By Group "The Gold Diggers"
Introduction
In our first blog post, we walked through how we scraped over 6,400 financial news URLs, extracted 3,252 full articles, and packaged everything into fina2350_master_dataset_for_rag.csv — a file combining gold futures data with GARCH/GARCH-X volatility estimates and thematic text variables across Monetary, Fiscal, and Geopolitical categories.
That post was about getting data into a usable shape. This one is about what came next: making the narrative content actually interpretable through a knowledge graph retrieval system called LightRAG. Honestly, this part of the project gave us more headaches than the data pipeline did — mostly because we were running production-grade AI infrastructure on student budgets and M1 MacBooks.
Why LightRAG?
Our GARCH model handles the "how much" of gold volatility. What it can't tell you is why a particular week spiked. Was it the Fed signalling a rate hold? Safe-haven flows from a geopolitical event? ETF rebalancing? To get at those questions, we needed something that could reason across a large set of financial documents and give us answers grounded in actual source material.
That's where RAG (Retrieval-Augmented Generation) comes in. Instead of asking an LLM to recall facts from memory, a RAG system retrieves relevant text from a document store and uses that as context when generating a response. LightRAG takes it further by building a knowledge graph on top of the documents, extracting named entities (nodes) and relationships between them (edges). This means it can answer questions that require connecting ideas across multiple sources. A question like "How did Fed rate signals in late 2025 feed into gold ETF outflows in early 2026?" touches monetary policy, investor behaviour, and commodity markets simultaneously. A flat vector search struggles with that. A graph can traverse it.
The Model Problem
LightRAG recommends using an LLM with at least 32 billion parameters and a 32K token context window. The reason is practical: building a knowledge graph means the model has to read a long chunk of text, identify every relevant entity, infer the relationships between them, and output structured JSON. Smaller models keep dropping entities or producing malformed output mid-pipeline.
Our M1 MacBooks can realistically run models up to around 8B parameters through Ollama. We tested one and it failed exactly as the docs warned, incomplete extractions, broken relationship chains. We looked at Hugging Face, Google Gemini free tier which lacked rate limits, and local 32B+ deployment which we did not have enough unified memory on any machine.
What we ended up with was Ollama's cloud-hosted qwen3-vl:235b-cloud, a 235B model that runs on Ollama's servers but connects to our code as if it were local. It's free-tier, which turned out to be both the solution and the source of most of our problems.
How the System Is Wired Together
Three components run in parallel: the cloud LLM (qwen3-vl:235b-cloud) that builds the graph and answers queries, a local embedding model (bge-m3:latest) that converts text to vectors for semantic search, and a local reranker (bge-reranker-v2-m3) that scores retrieved chunks before they reach the LLM.
The initialisation code below wires these together. The trickiest part — one that cost us a debugging session — is the ollama_embed.func call. ollama_embed is already decorated to return an EmbeddingFunc object. Passing it directly into another EmbeddingFunc(func=...) double-wraps it and throws a runtime error. Using .func pulls out the raw callable before the decoration.
To reproduce this: install lightrag-hku, pull bge-m3:latest via Ollama, and set OLLAMA_API_KEY in your .env.
from lightrag import LightRAG
from lightrag.llm.ollama import ollama_model_complete, ollama_embed
from lightrag.utils import EmbeddingFunc
from functools import partial
import asyncio, os
async def initialize_rag():
rag = LightRAG(
working_dir="./gold_kb", # graph and vector store saved here
llm_model_func=ollama_model_complete,
llm_model_name=os.getenv("LLM_MODEL", "qwen3-vl:235b-cloud"),
summary_max_tokens=8192,
llm_model_kwargs={
"host": os.getenv("LLM_BINDING_HOST", None), # None = Ollama cloud
"options": {"num_ctx": 32768}, # 32K context minimum
"timeout": int(os.getenv("LLM_TIMEOUT", "600")), # 235B is slow
},
rerank_model_func=rerank_model_func,
embedding_func=EmbeddingFunc(
embedding_dim=1024,
max_token_size=8192,
func=partial(
ollama_embed.func, # .func avoids double EmbeddingFunc wrapping
embed_model="bge-m3:latest",
host="http://localhost:11434", # embedding runs locally
),
),
)
await rag.initialize_storages()
return rag
if __name__ == "__main__":
rag = asyncio.run(initialize_rag())
print("RAG system initialised successfully.")
Expected output on successful setup:
INFO: Initializing LightRAG with working_dir=./gold_kb
INFO: Storage initialized successfully
RAG system initialised successfully.
Testing with A Christmas Carol
Before throwing financial documents at it, we validated the pipeline on A Christmas Carol. Short, well-known, no domain knowledge required.
The story split into 42 chunks. Each chunk produced something like:
INFO: Chunk 22 of 42 extracted 14 Ent + 15 Rel
INFO: Chunk 23 of 42 extracted 12 Ent + 12 Rel
INFO: Chunk 25 of 42 extracted 24 Ent + 17 Rel
INFO: == LLM cache == saving: default:extract:c0f46ef9da55ba5e5f5f4158f37662da
Final graph: 40 entities, 210 relationships. We queried it in all four modes (Naive, Local, Global, Hybrid) and the differences were interesting. Local mode gave us Scrooge's personal arc. Global mode surfaced Dickens' broader social critique. Hybrid caught something neither found alone — the way the three-spirit structure explicitly links past, present, and future as a single moral argument.

Figure 1. Knowledge graph from A Christmas Carol. 40 nodes, 210 edges. Scrooge and Bob Cratchit are the largest nodes by degree centrality. The sparse, clearly-clustered structure confirmed entity extraction was working before we moved to the gold corpus.
Loading the Gold Corpus
We ended up with 30+ documents covering 2024–2026: WGC quarterly demand reports, Fed policy analyses, commodities outlooks, price forecast papers. Most ingested without issues, though we had to spread work across multiple sessions because the free-tier weekly quota doesn't cover a corpus this size in one go.
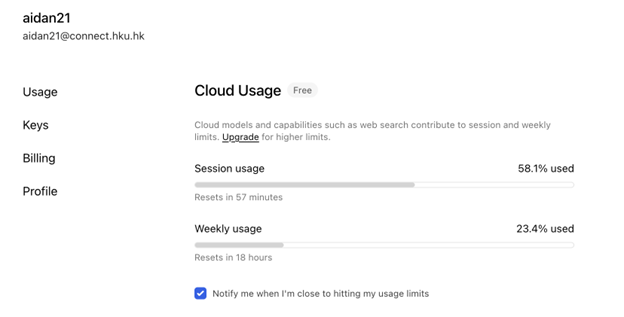
Figure 2. Ollama cloud usage partway through ingestion — 58.1% session, 23.4% weekly. We hit 100% weekly more than once before finishing.
The hardest document was fina2350_2026_dataset_for_rag.csv at 273 chunks. First attempt hit the session wall mid-way:
ERROR: you (aidan21) have reached your session usage limit,
upgrade for higher limits: https://ollama.com/upgrade
ERROR: Failed to extract document 1/1: fina2350_2026_dataset_for_rag.csv
INFO: Enqueued document processing pipeline stopped
What saved us is that LightRAG caches completed chunks to disk, so each resume after a quota reset picks up where it left off. After a few retry sessions it completed. We also tried a wider 2023–2026 dataset but dropped it — too quota-heavy given everything else we still needed to process.
Worth clarifying: GARCH is purely quantitative and has nothing to do with volatility bucketing. The RAG system handles the qualitative interpretation layer. For the CSV we also stripped out all numerical columns (the GARCH and GARCH-X series) and only fed in the narrative text fields — News_Context, Monetary, Fiscal, Geopolitics — since an LLM pipeline isn't going to extract meaningful graph entities from rows of floats.
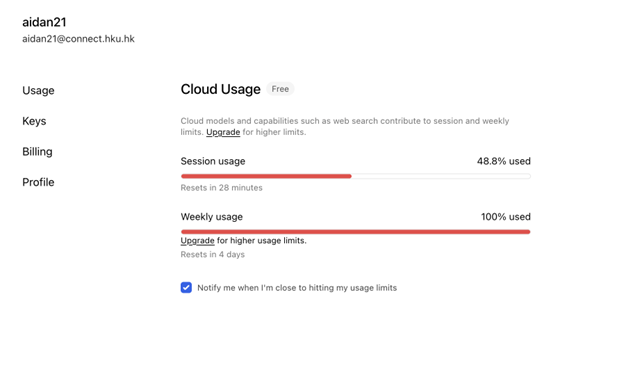
Figure 3. Weekly quota at 100% after completing the gold corpus. Not surprising — each of 273 chunks requires a full LLM round-trip to the cloud.
Below is what the resulting knowledge graph looks like compared to the Christmas Carol one.
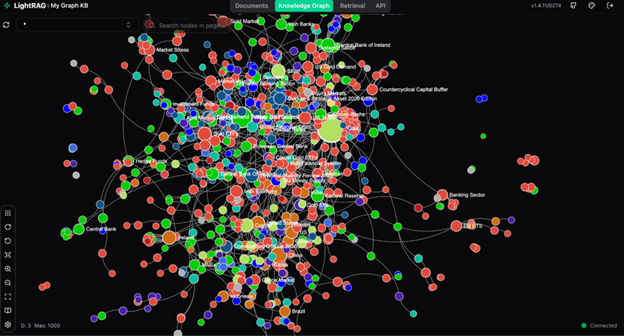
Figure 4. Full knowledge graph from the gold market corpus. The dense central cluster reflects heavily cross-referenced concepts: gold price, Fed policy, ETF flows.
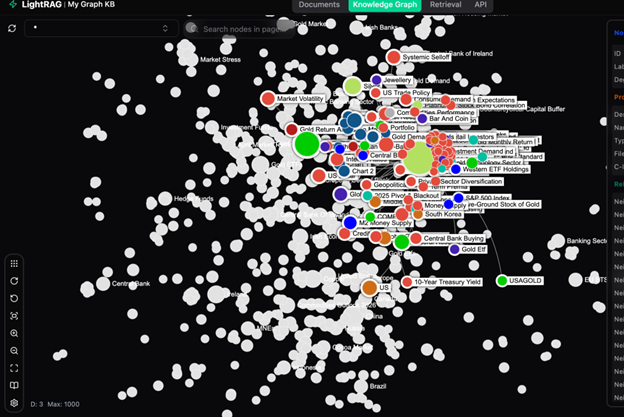
Figure 5. Zoomed labelled view. Visible nodes include Gold ETF, Central Bank Buying, 10-Year Treasury Yield, US Trade Policy — monetary, geopolitical, and demand-side concepts all in the same network.
What Went Wrong
VPN. Some of us use VPNs for other academic work. If it's active during ingestion, the Ollama cloud endpoint drops connections constantly:
C[1/1]: Post https://ollama.com:443/api/chat?ts=...: unexpected EOF (status code: -1)
ERROR: Failed to extract document 1/1: Financial_Stability_Review_2025_I.pdf
Took a while to figure out because it was intermittent. Fix: turn off the VPN entirely before running anything.
RAG-Anything. We looked into this multimodal parser because our PDFs have tables and charts that PyPDF2 ignores. It uses a component called MinerU for that. On M1 it immediately threw:
NotImplementedError: Output channels > 65536 not supported at the MPS device.
ERROR: Mineru command failed with return code 0
MinerU's neural parser exceeds the channel limit on Apple's Metal Performance Shaders backend. Known issue, no M1 fix currently. We stayed with PyPDF2 — fast and simple, but blind to tables and images, which is a limitation we acknowledge in the final report.

Figure 6. Parser comparison across the features we needed. RAG-Anything handles everything including formulas but failed on our hardware. PyPDF2 won by default.
A Sample Query
To see the full pipeline in action, we ran this in hybrid mode — which combines local entity-level search with global community-level summaries for the broadest possible context:
from lightrag import LightRAG, QueryParam
import asyncio
async def query_volatility(rag):
# hybrid = local (entity neighbours) + global (community summaries)
result = await rag.aquery(
"Imagine that there are 3 volatility buckets: low, medium, and high. "
"Could you fit February 2026 into one of the buckets?",
param=QueryParam(mode="hybrid")
)
return result
if __name__ == "__main__":
rag = asyncio.run(initialize_rag()) # uses initialize_rag() defined above
print(asyncio.run(query_volatility(rag)))
Retrieval log:
INFO: Local query: 40 entities, 210 relations
INFO: After truncation: 40 entities, 140 relations
INFO: Selecting 38 from 38 entity-related chunks by vector similarity
INFO: Final context: 40 entities, 140 relations, 13 chunks
The system came back with High Volatility for February 2026, citing the Fed's 9-to-3 split vote on the rate path, unemployment at 4.6%, gold's weakest Q1 since 2013, and precious metals intraday ranges running five times their 2025 average. None of that came from our GARCH model — it came from the documents.
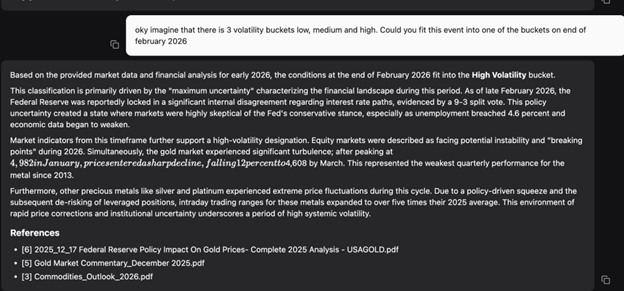
Figure 7. System output classifying February 2026 as High Volatility, drawing from multiple source documents connected through the knowledge graph.
Takeaways
Running production AI on a free tier teaches you things a paid setup wouldn't. The quota constraints forced us to think carefully about what the model actually needs, which led us to strip numerical columns from the CSV, a decision that turned out to be architecturally correct anyway.
Debugging was also a different kind of problem. A VPN rerouting traffic doesn't produce a clean stack trace. You form hypotheses and test them, which takes longer but leaves you with a much better understanding of what's actually happening under the hood.
The harder ongoing challenge is connecting the GARCH outputs and the RAG outputs. GARCH gives us the "when" and "how much"; the knowledge graph gives us the "why". Making them talk to each other coherently is its own problem, and that's what our final report will focus on.
Word count (excluding code and captions): approximately 1,700 words.
The Gold Diggers — FINA2350, The University of Hong Kong, Jan–May 2026