By Group "Simplicity," written by Hang CHAN Cheuk Hang
Author Introduction
I'm Hang and I'm a final year student studying Economics and Finance at HKU, in charge of cleaning data (text) and identifying the stock mentioned within the text.
Overall Objective and Workflow
Using the data collected, we needed to combine and clean the data, then identify the stock mentioned in the data. It is important to clean the data so that when sentiment analysis is conducted, it can be as accurate as possible. Then, output it as a CSV file for sentiment analysis. The steps are shown below:
- Read multiple Reddit CSV files as DataFrames and combine (concatenate) them
- Clean the data within the Reddit DataFrame, specifically the Title, Content, and Comment columns
- Read multiple Stock Ticker (NASDAQ, NYSE, AMEX) CSV files as DataFrames and combine (concatenate) them
- Identify the stock mentioned in the data and confirm if it’s a real stock ticker
- Output DataFrame as CSV for sentiment analysis
Libraries and Modules Used:
import pandas as pd
import numpy as np
import emoji
import os
import time
Overall Workflow Represented in main() Function:
def main():
# Track start time
start = time.time()
# Path to access and output files
path = r'/Users/XFlazer/Documents/HKU/FBE/Finance/Natural Language Processing/Reddit Project'
# Read all reddit csv files as DataFrame
reddit_2018 = pd.read_csv(path + os.sep + 'Reddit WSB Data with most upvote comments 2018-09-01 to 2018-12-31.csv')
reddit_2019 = pd.read_csv(path + os.sep + 'Reddit WSB Data with most upvote comments 2019-01-01 to 2019-12-31.csv')
reddit_2020 = pd.read_csv(path + os.sep + 'Reddit WSB Data with most upvote comments 2020-01-01 to 2020-12-31.csv')
reddit_2021 = pd.read_csv(path + os.sep + 'Reddit WSB Data with most upvote comments 2021-01-01 to 2021-12-31.csv')
# Make a copy to not affect original DataFrame
r_18 = reddit_2018.copy()
r_19 = reddit_2019.copy()
r_20 = reddit_2020.copy()
r_21 = reddit_2021.copy()
# Place them into a list to combine them
r_lst = [r_18, r_19, r_20, r_21]
# Combine all reddit DataFrames
reddit_df = combineDF(r_lst)
# Clean the data
reddit_df = cleanData(reddit_df)
# Read all stock ticker csv files as DataFrames
nasdaq_df = pd.read_csv(path + os.sep + 'Nasdaq.csv')
nyse_df = pd.read_csv(path + os.sep + 'Nyse.csv')
amex_df = pd.read_csv(path + os.sep + 'Amex.csv')
# Place them into a list to combine them
tickers_lst = [nasdaq_df, nyse_df, amex_df]
# Combine all stock ticker DataFrames
tickers_df = combineDF(tickers_lst)
# Match the stock mentioned in text to a real stock ticker
reddit_df = stockMatch(reddit_df, tickers_df)
# Output file as csv for further analysis
reddit_df.to_csv(path + os.sep
+ 'reddit_with_ticker.csv', index = False)
# Prints out how long the program took in seconds
print('The time it took to run the program:',
time.time() - start, 'seconds')
# Calls main program
main()
Combine Reddit CSV Files into One DataFrame
At first, I was unsure whether or not to combine all the Reddit CSV files and then clean, or clean them individually first, and then combine. However, I decided to combine them first because it would mean all the data was within one DataFrame instead of multiple ones, making it cleaner and easier to work with even if it may take longer.
Function to Combine (Concatenate) CSV Files
def combineDF(df_lst):
'''
This function concatenate all the DataFrames, returns a DataFrame
'''
# Concatenate all the DataFrames and automatically reset index
df = pd.concat(df_lst, ignore_index = True)
# Returns df for cleaning
return df
Cleaning Data
Cleaning data in our case means to:
- Remove any row where the Title, Content, or Comment is identified as deleted, removed, or deleted by user
- Remove any punctuation besides ‘!’, links, line spaces, usernames or subreddits mentioned in the Title, Content, and Comment. We keep '!' because it affects the sentiment.
To complete 1., I could easily just take the rows where the Title of the post was '[deleted by user]' instead of removing the rows. I made sure to reset the index and drop the old index column so that the DataFrame is cleaner. Then, I repeated this step for Content and Comment columns. However, the content and comment columns have a different identification method for a post that was removed or deleted, which is displayed as '[removed]' and '[deleted]', respectively. Thus, for the text in the Title, Content, and Comment columns, I only took the valid ones.
Function to Clean Data: Taking Non-Deleted Posts
def cleanData(df):
'''
This function cleans the DataFrame. It removes deleted posts, special
words, and any confusing punctuation that may be referring to another
user
'''
# Takes rows where title is NOT deleted by user
df = df[(df['title'] != '[deleted by user]')].reset_index(drop = True)
# Takes rows where content is NOT removed or deleted
df = df[(df['content'] != '[removed]')
& (df['content'] != '[deleted]')].reset_index(drop = True)
# Takes rows where comment is NOT removed or deleted
df = df[
(df['comment_content'] != '[removed]')
& (df['comment_content'] != '[deleted]')
].reset_index(drop = True)
Additionally, I had to keep the emojis and used the emoji module to create a list of emojis. Then, I joined them as a string with a ‘|’ delimiter as this signifies or during string manipulation. After, I considered using re.sub() and mapping it (.map()) to each of the three columns but I discovered a faster method.
I found a faster way by directly using df.Column.replace, which uses Series operation which should be faster than using .map(). To remove everything else besides the data we wanted to keep, I did the inverse of the usual Series.replace(). Everything within the brackets ‘[^ ]’ would be protected, and anything outside specifically mentioned will be replaced with an empty string. I learned that we could also add specific strings to be protected if it’s delimited by a ‘|’, hence the earlier joining of emojis to protect them. For the characters that would be deleted, it would only delete that specific character, but I learned that we needed to add the ‘\S+’ to indicate that any non-space character followed by it will also be replaced.
Finally, I would combine all the text within the three columns into one column. This will be needed to identify which stock is being discussed in the text. However, since we are taking the first stock mentioned, I decided to combine them in the order of Title, Content, Comment, as I assumed that the stock being discussed will be mentioned in the Title first. If not, it should be in the Content followed by the Comment.
Function to Clean Data Continued: Keeping Only Words and Emojis (and '!')
# Use emoji module to create emoji list to keep emojis
emoji_lst = [i for i in emoji.UNICODE_EMOJI['en']]
# Create a text of emojis so that it will not be filtered out when
# cleaning
emojis = '|'.join(emoji_lst)
# Remove punctuations (except '!'), links, line space, usernames
# or subreddits from title
df['title'] = df['title'].replace(
r'[^\w\s\!\{emojis}]|http\S+|\n|u/\S+|r/\S+'.format(emojis = emojis),
'', regex = True)
# Remove punctuations (except '!'), links, line space, usernames
# or subreddits from content
df['content'] = df['content'].replace(
r'[^\w\s\!\{emojis}]|http\S+|\n|u/\S+|r/\S+'.format(emojis = emojis),
'', regex = True)
# Remove punctuations (except '!'), links, line space, usernames
# or subreddits from comment
df['comment_content'] = df['comment_content'].replace(
r'[^\w\s\!\{emojis}]|http\S+|\n|u/\S+|r/\S+'.format(emojis = emojis),
'', regex = True)
# Combines all content into 1 cell for future use
df['all_content'] = df[
['title', 'content', 'comment_content']
].fillna('').agg(' '.join, axis = 1)
# Returns the cleaned df for stock matching
return df
Combine Stock Ticker CSV Files into One DataFrame
I read all the Stock CSV files and combined them into a single DataFrame to make it easier to access all the stock tickers. The reason is the same as combining multiple Reddit CSV files.
Stock Matching: Overall
To match the stock mentioned in the text:
- Ignore some characters/words such as “I” or “ETF” so that it will not be confused with actual stock tickers
- Match the first stock ticker mentioned in the text to a list of stock tickers from the Stock CSV DataFrame
- Create a new column with the stock ticker identified and remove those without a stock ticker identified
Function to Match Stock
def stockMatch(df, t_df):
'''
This function attempts to recognize the stock mentioned in the title,
comment, or comment post. Each word will be compared to a list of stock
tickers. If there is no match, the row will not be included in the
new DataFrame.
'''
# Create a new column called "removed_words" to show the text after all
# necessary words (ignored_words) are removed
df['removed_words'] = df['all_content'].map(lambda x: ignoreWords(x))
# Create a new column called "ticker" to place the ticker identified
df['ticker'] = df['removed_words'].map(lambda x:
stockSearch(x.split(), t_df))
# Only takes rows where a stock ticker has been identified
df = df[df['ticker'].notna()].reset_index(drop = True)
# Returns the DataFrame to main to be outputted as csv
return df
Initially, I used a nested loop to loop through the whole DataFrame and loop the text and match each word individually to a ticker in a list of stock tickers (while ignoring words that could be confused as stocks). However, that took way too long. Thus, I decided to create a new column where only the valid words would remain, meaning I had removed all the words that would be ignored. However, using a regular for loop still took quite a long time.
I initially re-used Series operation, i.e. df.Column.replace, creating a list of words to ignore, joining them with a ‘|’ delimiter, thus matching and replacing them with an empty string, effectively removing them. Strangely, it took too long for the program to run so I decided to pursue another method.
Stock Matching: Ignore Words
I created a new function called ignoreWords(text) and mapped the column with all the text to it. In that function, I created a set of words to ignore and tried to remove them if it matches the whole word, using re.sub() once again.
However, it just took too long, so I used a for loop to loop through each word (substring) within the text instead. Interestingly, although it still took a while, it was faster than using re.sub(). Then, I realized that we could also simply remove any substring that have a greater length than 5 (length of stock tickers < 5), not lower or uppercase, e.g. “Last, To”, or any lowercase words. I considered using list comprehension but due to the number of rules, I decided against it in favor of readability. This sped up the program considerably. With the remaining text which are all uppercase words, I tried to match any word(s) to a stock ticker.
Function to Ignore Words
def ignoreWords(text):
'''
This functions takes in the text and removes certain words for stock
search afterwards, returning the whole text after editing
'''
# Words to ignore consisting of abbreviations redditors often use and other
# common abbreviations
ignore_words = {
'JAN', 'FEB', 'MAR', 'APR', 'MAY', 'JUN', 'JUL', 'AUG', 'SEP',
'OCT', 'NOV', 'DEC','A', 'I', 'U', 'ELON', 'MUSK', 'ETF', 'DFV',
'CATHIE', 'WOODS', 'TOS', 'ROPE', 'YOLO', 'CEO', 'CTO', 'CFO',
'COO', 'DD', 'IT', 'ATH', 'POS', 'IMO', 'RED', 'KMS', 'KYS',
'GREEN', 'TLDR', 'LMAO', 'LOL', 'CUNT', 'SUBS', 'USD', 'CPU',
'AT', 'GG', 'AH', 'AM', 'PM', 'TICK', 'IS', 'EZ', 'RAW', 'ROFL',
'FOMO', 'FBI', 'SEC', 'GOD','CIA', 'LONG', 'SHORT', 'ATM', 'OTM',
'ITM', 'TYS', 'IIRC', 'IIUC', 'PDT', 'TOS', 'TYS', 'OPEN', 'IRS',
'ALL', 'OK', 'BTFD', 'US', 'USA', 'GDP', 'FD', 'TL', 'OP', 'PS',
'WTF', 'FOMO', 'CALL', 'PUT', 'BE', 'PR', 'GUH', 'JPOW', 'BULL',
'BEAR', 'BUY', 'SELL', 'HE', 'ONE', 'OF', 'SHE', 'HODL', 'FINRA',
'WSB', 'MODS', 'MOD', 'EPS', 'IRA', 'ROTH', 'BS', 'RIP', 'OMG',
'IM', 'YOU', 'DOW', 'ARE', 'FREE', 'MONEY'
}
# Split the text into a list of words
text_lst = text.split()
# Loop through the list of words in text
for word in list(text.split()):
# Conditions in order to remove words:
# Greater than 5 (length of stock ticker)
# Word in ignore_words set
# Not lower or uppercase words (e.g. Last) and not lowercase words
if (len(word) > 5
or word in ignore_words
or (not word.isupper() and not word.islower())
or word.islower()):
text_lst.remove(word)
# Returns a string after joining the list of words in text
return ' '.join(text_lst)
Stock Searching
Following my previous method, I also created a new function called stockSearch(text_lst, t_df). If there is no text, it would return NaN and if there are word(s), then it would compare it to a list of stock tickers. Since we only want the first stock mentioned, I used the break option even though it might not be elegant. The remaining text (after ignoreWords(text)) was mapped to this function.
Function to Search for Stock Tickers
def stockSearch(text_lst, t_df):
'''
This function searches for the stock ticker to match with the text list
given. It then returns the FIRST stock identified.
'''
# Convert the stock ticker Series into a list
tickers_lst = (t_df['Symbol'].to_list())
# If there is no text, return NaN
if len(text_lst) == 0:
return np.nan
# Else, try to find the stock ticker
else:
# For loop to loop through words in a text list
for word in text_lst:
# If the word matches the one in tickers list, returns the word
# and breaks since only taking FIRST instance
if word in tickers_lst:
return word
break
Once the stockSearch function was finished, I only took rows where a stock ticker has been identified and reset the index.
Major Difficulties in Stock Matching
While the code seemed relatively simple, it took me a long time to arrive there. After all, I was convinced that using a for loop for anything would take too long. Thus, I first tried to use np.select() . Although I tested it for a single row and it found the matching stock ticker, it was too slow when applied to the whole DataFrame.
Too Slow: np.select()
conditions = list(map(df['removed_words'].str.contains,
list(tickers_df.Symbol)))
reddit_df['tickers'] = np.select(conditions,
list(tickers_df.Symbol), np.nan)
Next, I tried to use re.search() to find the index of the stock ticker matched, then use .start() and .end() to return the word. However, when I tested it, I found that it would not match the whole ticker, but just the initial letters found which may correlate to a stock. For example, instead of returning SPY, it returns SP.
Did Not Return Correct Stock Ticker: re.search() and Function
def pattern_searcher(search_str:str, search_list:str):
search_obj = re.search(search_list, search_str)
if search_obj :
return_str = search_str[search_obj.start(): search_obj.end()]
else:
return_str = 'NA'
return return_str
Third, I tried to delete all stock tickers mentioned in the text and copy it to another piece of text using re.sub(). Then, I would find the unique value(s) between both texts and that would be the stock ticker! However, my first difficulty was finding a way to completely match word by word rather than by character. For example, the matching might return SP instead of SPY since SP is a real stock. Fortunately, there was a way to match the whole ticker rather than some characters. After finding out how, I applied it to the column of text but it was still too slow.
Too Slow: re.sub()
re.sub('|'.join("((?<=\s)|(?<=^)){}((?=\s)|(?=$))".format(i) for i in ticker_lst), '', text)
Therefore, I returned to using a for loop and .map().
Output as CSV
Once the DataFrame has been cleaned, and a stock has been identified, I outputted it as a CSV file so that sentiment analysis can be applied on the text.
An example of the CSV file:
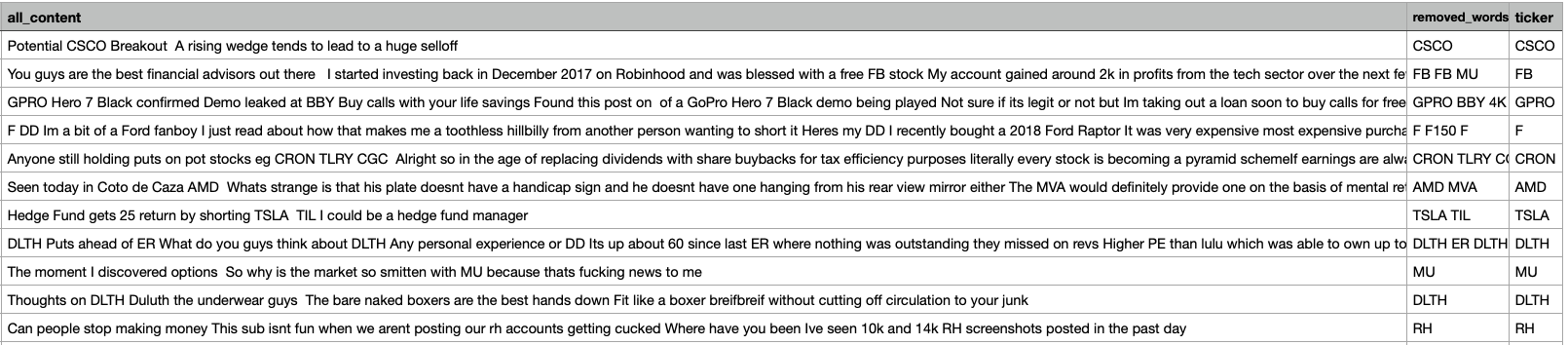
Final Thoughts
I found the data cleaning part relatively easier than identifying a stock. The main difficulty came from using conventional methods such as Series operations, which, for some reason, was slower than mapping a column to a function. Additionally, it was just more complex to identify a stock until I realized that the stock ticker mentioned must always be uppercase. However, I realize that my code can always be improved in terms of speed, perhaps using vector-based operations would make it more efficient.
To be sure, this was quite a challenging experience trying to find methods to identify the stock. I was stuck for more than a day doing this, surfing through StackOverflow for the best method. At the end, my bad practice of using for loops actually ended up solving the problem of speed and extracting the correct information for me!
Link to code can be found here: Cleaning Reddit Data and Identifying Stock