By Group "Sentiment Arbitrage"
From Company Name to Stock Ticker: An Iterative Journey Through M&A Entity Recognition
Based on SEC 8-K Filings · NER & Ticker Mapping Module
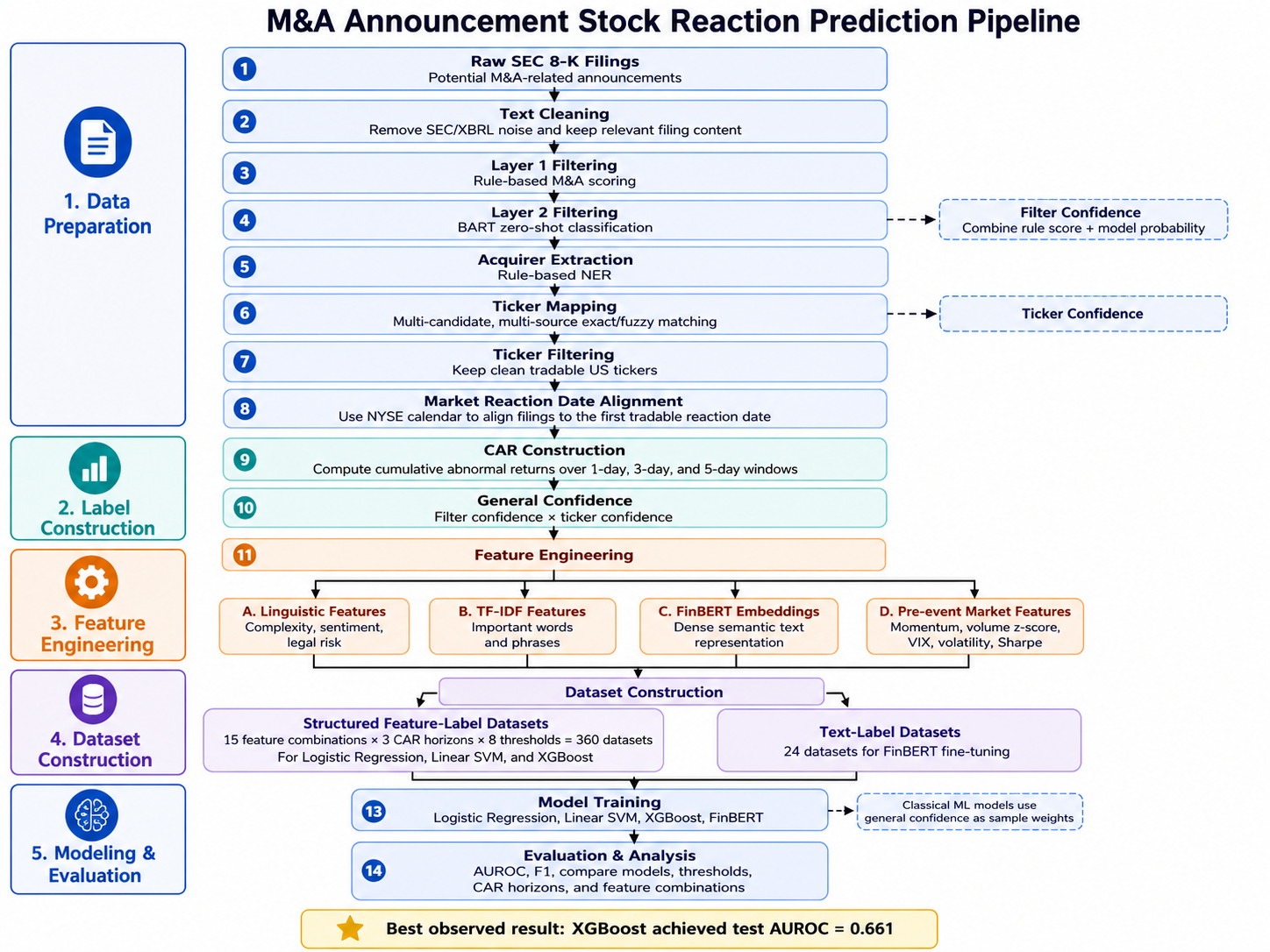
In our M&A announcement-effect prediction project, the hardest part of the entire data pipeline turned out not to be the model — it was the seemingly trivial task of turning a long legal filing into two basic fields: "the acquirer" and "its stock ticker."
What looks like a one-line problem is actually the place where the whole project is most likely to fall apart. This blog documents the obstacles we met when we matched from naive keywords to a multi-layered, multi-source, confidence-weighted solution.
Background: What We're Trying to Do
A quick follow-up to our previous blog 1: we ultimately decided to source M&A announcements from SEC EDGAR 8-K filings, thanks to their strong timeliness and material relevance. We will continue using yfinance.py to pull daily stock price data, as minute-by-minute intraday bar data from any provider remains cost-prohibitive. Our analysis will examine how M&A announcements affect the acquirer’s cumulative abnormal returns (CAR).
SEC 8-K filings are submitted by public companies to disclose material events — including M&A announcements. From these filings we intended to extract two things:
- NER (Named Entity Recognition): identify who is the acquirer;
- Ticker Mapping: convert that company name (public) into its stock ticker.
With these two steps, we can compute the acquirer's CAR, and therefore be able to construct the labels for our prediction task. Now to the story of how we actually got there.
Round 1: Naive Keyword Matching
⚠ PROBLEM 1 How do we extract "the acquirer's name" from thousands of words of legal text?
✓ FIRST ATTEMPT The most intuitive approach: regex patterns built around obvious keywords like
"acquired","merged with","to acquire X", capturing the company name on either side.
Our initial rule set looked something like this:
# Naive keyword matching (simplified)
patterns = [
r"([A-Z][\w\s,.&]+?)\s+acquired\s+([A-Z][\w\s,.&]+?)",
r"([A-Z][\w\s,.&]+?)\s+to acquire\s+([A-Z][\w\s,.&]+?)",
r"merger between\s+([A-Z][\w\s,.&]+?)\s+and\s+([A-Z][\w\s,.&]+?)",
]
⚠ NEW PROBLEM
These rules performed terribly. Three reasons: 1. Real-world phrasing is wildly diverse:
"completed its previously announced acquisition of...","became a wholly owned subsidiary of..."— you >can't enumerate them all; 2. Many filings use passive voice or describe the deal from the subsidiary's point of view; 3. The captured "company names" were often half-sentences or polluted with noise like "the Company" or "its parent."
Round 2: Exploiting the Structure of the Filing
✓ NEW APPROACH If the prose is too unpredictable, why not anchor on the fixed structure of the filing instead? Every 8-K opens with a standardized header that contains the line
(Exact name of registrant as specified in its charter), with the company name printed directly above it.
So we changed strategy: locate that anchor first, identify the "filer" (the company that submitted the filing), and walk a few lines upward to capture the name. Hit rate jumped immediately.
⚠ NEW PROBLEM But the problem isn't over — the filer isn't always the acquirer. In some M&A events, the 8-K is actually filed by the target. Treating the filer as the acquirer flips the label entirely.
Round 3: Leveraging SEC's Legal Labels
Fortunately, SEC filings follow a highly standardized legal style. Inside merger agreements, every party is given a quoted "role label":
"Acme Corporation, a Delaware corporation (\"Parent\")""NewCo Inc., a Delaware corporation (\"Merger Sub\")""TargetCo, Inc. (\"the Company\" or \"Target\")"
✓ KEY INSIGHT An entity tagged as
("Parent")or("Buyer")→ it's the acquirer. An entity tagged as("Target")or("Seller")→ it's the target. Combine that with the filer's identity and we can reliably infer the true acquirer, even when the target is the one filing.⚠ NEW PROBLEM Not all filings follow this convention. Older filings, smaller companies, or short announcements often skip the labeled-entity format entirely. We need a fallback.
Round 4: Multi-Level Fallback Patterns
✓ FALLBACK STRATEGY We wrote a series of regex patterns ordered from most reliable to weakest, tried in sequence, stopping at the first hit:
# Fallback regex patterns (ordered by signal strength)
fallback_patterns = [
r"([A-Z][\w\s&,]+?)\s+completed its acquisition of\s+([A-Z][\w\s&,]+)",
r"([A-Z][\w\s&,]+?)\s+completed the merger with\s+([A-Z][\w\s&,]+)",
r"to acquire\s+([A-Z][\w\s&,]+)", # filer assumed acquirer
r"by and among\s+(.+?)\s+and\s+(.+?)", # parse contracting parties
r"became a wholly owned subsidiary of\s+([A-Z][\w\s&,]+)",
r"wholly owned subsidiary of\s+([A-Z][\w\s&,]+)",
]
If everything fails, we fall back to the filer's name as a last resort — better than nothing, and the downstream confidence score will reflect the uncertainty.
⚠ NEW PROBLEM The names extracted by fallback regex are noisy: date fragments, SEC file numbers, person titles like "Chairman of the Board," role-only words like "Parent," and even broken sentence fragments such as "the company completed..."
Round 5: Aggressive Name Cleaning
✓ VALIDATION RULES We added a strict validation layer that rejects any candidate matching the following:
- Sentence fragments (lowercase start, contains verbs like "completed");
- Pure role words ("Parent", "Buyer", "the Company");
- SEC boilerplate ("date of report", "exact name of");
- Person titles ("Chairman", "Chief Executive Officer");
- Abnormal length (< 3 chars or > 100 chars);
- Excessive punctuation (more than 30% non-alphabetic).
At this point the NER module is essentially done. But ticker mapping is about to be its own iteration nightmare.
Round 6: Entering Ticker Mapping
⚠ PROBLEM 6 Now we have a clean acquirer name. How do we map it to a stock ticker? The most direct idea: download a local
company-tickerCSV and do exact lookups.✓ FIRST ATTEMPT Take a local mapping file with thousands of company → ticker pairs and run exact string matches against our extracted names.
⚠ NEW PROBLEM SEC filings use full legal entity names like
"Apple Inc."or"Berkshire Hathaway, Inc.", while the mapping might list them as"Apple"or"Berkshire Hathaway."Add in all the variations —"f/k/a","Class A Common Stock","Holdings","Corporation"— and exact matching collapses to around 30–40% recall.
Round 7: Fuzzy Matching + Candidate Generation
✓ IMPROVED APPROACH Two simultaneous moves:
- Generate name variants: strip suffixes ("Inc.", "Corp.", "Holdings"), strip security descriptions ("Class A", "Common Stock"), strip role words, split on commas, split on "former name" markers — producing up to 15 candidates;
- Fuzzy match each candidate: use
difflib.SequenceMatcherwith a 90% similarity threshold.
Each candidate carries its own candidate_confidence — more aggressive transformations get lower scores. The final ticker_confidence = method confidence × candidate confidence, which downstream becomes a component of sample weight in model training.
⚠ NEW PROBLEM Even with fuzzy matching, the local mapping is incomplete — especially for companies that changed names, SPAC mergers, or smaller entities never present in the mapping file. About 20% of filings still come away with no ticker.
Round 8: Multi-Source Cascade (Final Solution)
✓ FINAL DESIGN: 5-LEVEL CASCADE Chain together multiple data sources, starting from the fastest and most reliable, falling back to slower but broader sources only when needed. Each level produces its own confidence score.
| Level | Data Source | Match Method | Confidence |
|---|---|---|---|
| L1 | Local CSV | Exact match | ~0.96 |
| L2 | SEC official | Exact match | ~1.00 |
| L3 | Local CSV | Fuzzy match (≥90%) | 0.77 ~ 0.85 |
| L4 | SEC official | Fuzzy match (≥90%) | 0.80 ~ 0.90 |
| L5 | Yahoo Finance API | Online search + result validation | 0.76 ~ 0.86 |
# Definition of confidence for data source
if method == "SEC_EXACT":
base = 1.00
elif method == "LOCAL_EXACT":
base = 0.96
elif method == "SEC_FUZZY":
# sim 0.90 -> 0.80, sim 1.00 -> 0.90
base = 0.44 + 0.46 * sim_value
elif method == "LOCAL_FUZZY":
# sim 0.90 -> 0.765, sim 1.00 -> 0.85
base = 0.36 + 0.49 * sim_value
elif method == "YFINANCE_SEARCH":
# sim 0.88 -> 0.758, sim 1.00 -> 0.86
base = 0.18 + 0.68 * sim_value
else:
base = 0.0
The cascade short-circuits on first hit — Match the candidate with the highest confidence score in the most reliable dataset, keep rolling down until a match is found. Finally, a post-filter keeps only valid US tickers matching ^[A-Z]{1,5}$, removing foreign listings (which often contain "."), ETFs with long tickers, and malformed codes.
The Full NER + Ticker Mapping Pipeline
In the end, we dropped newsdata with an unfound acquirer name and ticker to ensure a low false positive rate.
Reflection: Why Keyword Matching Was Never the Endpoint
Looking back at the iteration path, every "problem → solution" cycle was essentially us fighting against the limitations of keyword matching:
- Naive regex keywords → poor recall;
- Structural anchors ("Exact name of registrant") → role confusion;
- SEC legal labels → labels often missing;
- Multi-level fallback regex → noisy names;
- Aggressive cleaning → tickers not found;
- Local exact matching → name variation problems;
- Fuzzy matching → incomplete database;
- Multi-source cascade + confidence weighting → finally striking a usable balance between coverage and accuracy.
Keyword matching as a standalone solution simply doesn't work — but when embedded inside a system with structure, fallbacks, and confidence scores, it becomes capable of stably processing filings effectively. That's what we ended up with. Every match carries a ticker_confidence, which downstream models consume as a component of sample weight. Less certain matches automatically get less influence on the model — instead of being thrown away, they contribute proportionally to how confident we are in them.
Takeaways
Three lessons we learned from this "deceptively simple" task:
- Don't start from keywords. Look first for the structural signals in the document — anchors, labels, signatures, fixed templates. They're far more reliable than prose.
- Separate "matching" from "confidence." Matching answers what is it; confidence answers how sure are we. Both must coexist, otherwise downstream consumers can't tell signal from noise.
- There's no silver bullet — only cascades. Single data sources, single rules, single thresholds will all fail. Chain together imperfect solutions, and coverage rises to a usable level.
Regarding the later stages…
Following NER processing and ticker mapping, we moved on to calculating cumulative abnormal returns (CAR), conducting feature engineering, and building our models. These stages went relatively smoothly with no major hurdles. We’ll dive into detailed explanations of each step in our upcoming report — stay tuned!