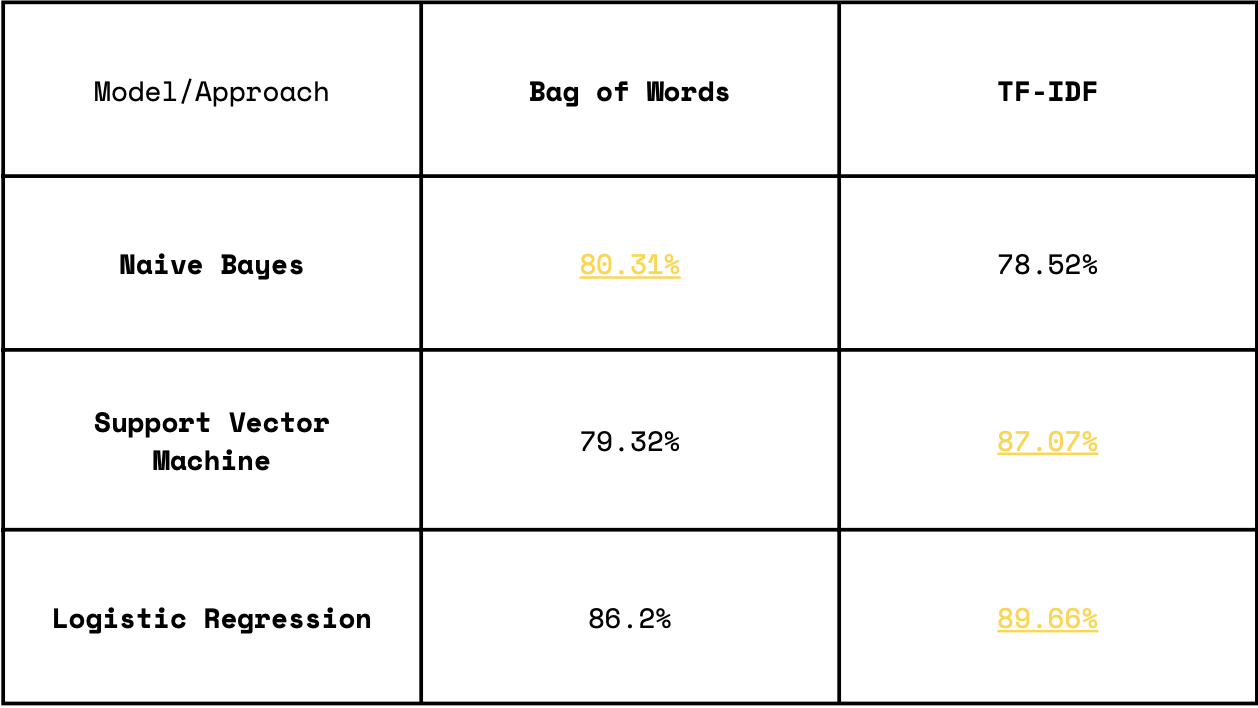
The results look great, but not up to the mark! We reached accuracies up to 89 percent, but we wanted more! Inherently, I believe in pushing my boundaries, and I thought why not do the same here too. The table below shows a glimpse of what our results were after we optimised our model using GridSearchCV!

The results after conducting hyperparameter optimisation are phenomenal. We have already reached a high accuracy of 92 percent, but aim to go even higher, about which we will talk in the future work.
Limitations, Difficulties, and Future Work: Hindsight is Very Important!
Working with the datasets presented a number of issues. To begin with, the phrasing on financial statements is ambiguous, which has proven to be a hurdle to obtaining accurate data. Clean data is information that is suitable for processing and testing against a machine learning model. It's been challenging to come up with a general technique to extracting and cleaning the records because different financial statements have different patterns. To deal with this, stopwords, special characters, and symbols were removed, as well as lemmatization, using NLTK and other NLP tools.
In most machine learning and deep learning implementations, many implementations can be used for guidance. Unfortunately, most fraud classifiers use financial data to detect fraudulent scenarios, as mentioned in previous sections. As a result, finding a suitable text mining method has proven to be incredibly challenging. Examining projects that use similar text extraction and text mining techniques can assist in overcoming this obstacle. Referencing a number of study publications can also assist you in determining the ideal methods to use.
However, the beautiful part of Computer Science and working together is solving these problems together! We successfully overcame these challenges, and are now ready to embrace for future work.
Although our dataset and training models offer us with excellent levels of accuracy, the models could be improved in the future. Below are two examples of NLP applications that could dramatically enhance the accuracy score. The Harris Hawks Optimization algorithm and Deer Hunting Optimization (DHO)-based classification utilizing Deep Neural Networks (DNN) are two relatively contemporary algorithms published in the last decade. When it comes to boosting the performance of our model, these optimization strategies are highly strong. We plan to implement and integrate these techniques with a use-case scenario for our specific implementation in the future. By combining these techniques with our model, we can achieve accuracy levels of around 98 percent. We have already started the implementation of these models for our use-case, but are facing difficulties currently customizing the code for our problem, but through adversities we rise, and I am sure we will be able to overcome these challenges in the future!