By Group "Finword Warriors"
Introduction
In this blog, we would like to share about the methodology and work progress of our sentiment analyzer – Sentiment Sage, including what we have done in these 2 months with code snippets, and how we integrate with an online application Streamlit, and what we still can improve for this model.
Overview of our online application
To bring our project to applicable stuff, we built the SentimentSage application using Streamlit Community Cloud, an open-source framework that allowed us to transform our Python scripts into a sleek, interactive command center. By syncing the app directly with our GitHub repository, we created a platform where users can obtain detailed sentiment and information with a few clicks.

The SentimentSage application streamlines market monitoring by utilizing NewsAPI to fetch the most recent and relevant headlines across a wide range of companies in real-time. These headlines are analyzed using an integrated FinBERT model, a specialized transformer architecture designed to comprehend intricate financial terminology and sentiment. To ensure instant clarity for the user, sentiment scores—ranging from 0 to 1—and confidence levels are visualized through interactive pie and bar charts.
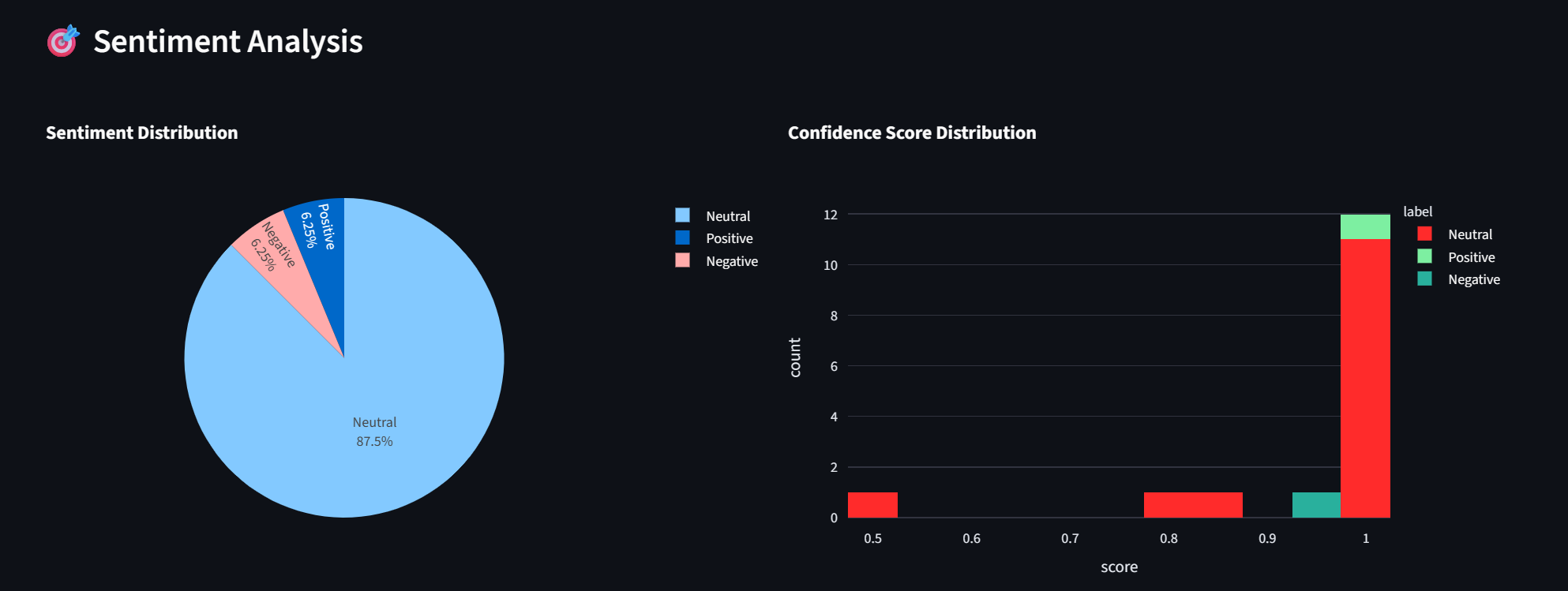
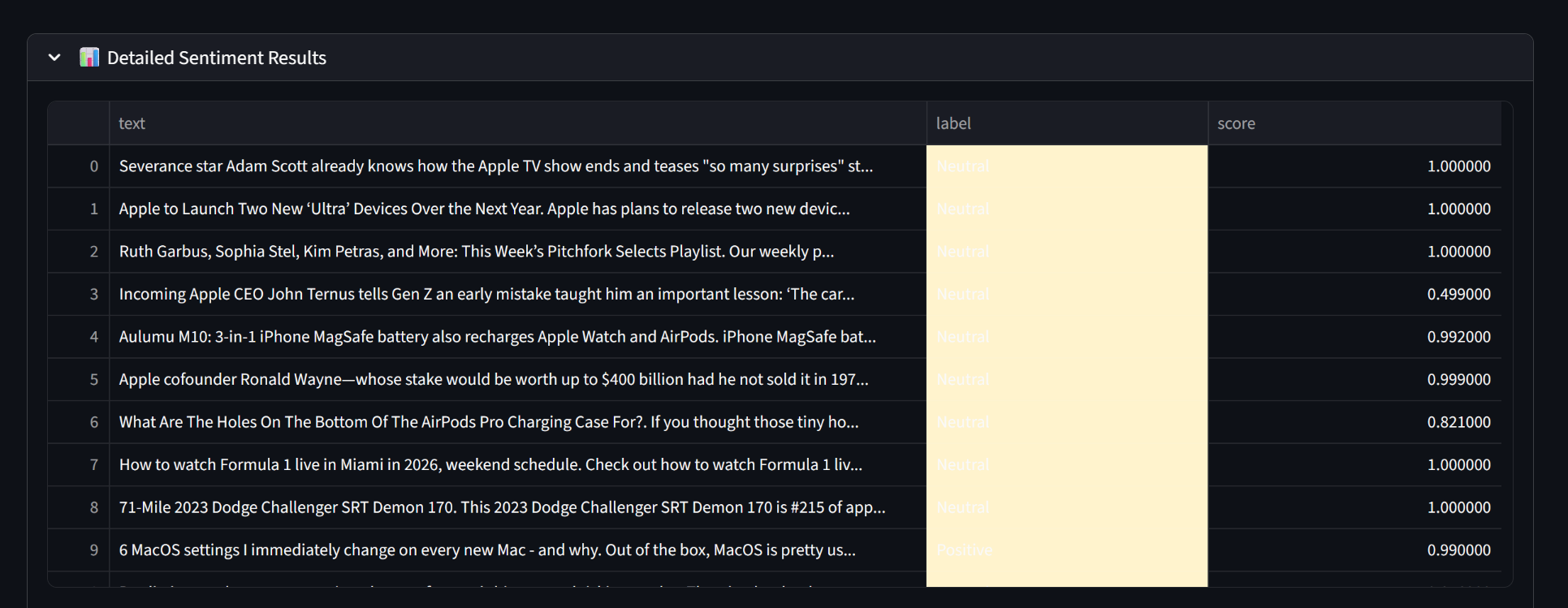
Under the hood, the platform implements a Retrieval-Augmented Generation (RAG) architecture using LangChain and AI API keys. This framework ensures that generated investment summaries are strictly grounded in the specific news articles retrieved during the current session, effectively mitigating the risk of AI hallucinations. These summaries offer more than just a surface-level overview; they provide detailed sentiment and risk assessments alongside practical trading strategies—such as specific short-price targets and long-option suggestions—to help users interpret stock price trends and apply findings with ease.


The platform emphasizes high customizability, ensuring the architecture remains flexible to meet diverse user requirements. While the demonstration features presets for Nvidia AI and NewsAPI, the system is designed to be provider-agnostic, allowing users to switch to other services such as OpenAI. Furthermore, the integration of premium or paid API keys is fully supported, enabling access to more powerful models for deeper analysis and ensuring that the tool's intelligence can scale alongside the user’s needs.
Some room to improve
While SentimentSage marks a major step forward in bridging the gap between quantitative metrics and qualitative intelligence, the development journey was defined by several critical "learning moments." A primary technical hurdle involved navigating strict token restrictions; the RAG pipeline frequently encountered 400-level errors when processing long-form financial content that exceeded the 512-token maximum. This necessitated a more precise and sophisticated text-splitting logic to ensure data integrity without triggering system failures.
Furthermore, data availability proved inconsistent across different market segments. While major entities like the "Magnificent Seven" yielded an abundance of articles, niche companies—particularly those in Asian regions not listed on the NYSE—often faced a significant lack of real-time news data. This issue was compounded by a heavy dependence on specific API keys and the high degree of specificity required for company name identification, which remains a persistent challenge in data retrieval.
Beyond data collection, the project also addressed a significant validation gap. Although sentiment precision remains high, these scores have not yet been backtested against actual market price movements. Consequently, the AI-generated trading strategies should be viewed as hypothetical, laggy indicators rather than immediate financial advice. Finally, the reliance on free-tier APIs introduced moderate latency and a heightened sensitivity to prompt engineering, serving as a constant reminder that achieving true system robustness is an unending pursuit.
FinBERT model training
Instead of using the pretrained FinBERT model, we chose to fine-tune the model to increase the performance.
1. Dataset
The dataset used is “Sentiment analysis of commodity news” by ANKUR SINHA on Kaggle, giving us 2804 news along with sentiment labels. The dataset was split into a training set (75%), a validation set (15%), and a test set (10%).
2. Training Configuration
The model was initialized from “yiyanghkust/finbert-tone” and fine-tuned for 3 epochs, using AdamW optimizer with a learning rate of 2e-5 and linear warmup scheduling. Input texts were tokenized and truncated to a maximum length of 128 tokens with a batch size of 16.
3. Results
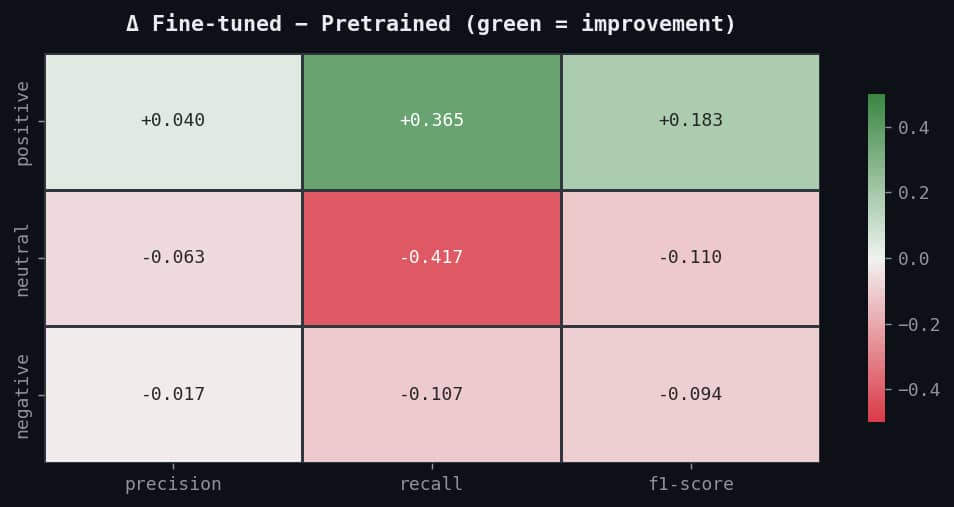
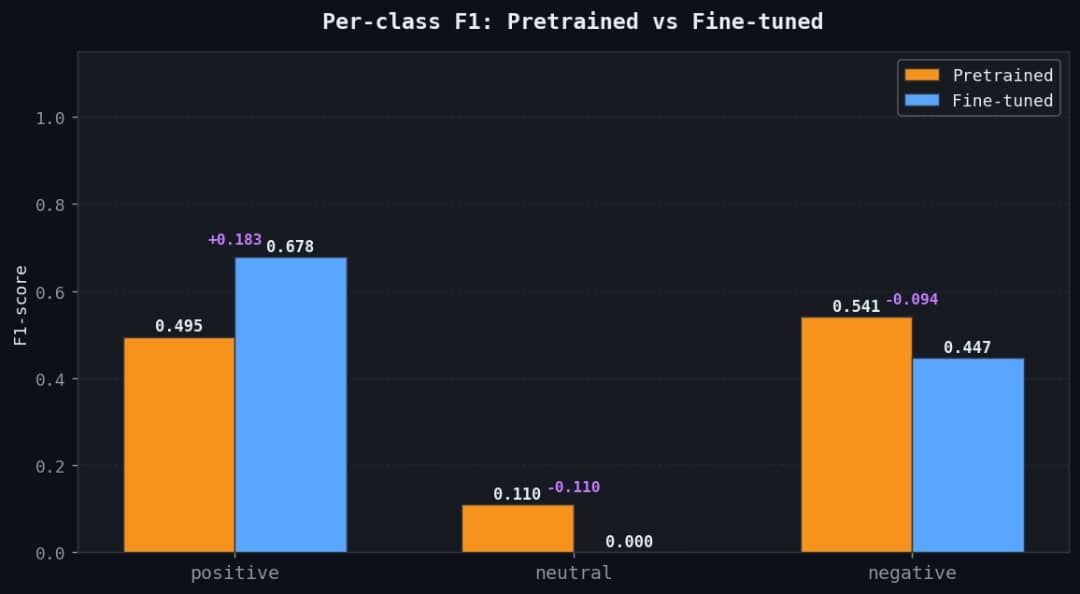
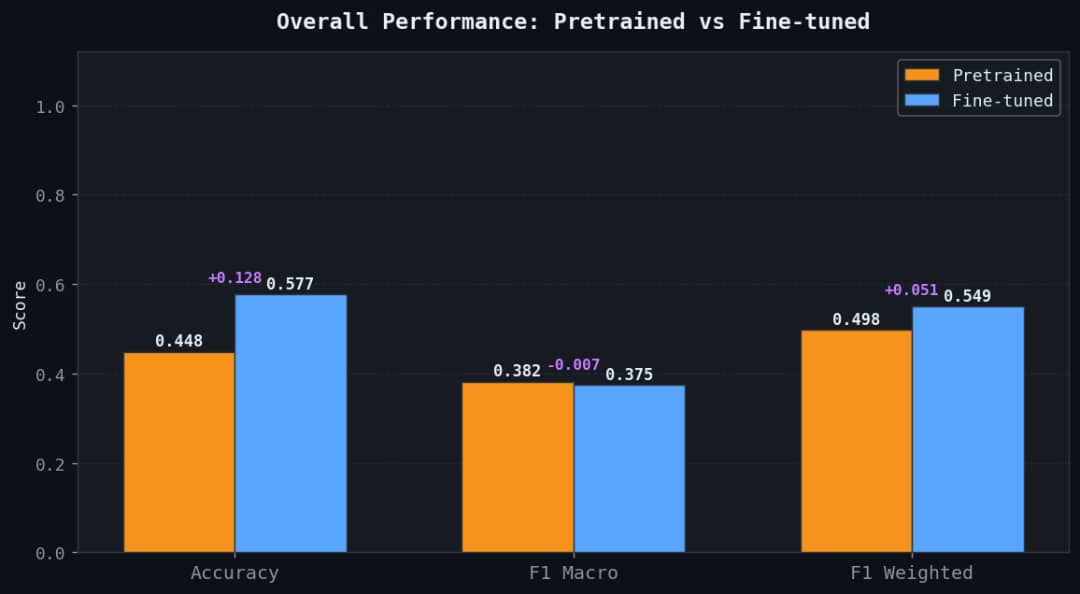
Compared to 44.8% accuracy and 0.407 weighted F1 for the pretrained model, the fine-tuned model achieved a test accuracy of 57.7% and a weighted F1-score of 0.549, representing a consistent improvement across all metrics. Per-class evaluation shows the highest gain on the positive class, with recall improving by 36.5 percentage points.
Methodology
1. Overall workflow
The SentimentSage system operates through a three-stage pipeline: Workflow steps:
Step1: News Fetching - User inputs a company ticker (e.g. AAPL, TSLA) - System calls NewsAPI to retrieve 20 most recent financial articles - Articles are cached
Step2: Sentiment Analysis with FinBERT - Each article is passed through FinBERT - Model outputs: sentiment label + confidence score - Results are aggregated and visualized in pie charts and histograms
Step3: RAG-Powered Q&A - Articles are split into character chunks with overlap - Chunks are embedded via embedding tool and stored in FAISS database - User’s question triggers retrieval of relevant chunks - Retrieved context + question are sent to LLM to generate summary Output: Sentiment distribution charts + AI-generated investment recommendations grounded in actual news data.
2. Sentiment Analysis with FinBERT Function
SentimentSage uses FinBERT, a BERT variant pre-trained on financial communications, for specialized sentiment analysis. This model classifies each financial news article as positive, negative, or neutral with a confidence score.
def analyze_sentiment(articles, pipe):
"""Analyze sentiment of articles using FinBERT"""
results = []
progress_bar = st.progress(0)
for i, text in enumerate(articles):
try:
sentiment = pipe(text[:512])[0]
results.append({
"text": text,
"label": sentiment['label'],
"score": sentiment['score']
})
progress_bar.progress((i + 1) / len(articles))
except Exception as e:
st.warning(f"Error analyzing article {i+1}: {str(e)}")
continue
progress_bar.empty()
return results
3. RAG Pipeline Function
For contextual Q & A, a Retrieval-Augmented Generation pipeline is implemented. Articles are chunked, embedded via embedding tool, and stored in a FAISS vector index database. When a question is asked, relevant chunks are retrieved and passed to LLM (e.g. Kimi, GPT) for context-aware answers.
def build_rag_pipeline(articles):
"""Build RAG pipeline for question answering"""
try:
with tempfile.NamedTemporaryFile(mode="w", delete=False, suffix=".txt", encoding="utf-8") as f:
f.write("\n\n".join(articles))
temp_file = f.name
loader = TextLoader(temp_file, encoding="utf-8")
documents = loader.load()
splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
docs = splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(docs, embeddings)
llm = OpenAI(temperature=0)
#For NVidia API
#embeddings = NVIDIAEmbeddings(model="nvidia/nv-embedqa-e5-v5")
#db = FAISS.from_documents(docs, embeddings)
# --- CHANGE 2: Use NVIDIA Chat Model ---
# You can choose models like "meta/llama-3.1-405b-instruct" or "nvidia/nemotron-4-340b-instruct"
#llm = ChatNVIDIA(model="meta/llama-3.1-8b-instruct", temperature=0.2)
# 定義提示詞模板
prompt = ChatPromptTemplate.from_template("""
Answer the following question based only on the provided financial news context:
<context>
{context}
</context>
Question: {input}
""")
combine_docs_chain = create_stuff_documents_chain(llm, prompt)
qa_chain = create_retrieval_chain(
retriever=db.as_retriever(),
combine_docs_chain=combine_docs_chain
)
os.unlink(temp_file)
return qa_chain
except Exception as e:
st.error(f"Error building RAG pipeline: {str(e)}")
return None
4. News Fetching Function
Real-time news is aggregated via NewsAPI.
@st.cache_data
def fetch_news(query, api_key=NEWS_API_KEY):
"""Fetch financial news articles"""
url = f"https://newsapi.org/v2/everything?q={query}&sortBy=publishedAt&language=en&pageSize=20&apiKey={api_key}"
try:
response = requests.get(url)
response.raise_for_status()
articles = response.json().get("articles", [])
return [f"{a['title']}. {a['description'] or ''}" for a in articles if a['title'] and a['description']]
except Exception as e:
st.error(f"Error fetching news: {str(e)}")
return []
Conclusions
SentimentSage marks an integration of domain-specific NLP and modern web technologies. By bridging the gap between quantitative sentiment metrics and qualitative investment intelligence, we have provided a unified platform for deeper market understanding. Some of the key successing pillars are:
- FinBERT Core: High-precision capture of nuanced market sentiments using a specialized financial language model.
- RAG Architecture: Ensuring AI summaries are grounded in real-time, retrieved news data through Retrieval-Augmented Generation for maximum reliability.
- Comprehensive Insights: A synergistic approach that combines FinBERT’s quantitative precision with the descriptive, contextual power of RAG-powered analysis.
Limitations
Despite the successful implementation, our development journey highlighted several technical and operational constraints that we aim to address in future iterations:
- Technical Bottlenecks: We encountered significant token restrictions and occasional RAG pipeline errors when processing long-form financial content.
- API & Data Quality: The system currently relies on free-tier APIs, which exhibit moderate performance and high sensitivity to prompt engineering.
- Market Scope: There are inherent difficulties in fetching consistent and relevant news for small-cap companies or niche market entities.
- Validation Gap: Currently, the sentiment scores are standalone and have not yet been backtested against actual historical price movements.
Future Improvements: What’s Next?
To transform SentimentSage into a more robust professional tool, our roadmap focuses on expanding data horizons and enhancing system stability:
- Multi-source Integration: Incorporating alternative data streams, including social media platforms (Reddit/X) and professional analyst reports.
- Temporal Analysis: Implementing features to track the evolution of sentiment and identify key trend shifts over time.
- System Robustness: Enhancing RAG logic to better handle token overflows and high-volume data streams effectively.
- Interactive Dashboard: Developing a more immersive user experience with real-time alerts and cross-market correlation visualizations.