By Group "Semantic Analysts," written by Prateek Kher
Introduction
Don’t worry, if you are wondering this blog post will be as dull as the last, it would not. I will try to make this blog post as illustrative, interesting and interactive as possible! In this blog post, I will share how our group solved the problem of data extraction, and what will be the next steps!
Objectives and How We Completed the Work
Our group, wanted to approach this problem differently. There is no literature currently which talks about extracting data about fraudulent and non fraudulent companies using APIs, segregating them, training the model, and wait for the model to give us results.
Our first objective, was to figure out which data to use to conduct textual analysis. We then came across the Management Discussion and Analysis section data of 10-k filings with the SEC. We immediately knew our target! MD&A section data provides a textual overview of company performance, in addition, a review of the objectives and goals for the following year is provided. Annual reports contain twice as much information in the language as they do in the financial figures. This section is critical in finding a company’s health!
EDGAR, SEC and AAER
The Securities and Exchange Commission (SEC) requires publicly traded companies to file a slew of documentation. The EDGAR database was designed by the Securities and Exchange Commission (SEC) to help preserve capital markets and make public company filings more accessible. It's a system that "performs automated functions," according to them. Companies and others who are required by law to file forms with the US government have their submissions gathered, evaluated, indexed, accepted, and forwarded. Each filing is kept as an index file in the EDGAR system, which includes the filer's name, a unique central index key, the date, and the directory of the EDGAR system. The picture below shows us a sample from the SEC EDGAR database form:
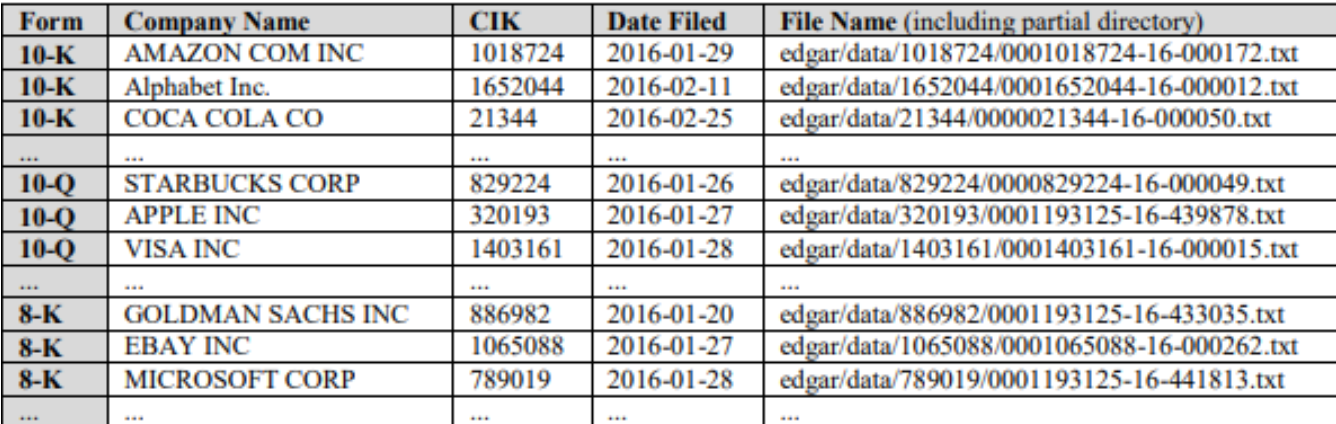
Our second objective was to create a database with known number of fraudulent, and non-fraudulent companies. To make such a database, we first have to know for sure, which companies have committed fraud in the past. This was the period which easily took our team the longest to do. We did not have relevant past literature review, to follow seemingly easy steps! We then thought of looking through the AAER reports, and then found, that UC Berkeley’s Center for Financial Reporting and Management (CFRM) releases a dataset annually which contains the AAER records of companies! These AAER records also contain the CIK (Central Index Key) of companies! We were enthralled! As we would use this was to extract the MD&A section data from the 10-k files of companies. Table below shows a sample of AAER Dataset compiled by the CFRM.

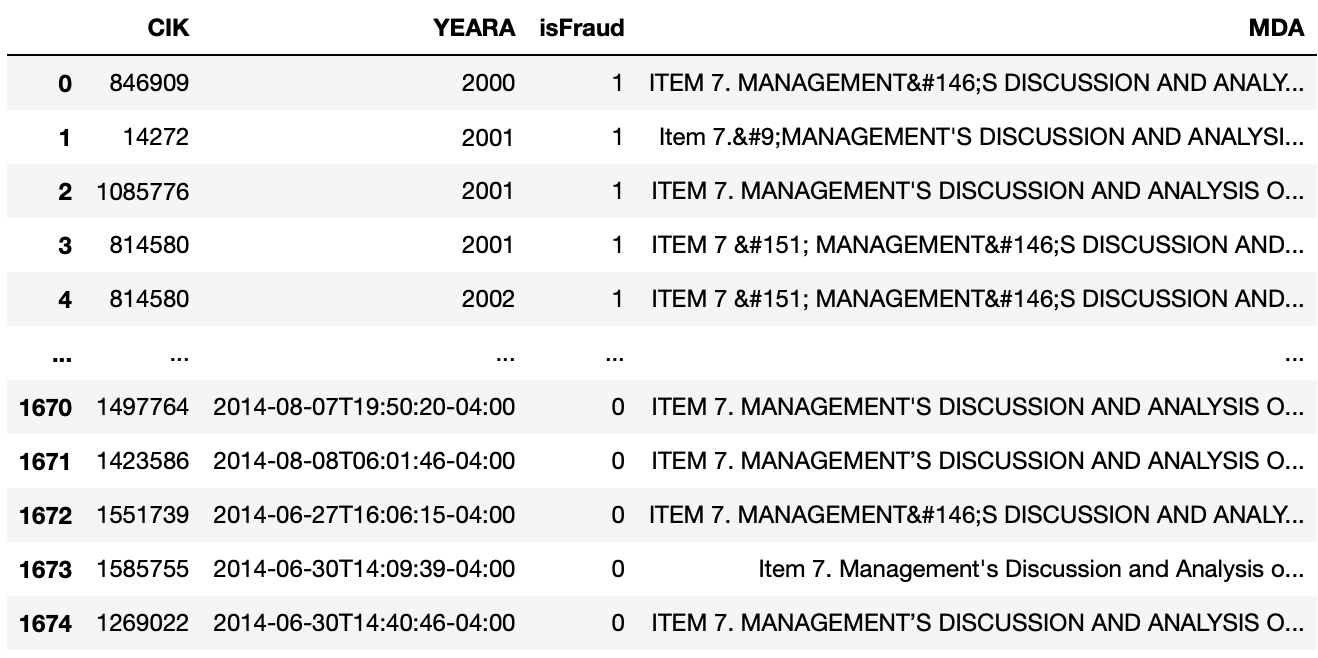
We now have all of the information we need to complete the MD&A column of our dataframe and classify instances as fraudulent or non-fraudulent. The CIK and the year connect both the pictures shown above. All of the overlapping cases in second picture have received an AAER, indicating that they are all fraudulent. We use the SEC-Query API's API to access the financial statement's HTML content using the CIK and the Year. The remaining cases are chosen as non-fraudulent. The Extractor API extracts any item from 10-Q and 10-K filings and returns it to you as cleaned and standardized text or HTML. An item is extracted as clear-text or ordinary HTML without the usage of an extraction algorithm. We then proceed to use the extractor algorithm to extract the raw data.
More interactive pictures and code shown below.
We first install the SEC-API
import pandas as pd
#eac2066f382498aed48e5f03b594e7a5600120b542c08e03d59ca9ced2c6552c
! pip install --user sec-api
We download the AAER dataset, as shown in the code below, and we are good to go!
df = pd.read_csv("AAER_firm_year.csv")
df = df.drop("UNDERSTATEMENT",1)
df["isFraud"] = 0
df
We use the queryAPI as shown below, coupled with the AAER dataset to solve our problem of getting the fraudulent and non-fraudulent companies.
from sec_api import QueryApi
queryApi = QueryApi(api_key="eac2066f382498aed48e5f03b594e7a5600120b542c08e03d59ca9ced2c6552c")
count = 0
for index, row in df2.iterrows():
query = {
"query": { "query_string": {
"query": f"cik:{row.CIK} AND filedAt:[{row.YEARA}-01-01 TO {row.YEARA}-12-31] AND formType:\"10-K\""
} },
}
filings = queryApi.get_filings(query)
if(filings['total']['value']>0):
row["isFraud"] = 1
else:
row["isFraud"] = 0
count+=1
print(count,row.CIK)
We go on to use the extractor API, which was extremely useful and proved to reduce our workload immensely. We currently just have the database which contains details whether companies are fraud or not, but our group did not want that, we wanted something more. Therefore, we used to extractor and query API to retrieve the MDA section data.
The code below was used to extract the MDA text:
from sec_api import ExtractorApi
from sec_api import QueryApi
queryApi = QueryApi(api_key="eac2066f382498aed48e5f03b594e7a5600120b542c08e03d59ca9ced2c6552c")
query = {
"query": { "query_string": {
"query": f"cik:846909 AND formType:\"10-K\""
} },
}
filings = queryApi.get_filings(query)
print(filings['filings'][0]['linkToFilingDetails'])
extractorApi = ExtractorApi("eac2066f382498aed48e5f03b594e7a5600120b542c08e03d59ca9ced2c6552c")
queryApi = QueryApi(api_key="eac2066f382498aed48e5f03b594e7a5600120b542c08e03d59ca9ced2c6552c")
#6,22,32,52,91,93,47,29
count=0
for year in range(2008,2015):
query = {
"query": { "query_string": {
"query": f"filedAt:[{str(year)}-01-01 TO {str(year)}-12-31] AND formType:\"10-K\""
} },
}
filings = queryApi.get_filings(query)
for i in range(len(filings['filings'])):
if(int(filings['filings'][i]['cik']) not in fraudpd.CIK.values):
if('.htm' in filings['filings'][i]['linkToFilingDetails']):
section_text = extractorApi.get_section(filings['filings'][i]['linkToFilingDetails'], "7", "text")
if(section_text!="undefined" and len(section_text)>1000):
count+=1
section_text = ' '.join(section_text.split())
entry = {'CIK': int(filings['filings'][i]['cik']), 'YEARA': filings['filings'][i]['filedAt'], 'isFraud': 0,'MDA':section_text}
fraudpd= fraudpd.append(entry, ignore_index = True)
print(count)
Once we execute the code above, we can do some extra data cleaning. We can delete unneccesary columns, and our final dataframe looks like the picture shown below:
Learning Outcomes, both Qualitative and Quantitative!
This part applies universally to anyone reading this blog post, or attempting to scrape data via SEC EDGAR database, and the AAER UC Berkeley database. We had to customise the data extraction techniques as per our use-case requirement, but what kept us going was the hustle to solve the problem. As we progressed forward, we started getting deeper and deeper into the question as to why we started in the first place? Going forward, we learnt that no matter what - be patient. For our team, this part took more than 1 month, to extract relevant data, and to sit down and understand how to edit it, and use the API keys to navigate through the data. Patience has been key in determining our success. Apart from patience, we definitely learnt how to use API keys properly, and extract data from them. This class has been immense in teaching me how to scrape data, both using web scraping technology directly from websites, as I did for my midterm project, but also through API keys.
What we could have done better? I believe our team has progressed decently, but our work distribution was not set correctly. Recommendation for all the team following the same things that we tried to do, do follow a set guideline when it comes to work, and stick to timelines. We could have also technically used the API keys before. We were trying to extract data manually using obsolete measures, which took up quite a lot of our time as well.
However, we aim to continue achieving our results through this mindset, as we know when we run our models, this will require immense amount of patience, labor, time and effort. I am personally looking forward to it, and I am willing to see what I can learn more in this journey.